//TODO
Activiti6.0 – 子流程加签和减签 | 字痕随行
之前完成了加签和减签的功能,但是只是在普通多实例节点上测试了一下。趁着魔兽世界排队的功夫,我又测试了一下子流程,目前来看还算正常。
先看一下流程图,用的其实就是之前的流程,如下:
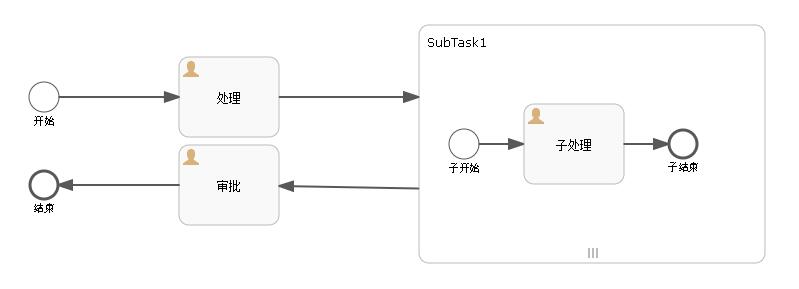
首先,加签。
启动流程,将流程流转至SubTask1,此时act_ru_task的数据如下:

此时,直接请求之前已经有的接口:
http://localhost:8080/activiti/flow/addExecution/SubTask1/167706/test004
这里需要注意的是,nodeId必须填写子流程的ID标识,而不能填写子流程内用户节点的ID标识。
请求接口后,act_ru_task的数据如下:

此时,加签成功,可以继续执行其它的操作。
其次,减签。
接着上面的流程,如果在加签之后,直接请求减签接口。在请求之前,先看一下act_ru_execution表内的数据:
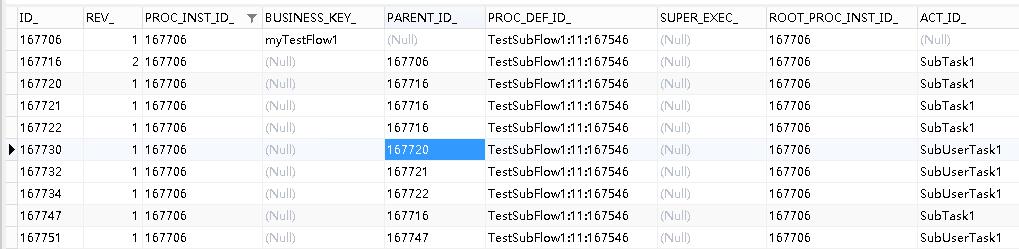
请求减签的接口,如下:
http://localhost:8080/activiti/flow/delExecution/167747/0
这里需要注意的是,excutionId需要填写的是SubTask1的ID标识,不要填写成SubUserTask1的ID标识,否则会报异常。所以上面的接口中会填写167747。
请求完毕后,查看act_ru_execution表内的数据,会发现SubTask1减少了一条记录:
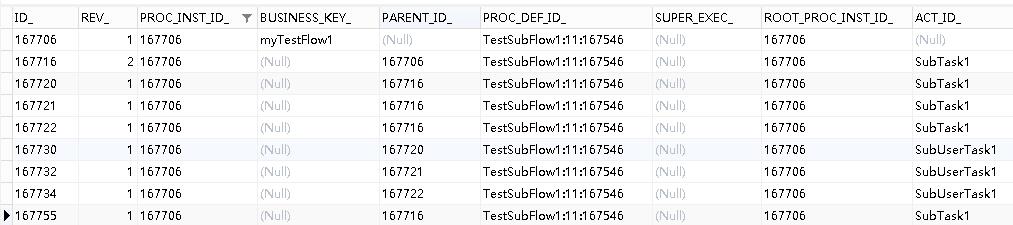
同时,act_ru_task的数据也减少了一条:

证明减签成功,此时可继续其它操作。
如果有问题,欢迎指正讨论。

觉的不错?可以关注我的公众号↑↑↑
Activiti6.0 – 加签 | 字痕随行
试验过了Flowable的加签和减签,并且简单分析了一下其源码之后,这次就来尝试一下实现基于Activiti6.0的加签功能。
Activiti6.0并没有提供加签的API接口,不过完全可以参照Flowable的源码来实现,甚至于有的接口照抄即可。
首先,找到AddMultiInstanceExecutionCmd这个命令所在的位置,如下图:
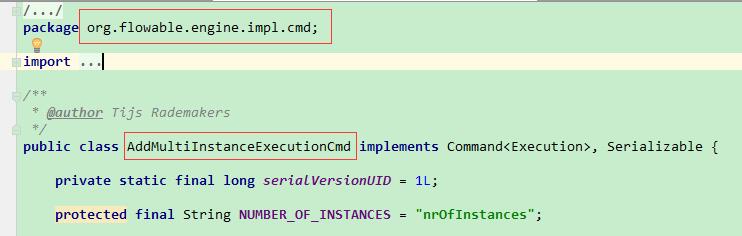
将这个类直接拷贝到Activiti的相关项目里,比如我这里的结构如下:
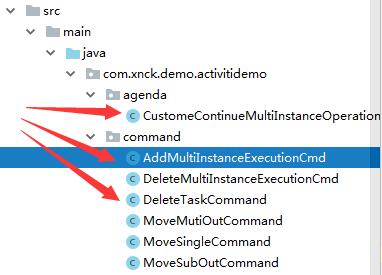
拷贝完后,进入编辑器,这个类会报一些错误:
1. CommandContextUtil在Activiti中不存在,不过可以直接改为使用CommandContext。
2. 在Activiti中需要去除一些有效性验证。
3. BpmnModel只能通过repositoryService来获得。
4. 最麻烦的是,Activiti中的planContinueMultiInstanceOperation和Flowable中的不一样,所以需要重新声明一个,如上图中,重新创建了一个CustomeContinueMultiInstanceOperation。
AddMultiInstanceExecutionCmd改造后的主要代码如下:
@Override
public Execution execute(CommandContext commandContext) {
ExecutionEntityManager executionEntityManager = commandContext.getExecutionEntityManager();
ExecutionEntity miExecution = searchForMultiInstanceActivity(activityId, parentExecutionId, executionEntityManager);
if (miExecution == null) {
throw new RuntimeException("No multi instance execution found for activity id " + activityId);
}
ExecutionEntity childExecution = executionEntityManager.createChildExecution(miExecution);
childExecution.setCurrentFlowElement(miExecution.getCurrentFlowElement());
BpmnModel bpmnModel = repositoryService.getBpmnModel(miExecution.getProcessDefinitionId());
Activity miActivityElement = (Activity) bpmnModel.getFlowElement(miExecution.getActivityId());
MultiInstanceLoopCharacteristics multiInstanceLoopCharacteristics = miActivityElement.getLoopCharacteristics();
Integer currentNumberOfInstances = (Integer) miExecution.getVariable(NUMBER_OF_INSTANCES);
miExecution.setVariableLocal(NUMBER_OF_INSTANCES, currentNumberOfInstances + 1);
if (executionVariables != null) {
childExecution.setVariablesLocal(executionVariables);
}
if (!multiInstanceLoopCharacteristics.isSequential()) {
miExecution.setActive(true);
miExecution.setScope(false);
childExecution.setCurrentFlowElement(miActivityElement);
commandContext.getAgenda().planOperation(new CustomeContinueMultiInstanceOperation(commandContext, childExecution, miExecution, currentNumberOfInstances));
}
return childExecution;
}
CustomeContinueMultiInstanceOperation没什么改动,只需要改动一下命名空间,基本上就可以直接使用。
最后,在Controller中创建一个方法,接收请求,测试即可:
/**
* 增加流程执行实例
* @param nodeId
* @param proInstId
* @param assigneeStr 以逗号隔开的字符串
*/
@RequestMapping(value = "addExecution/{nodeId}/{proInstId}/{assignees}")
public void addExecution(@PathVariable("nodeId") String nodeId,
@PathVariable("proInstId") String proInstId,
@PathVariable("assignees") String assigneeStr) {
String[] assignees = assigneeStr.split(",");
for (String assignee : assignees) {
managementService.executeCommand(
new AddMultiInstanceExecutionCmd(
nodeId, proInstId, Collections.singletonMap("assignee", (Object) assignee))
);
}
}
下一次再试试Activiti6.0的减签,以上,如有问题,欢迎讨论指正。
觉的不错?可以关注我的公众号↑↑↑
Activiti6.0 – 多实例节点跳转 | 字痕随行
最近都在试验Activiti6.0的节点跳转,其它的文章见索引。
本次就试验一下在Activiti6.0的一个流程内,由多实例节点跳转至其它的用户节点。
首先,仍旧是先上流程图:
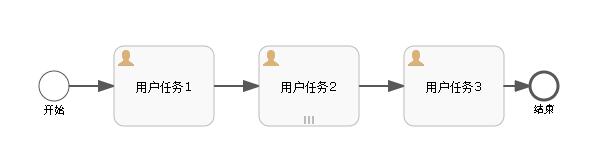
上图中,用户任务1和用户任务3是普通的用户节点,用户任务2是多实例节点。
当流程处于节点“用户任务1”时,数据表中的记录如下图:

act_ru_task

act_ru_execution

act_ru_variable
对比一下,当流程处于节点“用户任务2”时,数据库表中的记录如下图:

act_ru_task

act_ru_execution
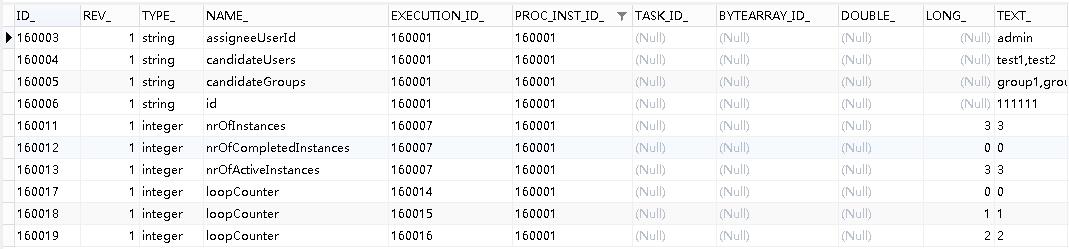
act_ru_variable
同样的思路,当从多实例节点向普通用户节点跳转时,只需要清除Task记录、Execution记录和相关的Variable记录。
这里需要注意,与子流程节点跳转不同,act_ru_execution中的字段SUPER_EXEC_并没有值,所以只需要删除掉Task所属的Execution即可,即表中的ID_ IN ('160014', '160015', '160016')。
还需要注意,因为进入多实例节点后,有一些特殊的参数产生,如:nrOfInstances、nrOfCompletedInstances、nrOfActiveInstances,这些参数也需要删除掉,以避免流程的后续操作产生异常。
具体的代码如下:
/**
* 移出多实例节点至父流程
*/
public class MoveMutiOutCommand implements Command<Object> {
private String currentTaskId;
private String targetNodeId;
public MoveMutiOutCommand(String currentTaskId, String targetNodeId) {
this.currentTaskId = currentTaskId;
this.targetNodeId = targetNodeId;
}
public String getCurrentTaskId() {
return currentTaskId;
}
public void setCurrentTaskId(String currentTaskId) {
this.currentTaskId = currentTaskId;
}
public String getTargetNodeId() {
return targetNodeId;
}
public void setTargetNodeId(String targetNodeId) {
this.targetNodeId = targetNodeId;
}
@Override
public Object execute(CommandContext commandContext) {
//获得用到的Manager
ExecutionEntityManager executionEntityManager = commandContext.getExecutionEntityManager();
TaskEntityManager taskEntityManager = commandContext.getTaskEntityManager();
IdentityLinkEntityManager identityLinkEntityManager = commandContext.getIdentityLinkEntityManager();
VariableInstanceEntityManager variableInstanceEntityManager = commandContext.getVariableInstanceEntityManager();
//获得当前流程处于的Task信息
TaskEntity taskEntity = taskEntityManager.findById(this.currentTaskId);
//获得流程实例信息
ExecutionEntity executionEntity = executionEntityManager.findById(taskEntity.getExecutionId());
ExecutionEntity parentExecutionEntity = executionEntityManager.findById(executionEntity.getParentId());
List<ExecutionEntity> childExecutionEntities = executionEntityManager.findChildExecutionsByParentExecutionId(parentExecutionEntity.getId());
//设置需要删除参数的流程实例
Set<String> executionIds = new HashSet<>();
executionIds.add(parentExecutionEntity.getId());
for (ExecutionEntity childExecutionEntity : childExecutionEntities) {
executionIds.add(childExecutionEntity.getId());
}
//获得流程定义信息
Process process = ProcessDefinitionUtil.getProcess(executionEntity.getProcessDefinitionId());
//删相关的办理人
identityLinkEntityManager.deleteIdentityLink(executionEntity, null, null, null);
identityLinkEntityManager.deleteIdentityLink(parentExecutionEntity, null, null, null);
//删相关的参数
List<VariableInstanceEntity> variableInstanceEntities = variableInstanceEntityManager.findVariableInstancesByExecutionIds(executionIds);
for (VariableInstanceEntity variableInstanceEntity : variableInstanceEntities) {
variableInstanceEntityManager.delete(variableInstanceEntity, true);
}
//删Task
taskEntityManager.deleteTasksByProcessInstanceId(taskEntity.getProcessInstanceId(), "测试删除子节点", true);
//删子流程的流程实例
executionEntityManager.deleteChildExecutions(parentExecutionEntity, "", true);
//移动节点
FlowElement targetFlowElement = process.getFlowElement(targetNodeId);
parentExecutionEntity.setCurrentFlowElement(targetFlowElement);
ActivitiEngineAgenda agenda = commandContext.getAgenda();
agenda.planContinueProcessInCompensation(parentExecutionEntity);
return null;
}
}
请求一下地址,触发此命令:
http://localhost:8080/activiti/flow/moveMutiOut/160021/UserTask1
查询一下数据库,可以确认节点已经完成跳转:

act_ru_task

act_ru_execution
至此,关于Activiti6.0节点跳转的试验已经全部完成,如果有遗漏的,以后用到或者想到的时候再补充。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Activiti6.0 – 子流程节点跳转 | 字痕随行
上一篇中介绍了如何在一个简单的流程中,实现节点的自由跳转。正常的流程肯定不会如此简单,本篇就介绍一下如何实现子流程的节点跳转。
内嵌子流程其实使用上一篇中介绍的方法就可以实现,因为从本质上来说,内嵌子流程并没有脱离父流程,仍旧属于它不可分割的一部分。
本篇着重介绍的如何实现调用子流程的节点跳转,主要介绍一下如何从子流程内的节点跳出到父流程节点。流程在进入调用子流程这部分后,会新生成一个流程实例,这就使得调用子流程的节点跳转和上一篇中所实现的逻辑有本质不同。
先上流程图:
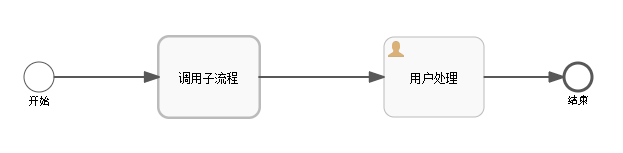
如果处于父流程中的节点,act_ru_execution中的记录为:

进入子流程后,act_ru_execution中的记录会变为4条,会为子流程新创建一个流程实例:

所以,由子流程中的节点移动至父流程中的节点时,实现的思路如下:
1. 通过当前的TaskId找到所属的子流程实例,即图中的ID_=157577。为了方便说明,此流程实例暂时使用execution指代。
2. 通过execution查找其父流程,即图中的ID_=157573,此流程实例暂时使用parentExecution指代。
3. 通过parentExecution查找其Super流程,即图中的ID_=157551,此流程实例暂时使用rootExecution指代。
4. 按照上一篇中的实现逻辑,删除当前的Task记录,并且清除与其相关的流程实例execution、parentExecution及其它的附加信息(办理人、Variable)。
5. 在rootExecution上,将流程节点跳转至指定的节点。
完整的实现代码如下:
/**
* 移出子节点至父流程
*/
public class MoveSubOutCommand implements Command<Object> {
private String currentTaskId;
private String targetNodeId;
public MoveSubOutCommand(String currentTaskId, String targetNodeId) {
this.currentTaskId = currentTaskId;
this.targetNodeId = targetNodeId;
}
public String getCurrentTaskId() {
return currentTaskId;
}
public void setCurrentTaskId(String currentTaskId) {
this.currentTaskId = currentTaskId;
}
public String getTargetNodeId() {
return targetNodeId;
}
public void setTargetNodeId(String targetNodeId) {
this.targetNodeId = targetNodeId;
}
@Override
public Object execute(CommandContext commandContext) {
//获得用到的Manager
ExecutionEntityManager executionEntityManager = commandContext.getExecutionEntityManager();
TaskEntityManager taskEntityManager = commandContext.getTaskEntityManager();
IdentityLinkEntityManager identityLinkEntityManager = commandContext.getIdentityLinkEntityManager();
VariableInstanceEntityManager variableInstanceEntityManager = commandContext.getVariableInstanceEntityManager();
//获得当前流程处于的Task信息
TaskEntity taskEntity = taskEntityManager.findById(this.currentTaskId);
//获得流程实例信息
ExecutionEntity executionEntity = executionEntityManager.findById(taskEntity.getExecutionId());
ExecutionEntity parentExecutionEntity = executionEntityManager.findById(executionEntity.getParentId());
ExecutionEntity rootExecutionEntity = executionEntityManager.findById(parentExecutionEntity.getSuperExecutionId());
//获得流程定义信息
Process process = ProcessDefinitionUtil.getProcess(executionEntity.getProcessDefinitionId());
//删相关的办理人
identityLinkEntityManager.deleteIdentityLink(executionEntity, null, null, null);
identityLinkEntityManager.deleteIdentityLink(parentExecutionEntity, null, null, null);
//删相关的参数
List<VariableInstanceEntity> variableInstanceEntities = variableInstanceEntityManager.findVariableInstancesByExecutionId(parentExecutionEntity.getId());
for (VariableInstanceEntity variableInstanceEntity : variableInstanceEntities) {
variableInstanceEntityManager.delete(variableInstanceEntity, true);
}
//删Task
taskEntityManager.deleteTask(taskEntity, "测试删除子节点", true, true);
//删子流程的流程实例
executionEntityManager.deleteChildExecutions(parentExecutionEntity, "", true);
executionEntityManager.delete(parentExecutionEntity, true);
//移动节点
FlowElement targetFlowElement = process.getFlowElement(targetNodeId);
rootExecutionEntity.setCurrentFlowElement(targetFlowElement);
ActivitiEngineAgenda agenda = commandContext.getAgenda();
agenda.planContinueProcessInCompensation(rootExecutionEntity);
return null;
}
}
测试一下,请求如下地址:
http://localhost:8080/activiti/flow/moveSubOut/157528/UserTask1
跳转至父流程的UserTask1节点:

act_ru_task

act_ru_execution
在之后应该还有一篇,来实现一下,如何完成多实例节点的跳转。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Activiti6.0 – 节点跳转 | 字痕随行
之前一直在试验Flowable的节点跳转,可以参见以下文章:
但是,Activiti并没有这些API接口,那么应该如何实现呢?接下来就实现一下简单流程节点的跳转。
首先,本文是基于Command接口实现,关于Activiti中的Command会在之后的文章中详解一下,本篇文章就暂时只是说明如何实现、使用。
先上流程图,如下:
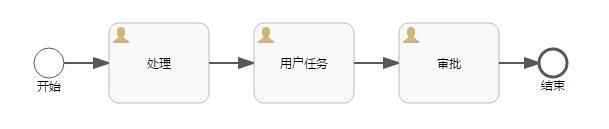
非常简单的一个流程,只包含开始、结束和三个用户节点。这样的流程在正常流转时,会在表act_ru_execution内生成两条数据:

在表act_ru_task内生成一条数据:

并且,在流程的流转过程中,基本保持不变:

D_没有变化,只有ACT_ID_有所变化

ID_和TASK_DEF_KEY_有变化,所属EXECUTION_ID_无变化
所以,只需要删除掉act_ru_task表中的数据,然后让流程向指定节点流转即可。
此时,就需要利用Command接口实现,具体的代码如下:
/**
* 移动节点命令
*/
public class MoveSingleCommand implements Command<Object> {
/**
* 当前TaskId
*/
private String currentTaskId;
/**
* 目标流程定义节点Id
*/
private String targetNodeId;
public MoveSingleCommand(String currentTaskId, String targetNodeId) {
this.currentTaskId = currentTaskId;
this.targetNodeId = targetNodeId;
}
public String getCurrentTaskId() {
return currentTaskId;
}
public void setCurrentTaskId(String currentTaskId) {
this.currentTaskId = currentTaskId;
}
public String getTargetNodeId() {
return targetNodeId;
}
public void setTargetNodeId(String targetNodeId) {
this.targetNodeId = targetNodeId;
}
@Override
public Object execute(CommandContext commandContext) {
ExecutionEntityManager executionEntityManager = commandContext.getExecutionEntityManager();
TaskEntityManager taskEntityManager = commandContext.getTaskEntityManager();
TaskEntity taskEntity = taskEntityManager.findById(this.currentTaskId);
ExecutionEntity executionEntity = executionEntityManager.findById(taskEntity.getExecutionId());
Process process = ProcessDefinitionUtil.getProcess(executionEntity.getProcessDefinitionId());
taskEntityManager.deleteTask(taskEntity, "移动节点", true, true);
FlowElement targetFlowElement = process.getFlowElement(targetNodeId);
executionEntity.setCurrentFlowElement(targetFlowElement);
ActivitiEngineAgenda agenda = commandContext.getAgenda();
agenda.planContinueProcessInCompensation(executionEntity);
return null;
}
}
然后开放一个Url地址执行此Command即可,代码如下:
/**
* 移动节点
*/
@RequestMapping(value = "move/{taskId}/{toNodeId}")
public void move(@PathVariable("taskId") String taskId,
@PathVariable("toNodeId") String toNodeId) {
managementService.executeCommand(new MoveSingleCommand(taskId, toNodeId));
}
链接地址示例:
http://localhost:8080/activiti/flow/move/150085/UserTask1
可以看到节点由UserTask2回退至UserTask1:

如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Activiti6.0 – 子流程的传参 | 字痕随行
子流程的传参仅仅限于调用子流程(Call activity),因为调用子流程试用的是外部已有的流程,相当于重新生成了一个流程实例。
如果在上一次文章中的Flow002内声明了变量,比如声明了Assignments变量,如下图:
Flow002内UserTask1的Assignments
如果将Flow002作为子流程调用,会直接抛出异常,如下:
HTTP Status 500 - Request processing failed; nested exception is org.activiti.engine.ActivitiException: Unknown property used in expression: ${assigneeUserId}
意思就是使用了未知的属性${assigneeUserId},要解决这个问题,就需要设置调用子流程的入参和出参,步骤如下:

设置入参和出参
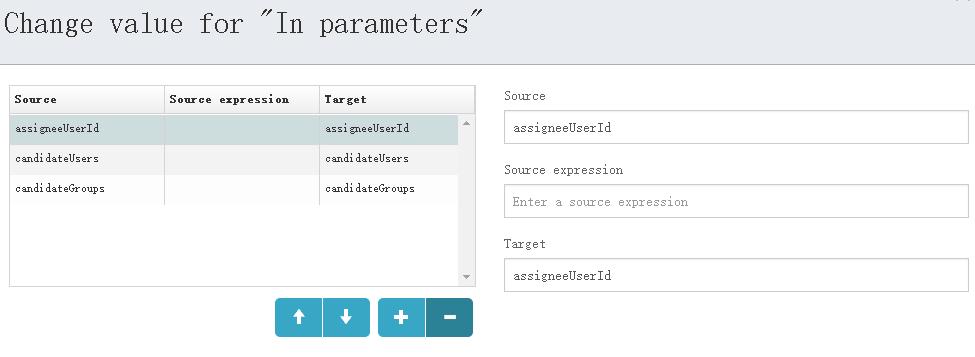
此处以入参为例
设置完毕后,启动时设置以上参数:
//设置办理人、候选人、候选组
map.put("assigneeUserId", "admin");
map.put("candidateUsers", "test1,test2");
map.put("candidateGroups", "group1,group2");
再次运行,启动成功,此时查看数据库,会发现:

流程实例

流程任务(节点)

流程参数
以下是引自Activiti5用户手册的相关内容:
可以把流程变量传递给子流程,反之亦然。当流程启动的时候,数据会复制给子流程。 在流程结束的时候,数据会复制回主流程。
我们可以使用activiti扩展来简化BPMN标准元素调用:
_dataInputAssociation_和 dataOutputAssociation。
这种简化方式只有在你使用BPMN 2.0标准方式声明流程变量时才会生效。
以下是BPMN的XML片段:
<callActivity id="callSubProcess" calledElement="checkCreditProcess" >
<extensionElements>
<activiti:in source="someVariableInMainProcess" target="nameOfVariableInSubProcess" />
<activiti:out source="someVariableInSubProcss" target="nameOfVariableInMainProcess" />
</extensionElements>
</callActivity>
也可以使用表达式:
<callActivity id="callSubProcess" calledElement="checkCreditProcess" >
<extensionElements>
<activiti:in sourceExpression="${x+5}" target="y" />
<activiti:out source="${y+5}" target="z" />
</extensionElements>
</callActivity>
当子流程执行完毕时,最后的结果为::z = y + 5 = x + 5 + 5。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Activiti6.0 – 子流程 | 字痕随行
简单试验一下子流程,主要是以下两种:
1. 内嵌子流程:内嵌在父流程中,外部无法访问。
2. 调用子流程:引用外部的已存在的流程,增加了流程的复用性。
首先,试验一下内嵌子流程。
以下是流程的截图,很简单的一个流程:
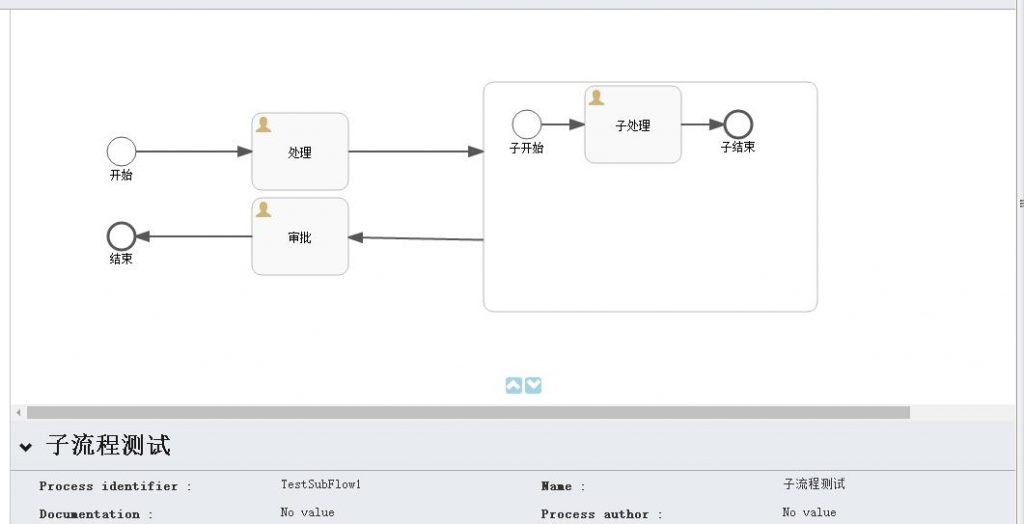
启动该流程,观察一下在进入到“子处理”这个节点时发生了什么?

会发现只有一个流程实例在运行,这说明,内嵌子流程和其父流程运行在同一个流程实例下。
然后,再试验一下调用子流程。
也创建一个简单的流程,如下图:
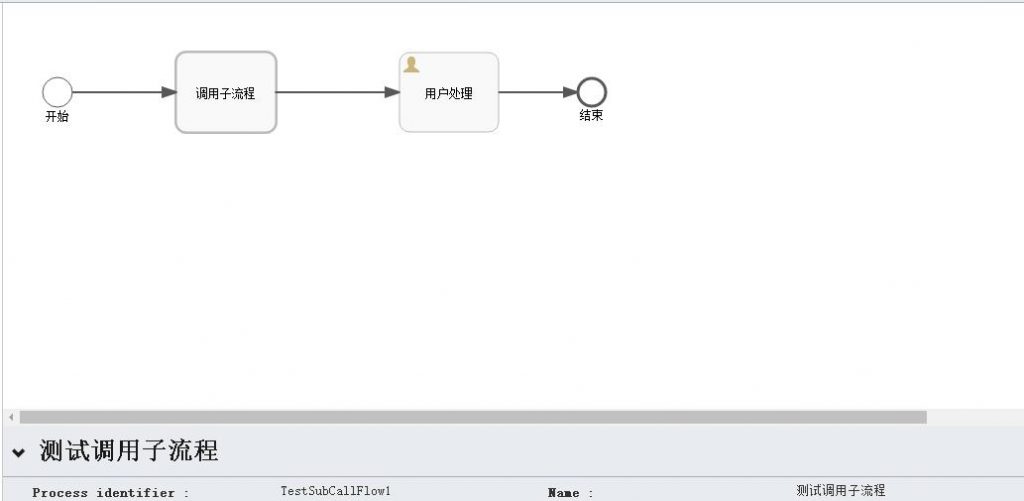
需要注意的是,调用子流程需要指定它调用的目标流程,这里我使用了之前的测试流程,如下图:
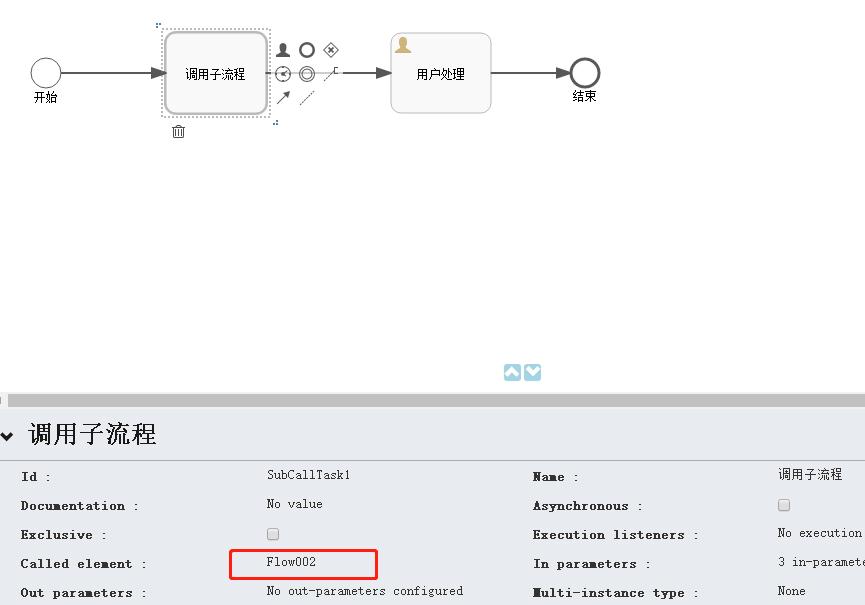
调用子流程设置
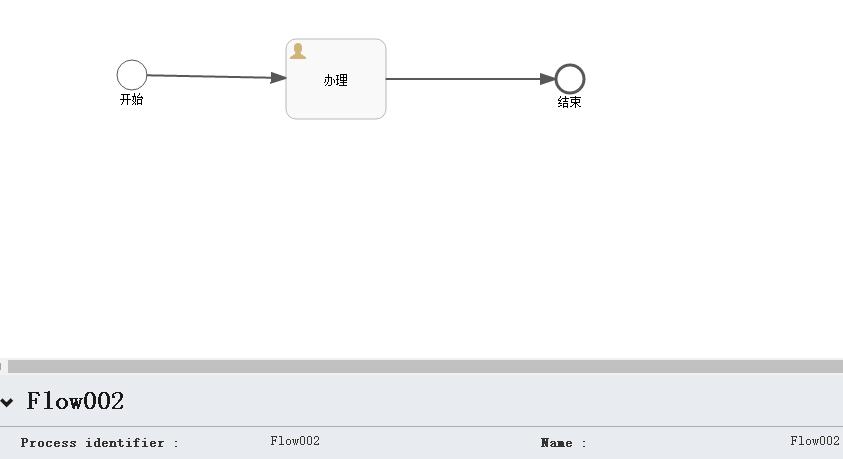
被调用的流程Flow002
启动该流程,观察一下在进入到“子处理”这个节点时会发生什么?

会看到上图中生成了两个流程实例,所以调用子流程在进入子流程节点后,会单独启动一个流程实例,用来运行子流程。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Activiti6.0 – 多实例 | 字痕随行
以下引自Activiti开发手册:
多实例节点是在业务流程中定义重复环节的一个方法。 从开发角度讲,多实例和循环是一样的: 它可以根据给定的集合,为每个元素执行一个环节甚至一个完整的子流程, 既可以顺序依次执行也可以并发同步执行。
本文以子流程为例,试验一下如何实现多实例子流程。
首先,还是使用之前的流程图,如下:
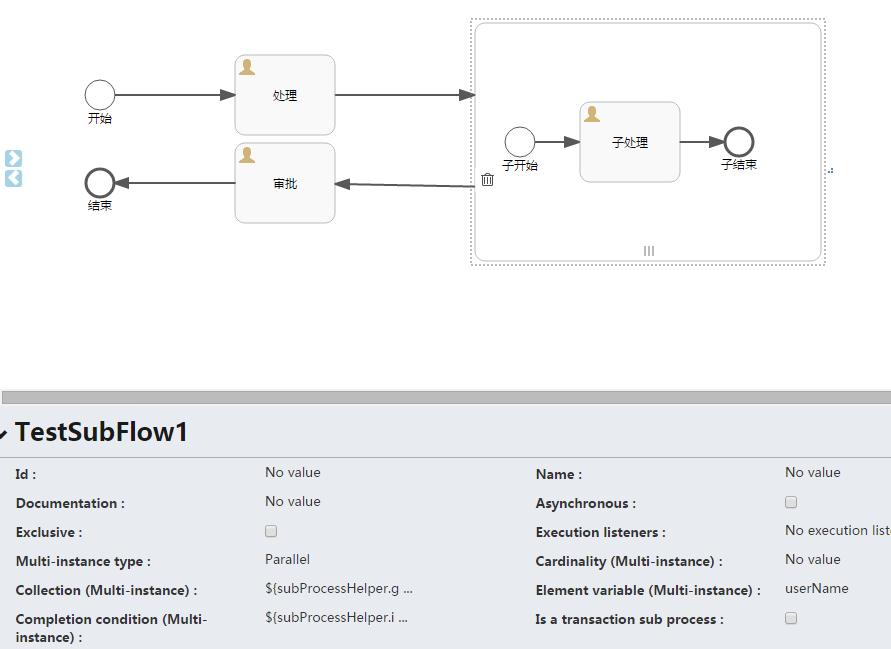
上图中需要注意以下几个属性:
Multi-instance type : 流程是串行还是并行,Parallel代表并行,Sequential代表串行。
Collection (Multi-instance) : 指定一个集合,对于集合中的每个元素,都会创建一个实例。
Element variable (Multi-instance) : 声明一个变量,此变量会包含集合(Collection)中的对应元素。
Completion condition (Multi-instance) : 结束条件,在此指定的表达式会在每个实例结束时执行。 如果表达式返回true,所有其他的实例都会销毁,多实例节点也会结束,流程会继续执行。
在上图中,SubProcessHelper是一个辅助的类,并在Spring中初始化,主要的代码如下:
public class SubProcessHelperImpl implements SubProcessHelper {
@Override
public List<String> getUserNames() {
List<String> userNames = new ArrayList<>();
userNames.add("test001");
userNames.add("test002");
userNames.add("test003");
return userNames;
}
@Override
public boolean isComplete(DelegateExecution execution) {
return true;
}
}
如此定义,子流程会生成3个实例,并且会在子流程的第一个实例运行完毕时,整个流程进入到“审批”节点。
多实例还有3个参数需要注意:
**nrOfInstances:**实例总数
**nrOfActiveInstances:**当前活动的实例数量。 对于顺序执行的多实例,值一直为1。
**nrOfCompletedInstances:**已经完成实例的数目。
如果将上面的代码修改为:
public class SubProcessHelperImpl implements SubProcessHelper {
@Override
public List<String> getUserNames() {
List<String> userNames = new ArrayList<>();
userNames.add("test001");
userNames.add("test002");
userNames.add("test003");
return userNames;
}
@Override
public boolean isComplete(DelegateExecution execution) {
Integer completeInstCount = (Integer) execution.getVariable("nrOfCompletedInstances");
Integer instCount = (Integer) execution.getVariable("nrOfInstances");
return completeInstCount > 1;
}
}
整个流程会在子流程的第二个实例运行完毕时,进入到“审批”节点。
再次引用****Activiti开发手册中的内容:
多实例其实是在一个普通的节点上添加了额外的属性定义,这样运行时节点就会执行多次。 下面的节点都可以成为一个多实例节点:
User Task
Script Task
Java Service Task
Web Service Task
Business Rule Task
Email Task
Manual Task
Receive Task
(Embedded) Sub-Process
Call Activity
主要注意的是:网关和事件不能设置多实例。
每个创建的分支都会有分支级别的本地变量(其他实例不可见,不会保存到流程实例级别):
**loopCounter:**表示特定实例的在循环的索引值。可以使用activiti的elementIndexVariable属性修改loopCounter的变量名。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
整合Activiti6.0流程设计器 | 字痕随行
最近一个多月都在尝试了解Activiti6.0,趁着放假整合编辑器这件事情终于有了些眉目,到此可以总结一下了。
第一步:下载源码
整合的时候肯定要从源码拷贝一些东西,有些问题出现的时候,源码也是非常有效的参考资料,所以要去Github下载源码到本地。
第二步:新建项目
建立个SpringMVC项目,如下图:
第三步:拷贝文件
新建一个文件夹,我这里是“activiti”,然后将Activiti源码中的editor文件夹全部拷贝过来(该文件夹位于\modules\activiti-ui\activiti-app\src\main\webapp内)。如下图:
将所缺失的JS、CSS等静态文件,从Activiti的源工程内拷贝到我们新建的工程,最终的工程如下:
第三步:修改JS
直接运行,我这里的RequestContextRoot为:
localhost:8080/activiti
直接访问地址localhost:8080/activiti/activiti/editor/index.html,在浏览器的调试器内肯定会报一堆错误,解决的步骤如下:
1. 将\activiti\scripts\app-cfg.js内的路径设置为当前值。
ACTIVITI.CONFIG = {
'onPremise' : true,
//远程请求根地址
'contextRoot' : '/activiti',
//web目录根地址
'webContextRoot' : '/activiti/activiti'
};
2. 先将app.js里面的“$routeProvider.otherwise”部分注释掉,替换为(为了显示一些隐藏的错误):
$routeProvider.otherwise({
templateUrl: appResourceRoot + 'editor-app/editor.html',
controller: 'EditorController'
});
3. 将url-config.js替换为以下内容:
KISBPM.URL = {
getModel: function(modelId) {
return ACTIVITI.CONFIG.contextRoot + '/app/rest/models/' + modelId + '/editor/json?version=' + Date.now();
},
getStencilSet: function() {
return ACTIVITI.CONFIG.webContextRoot + '/editor/editor-app/stencilset.json';
},
putModel: function(modelId) {
return ACTIVITI.CONFIG.contextRoot + '/app/rest/models/' + modelId + '/editor/json';
},
newModelInfo: function () {
return ACTIVITI.CONFIG.contextRoot + '/app/rest/models/';
}
};
4. 找一个stencilset.json文件放到指定的位置。我从"咖啡兔"的开源工程里直接拷贝了一份,其实也可以运行Activiti6的Release War包,然后在开发者工具里面找到对应的地址,然后拷贝一份。
5. 替换oryx.js里面stencilset.json的地址。
6. 在editor-controller.js的fetchModel()内的access方法内增加一行代码:
$rootScope.account = angular.toJson("{\"login\":\"admin\"}");
第四步:增加Controller文件
在工程内新增加一个Controller,我这里的名为“ActivitiAppRest”,主要的代码如下:
@RestController
@RequestMapping("/app/rest/")
public class ActivitiAppRest {
/**
* 身份认证
*/
@RequestMapping("authenticate")
public Map<String, Object> getAuthenticate() {
Map<String, Object> map = new HashMap<String, Object>();
map.put("login", "admin");
return map;
}
/**
* 账号信息
*/
@RequestMapping("account")
public Map<String, Object> getAccount() {
Map<String, Object> map = new HashMap<String, Object>();
map.put("email", "admin");
map.put("firstName", "My");
map.put("fullName", "Administrator");
map.put("id", "admin");
map.put("lastName", "Administrator");
Map<String, Object> groupMap = new HashMap<String, Object>();
map.put("id", "ROLE_ADMIN");
map.put("name", "Superusers");
map.put("type", "security-role");
List<Map<String, Object>> groups = new ArrayList<Map<String, Object>>();
groups.add(groupMap);
map.put("groups", groups);
return map;
}
/**
* 初始化
*/
@RequestMapping("models")
public ObjectNode getModels() {
Map<String, Object> map = new HashMap<String, Object>();
String jsonStr = "{\"modelId\":\"9dd84f5d-e9ed-44fa-b328-c7646efd766e\",\"name\":\"TEST1\",\"key\":\"TEST\",\"description\":\"\",\"lastUpdated\":\"2019-01-20T15:14:43.200+0000\",\"lastUpdatedBy\":\"admin\",\"model\":{\"id\":\"canvas\",\"resourceId\":\"canvas\",\"stencilset\":{\"namespace\":\"http://b3mn.org/stencilset/bpmn2.0#\"},\"properties\":{\"process_id\":\"TEST\",\"name\":\"TEST1\"},\"childShapes\":[{\"bounds\":{\"lowerRight\":{\"x\":130,\"y\":193},\"upperLeft\":{\"x\":100,\"y\":163}},\"childShapes\":[],\"dockers\":[],\"outgoing\":[],\"resourceId\":\"startEvent1\",\"stencil\":{\"id\":\"StartNoneEvent\"}}],\"modelType\":\"model\"}}";
JSONObject jsonObject = JSONObject.parseObject(jsonStr);
return jsonObject;
}
}
第五步:启动运行
以上都修改完成以后,就可以启动运行了,直接在地址栏输入:
http://localhost:8080/activiti/activiti/editor/index.html#/editor
这只是可以顺利显示静态页面,如果希望能够"创建/修改"流程信息,还需要引入Activiti Jar包,然后修改一下Controller里面的逻辑,稍后会继续讲解。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
整合Activiti6.0流程设计器-编辑保存 | 字痕随行
紧接着上一篇,我们来看一下怎么能够保存和发布已经设计好的流程。
先注意一下两个即将用到的类:
1、RepositoryService:Activiti的七大接口之一,主要作用是管理流程仓库,例如部署,删除,读取流程资源等。
2、ObjectMapper:Jackson库的主要类。它提供一些功能,能够将Java对象转换成匹配的JSON结构,反之亦然。
运行一下上一篇已经构建好的工程,随便在设计器上画一个流程,点击保存按钮,输入Model的名称和关键字,然后提交,在开发者工具里面跟踪一下,会发现提交的地址:
http://localhost:8080/activiti/app/rest/models/null/editor/json
再查看一下EditorController的源码,我们会发现需要注意以下路径:
1、创建时:
/app/rest/models/
2、编辑时:
GET: /app/rest/models/' + modelId + '/editor/json
3、保存时:
POST: /app/rest/models/' + modelId + '/editor/json
相对应的,在ActivitiAppRest内也需要接收页面的请求。
创建时,所需要的Controller方法实现比较简单,参考第一篇内静态的Json就可以实现,这里注意的是需要使用RepositoryService提供的newModel()获得一个空的Model对象,代码如下:
public ObjectNode getModels() {
Model model = repositoryService.newModel();
ObjectNode modelNode = objectMapper.createObjectNode();
modelNode.put("modelId", model.getId());
modelNode.put("name", model.getName());
modelNode.put("key", model.getKey());
modelNode.put("description", "");
modelNode.putPOJO("lastUpdated", model.getLastUpdateTime());
ObjectNode editorJsonNode = objectMapper.createObjectNode();
editorJsonNode.put("id", "canvas");
editorJsonNode.put("resourceId", "canvas");
ObjectNode stencilSetNode = objectMapper.createObjectNode();
stencilSetNode.put("namespace", "http://b3mn.org/stencilset/bpmn2.0#");
editorJsonNode.put("stencilset", stencilSetNode);
editorJsonNode.put("modelType", "model");
modelNode.put("model", editorJsonNode);
return modelNode;
}
编辑时,需要使用RepositoryService提供的getModel()获得已经存在的Model对象,并且使用getModelEditorSource()获得编辑器的内容。再使用ObjectMapper组装为合适的Json对象。
public ObjectNode getModelJSON(@PathVariable String modelId) {
Model model = repositoryService.getModel(modelId);
ObjectNode modelNode = objectMapper.createObjectNode();
modelNode.put("modelId", model.getId());
modelNode.put("name", model.getName());
modelNode.put("key", model.getKey());
modelNode.put("description", JSONObject.parseObject(model.getMetaInfo()).getString("description"));
modelNode.putPOJO("lastUpdated", model.getLastUpdateTime());
byte[] modelEditorSource = repositoryService.getModelEditorSource(modelId);
if (null != modelEditorSource && modelEditorSource.length > 0) {
try {
ObjectNode editorJsonNode = (ObjectNode) objectMapper.readTree(modelEditorSource);
editorJsonNode.put("modelType", "model");
modelNode.put("model", editorJsonNode);
} catch (Exception e) {
e.printStackTrace();
}
}
return modelNode;
}
保存时,需要使用RepositoryService提供的saveModel()保存Model对象,并且使用addModelEditorSource()保存编辑器的内容。
public void saveModel(@PathVariable String modelId, @RequestBody MultiValueMap<String, String> values) {
String json = values.getFirst("json_xml");
String name = values.getFirst("name");
String description = values.getFirst("description");
String key = values.getFirst("key");
Model modelData = repositoryService.getModel(modelId);
if (null == modelData) {
modelData = repositoryService.newModel();
}
ObjectNode modelNode = null;
try {
modelNode = (ObjectNode) new ObjectMapper().readTree(json);
} catch (IOException e) {
e.printStackTrace();
}
ObjectNode modelObjectNode = objectMapper.createObjectNode();
modelObjectNode.put(ModelDataJsonConstants.MODEL_NAME, name);
modelObjectNode.put(ModelDataJsonConstants.MODEL_REVISION, 1);
description = StringUtils.defaultString(description);
modelObjectNode.put(ModelDataJsonConstants.MODEL_DESCRIPTION, description);
modelData.setMetaInfo(modelObjectNode.toString());
modelData.setName(name);
modelData.setKey(StringUtils.defaultString(key));
repositoryService.saveModel(modelData);
try {
repositoryService.addModelEditorSource(modelData.getId(), modelNode.toString().getBytes("utf-8"));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
有个需要注意的地方,我们如何在最开始的时候,获得Json的格式?其实也挺简单的,只需要运行Activiti6.0提供的Release包,然后使用开发者工具截获即可。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
整合Activiti6.0流程设计器-发布和运行 | 字痕随行
之前相关的教程:
这篇就介绍一下如何发布已经保存的流程,并且进行一次简单的流转。
如何发布?
发布其实比较简单,在《整合Activiti6.0流程设计器-编辑保存》这篇教程里面可以看到,前端编辑器传送到后端的数据包,其中有一个参数为“json_xml”,这个其实就是我们需要发布的内容。
同样的,我们在上一篇教程中,将“json_xml”反序列化成了“ObjectNode modelNode”,我们只需要使用Activiti提供的类将modelNode转化一下,再调用对应的发布接口进行发布即可。实际的代码片段如下:
BpmnModel model = new BpmnJsonConverter().convertToBpmnModel(modelNode);
byte[] bpmnBytes = new BpmnXMLConverter().convertToXML(model);
String processName =name + ".bpmn20.xml";
repositoryService.createDeployment().name(name).addString(processName, new String(bpmnBytes)).deploy();
如何流转?
这里需要使用两个新的接口:
1、RuntimeService:Activiti的七大接口之一,可以启动流程及控制流程、查询流程实例、触发流程操作等。
2、TaskService:Activiti的七大接口之一,控制系统中由真实人员执行的任务。
3、IdentityService:Activiti的七大接口之一,可以用来进行身份管理和认证。
先简单的画一个流程:
启动一个流程的过程:
1、 先按照modelId取出这个流程定义。
2、设置启动人。
3、按照流程定义的关键字启动流程。
代码如下:
Model modelData = repositoryService.getModel(modelId);
ProcessInstance processInstance = null;
try {
// 用来设置启动流程的人员ID,引擎会自动把用户ID保存到activiti:initiator中
identityService.setAuthenticatedUserId("admin");
processInstance = runtimeService.startProcessInstanceByKey(modelData.getKey(), "myTestFlow1", map);
String processInstanceId = processInstance.getId();
System.out.println(processInstanceId);
} finally {
identityService.setAuthenticatedUserId(null);
}
当流程启动后,会生成一个流程实例,当需要真实人员操作的时候,就需要使用TaskService提供的接口来操作任务。比如流程图里面的UserTask1和UserTask2。
完成任务的代码片段如下:
//taskId,任务的唯一标识,对应表act_ru_task
taskService.complete(taskId);
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Activiti执行监听器-启动和结束 | 字痕随行
按照Activiti的官方文档,流程的执行监听器可以捕获的事件有:
- 流程实例的启动和结束。
- 选中一条连线。
- 节点的开始和结束。
- 网关的开始和结束。
- 中间事件的开始和结束。
- 开始时间结束或结束事件开始。
在接下来的一段时间内,我会逐一尝试一下,并且通过Demo记录一下整个过程。
首先,我们来尝试捕获一下“流程实例的启动和结束”。下图是一个简单的流程图:

声明了两个类:MyStartListener和MyEndListener,各自实现了接口:
org.activiti.engine.delegate.ExecutionListener
MyStartListener的代码如下:
import org.activiti.engine.delegate.DelegateExecution;
import org.activiti.engine.delegate.ExecutionListener;
public class MyStartListener implements ExecutionListener {
@Override
public void notify(DelegateExecution delegateExecution) {
System.out.println("流程启动");
System.out.println("EventName:" + delegateExecution.getEventName());
System.out.println("ProcessDefinitionId:" + delegateExecution.getProcessDefinitionId());
System.out.println("ProcessInstanceId:" + delegateExecution.getProcessInstanceId());
System.out.println("=======");
}
}
MyEndListener的代码如下:
import org.activiti.engine.delegate.DelegateExecution;
import org.activiti.engine.delegate.ExecutionListener;
public class MyEndListener implements ExecutionListener {
@Override
public void notify(DelegateExecution delegateExecution) {
System.out.println("流程结束");
System.out.println("EventName:" + delegateExecution.getEventName());
System.out.println("ProcessDefinitionId:" + delegateExecution.getProcessDefinitionId());
System.out.println("ProcessInstanceId:" + delegateExecution.getProcessInstanceId());
System.out.println("=======");
}
}
在流程设计器中进行相应的配置,如下图:
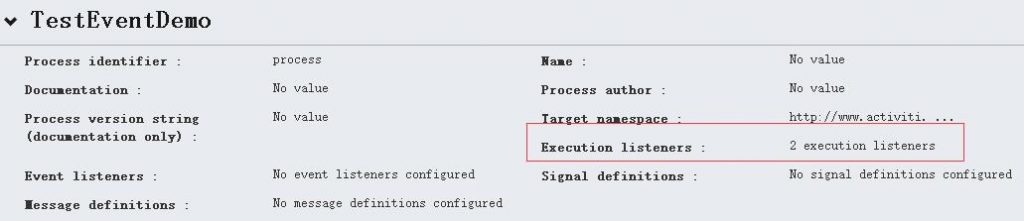
Listener配置
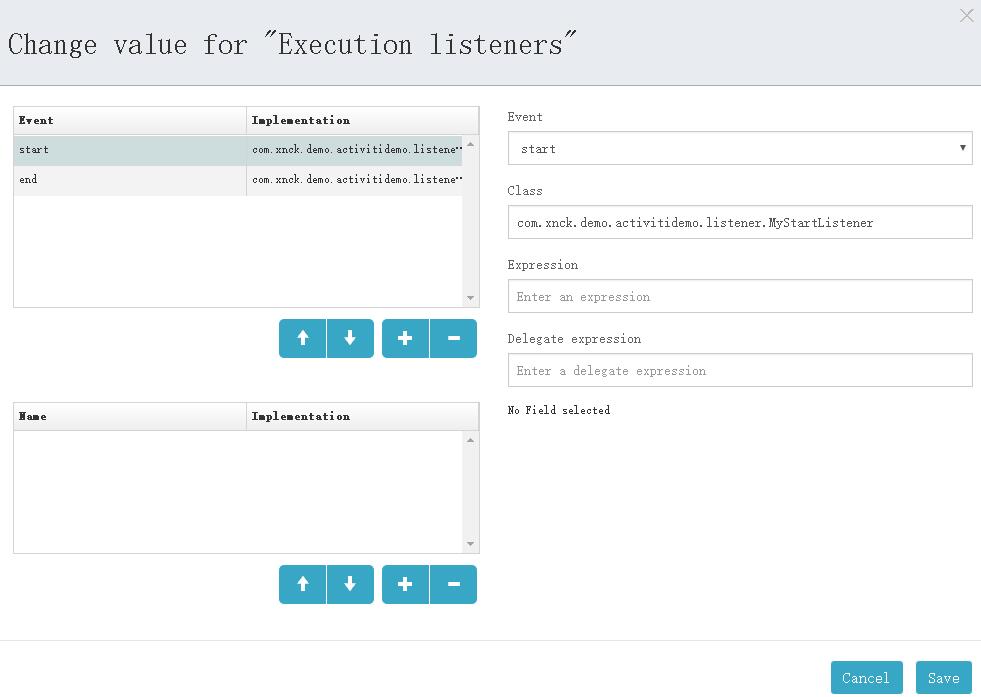
StartListener配置
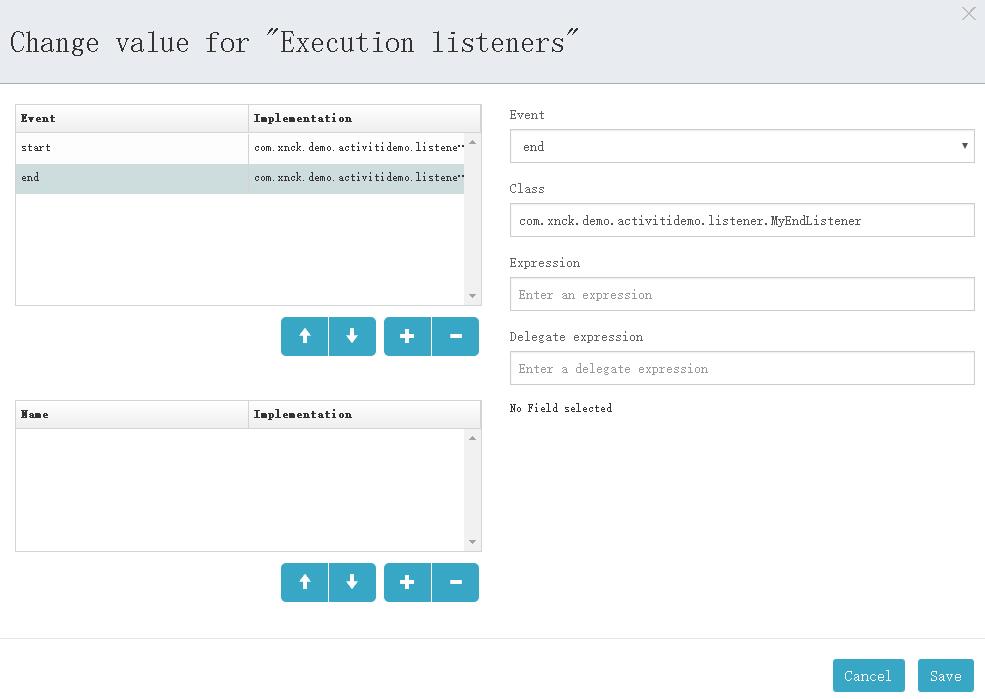
EndListener配置
启动这个流程,控制台会输出:

流程启动时StartEvent触发
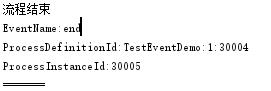
流程结束时EndEvent触发
到此,流程的Start和End事件全部触发完毕,至于DelegateExecution内的方法都是什么含义,将会在之后带来。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Activiti任务监听器 | 字痕随行
Activiti提供了任务监听器,允许在任务执行的过程执行特定的Java程序或者表达式。
任务监听器只能添加到流程定义中的用户任务中。注意它必须定义在BPMN 2.0 extensionElements的子元素中, 并使用activiti命名空间,因为任务监听器是activiti独有的结构。
首先,定义一个任务监听器,代码如下:
import org.activiti.engine.delegate.DelegateTask;
import org.activiti.engine.delegate.TaskListener;
public class MyTaskListener implements TaskListener {
@Override
public void notify(DelegateTask delegateTask) {
System.out.println(delegateTask.getEventName());
if ("assignment".equals(delegateTask.getEventName())) {
System.out.println("办理人" + delegateTask.getAssignee());
}
}
}
在之前的简单流程上,选中UserTask1,设置监听器:
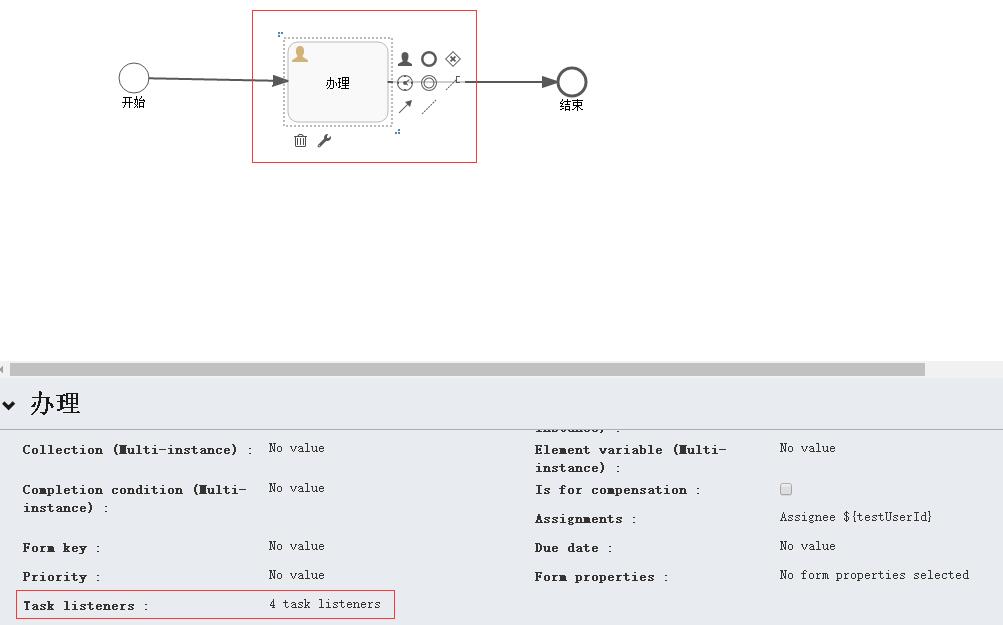
流程设计
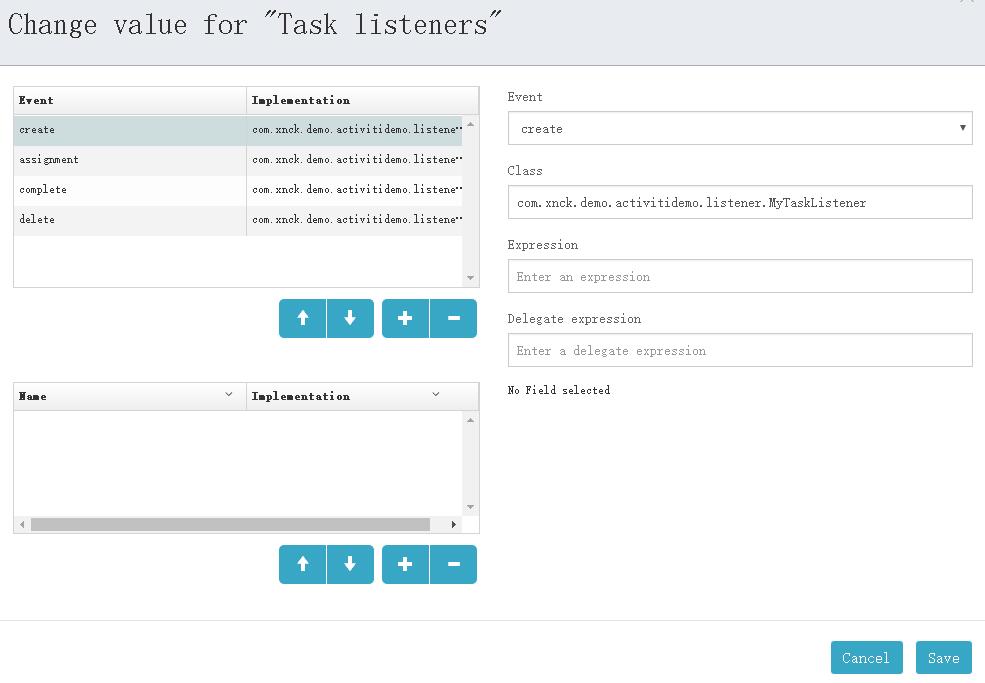
设置监听器
启动,生成一个流程实例,可以看到以下输出:
流程启动
assignment
办理人admin
create
提交完成UserTask1节点,可以看到以下输出:
complete
delete
流程结束
以上输出也反映了事件的执行顺序,这四个事件的说明如下:
assignment:任务分配给指定的人员时触发。当流程到达userTask, assignment事件会在create事件之前发生。
create:任务创建并设置所有属性后触发。
complete:当任务完成,并尚未从运行数据中删除时触发。
delete:只在任务删除之前发生。注意在通过completeTask正常完成时,也会执行。
需要注意的是,如果想要触发assignment事件,就必须将任务分配给指定的人员,可以进行如下操作,以触发此事件:
首先,设置UserTask1的assignment,如下图所示。
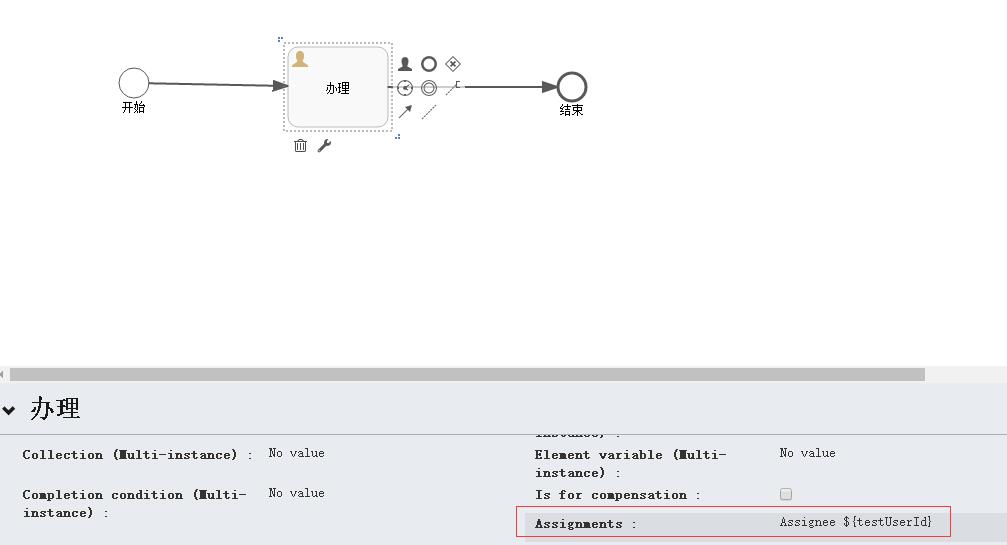
设置assignment
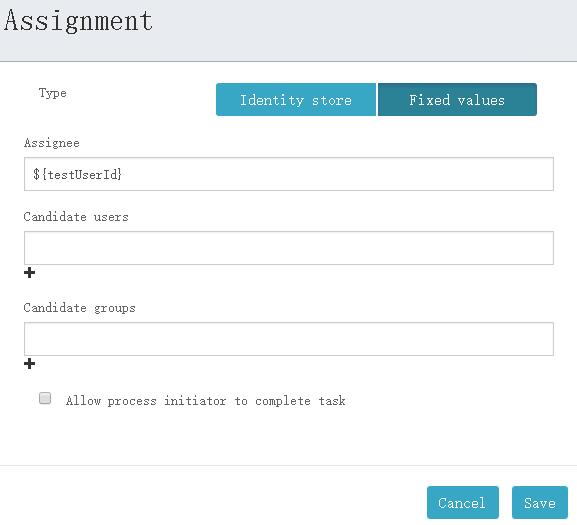
设置assignment
在流程启动时,设置变量:
/**
* 启动一个流程
* @param modelId
*/
@RequestMapping(value = "start/{modelId}")
public void start(@PathVariable("modelId") String modelId) {
Model modelData = repositoryService.getModel(modelId);
Map<String, Object> map = new HashMap<>();
map.put("id", "111111");
map.put("testUserId", "admin");
ProcessInstance processInstance = null;
try {
// 用来设置启动流程的人员ID,引擎会自动把用户ID保存到activiti:initiator中
identityService.setAuthenticatedUserId("admin");
processInstance = runtimeService.startProcessInstanceByKey(modelData.getKey(), "myTestFlow1", map);
String processInstanceId = processInstance.getId();
System.out.println(processInstanceId);
} finally {
identityService.setAuthenticatedUserId(null);
}
}
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
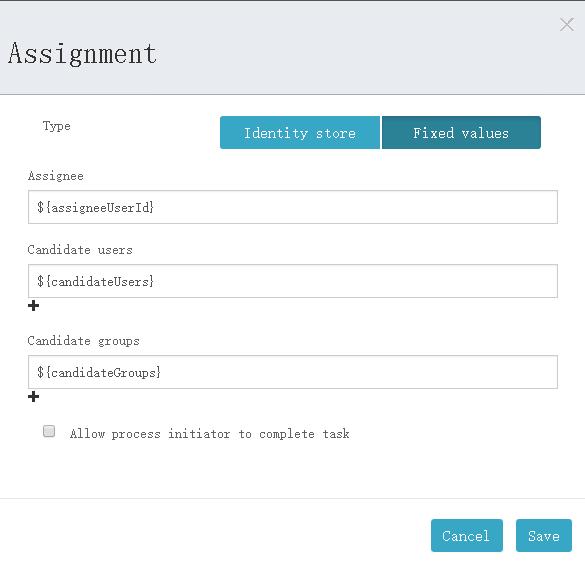
Activiti6.0 – 设置节点处理人 | 字痕随行
Activiti以三种方式设置节点处理人,分别是:
1. Assignment:办理人,指定唯一一个。
2. Candidate users:候选人,可以指定多个人。
3. Candidate groups:候选组,可以指定多个组。
具体的设置如下图:

设置节点处理人的相关代码如下:
/**
* 启动一个流程
* @param modelId
*/
@RequestMapping(value = "start/{modelId}")
public void start(@PathVariable("modelId") String modelId) {
Model modelData = repositoryService.getModel(modelId);
Map<String, Object> map = new HashMap<>();
map.put("id", "111111");
//设置办理人、候选人、候选组
map.put("assigneeUserId", "admin");
map.put("candidateUsers", "test1,test2");
map.put("candidateGroups", "group1,group2");
ProcessInstance processInstance = null;
try {
// 用来设置启动流程的人员ID,引擎会自动把用户ID保存到activiti:initiator中
identityService.setAuthenticatedUserId("admin");
processInstance = runtimeService.startProcessInstanceByKey(modelData.getKey(), "myTestFlow1", map);
String processInstanceId = processInstance.getId();
System.out.println(processInstanceId);
} finally {
identityService.setAuthenticatedUserId(null);
}
}
启动流程后,可以看到:
1. act_ru_task表中,相关流程节点的Assignment字段变更为设定值。

2. act_ru_identitylink表中,增加了多条记录。

如果依照上节设置了任务监听器,如下变更一下代码:
public class MyTaskListener implements TaskListener {
@Override
public void notify(DelegateTask delegateTask) {
System.out.println(delegateTask.getEventName());
if ("assignment".equals(delegateTask.getEventName())) {
System.out.println("代理人" + delegateTask.getAssignee());
System.out.println("参与者数量" + delegateTask.getCandidates().size());
}
if ("create".equals(delegateTask.getEventName())) {
System.out.println("代理人" + delegateTask.getAssignee());
for (IdentityLink identityLink : delegateTask.getCandidates()) {
if ("candidate".equals(identityLink.getType())) {
if (null != identityLink.getUserId()) {
System.out.println("参与者" + identityLink.getUserId());
} else if (null != identityLink.getGroupId()) {
System.out.println("参与组" + identityLink.getGroupId());
}
}
}
}
}
}
可以看到以下输出:
assignment
代理人admin
参与者数量0
create
代理人admin
参与者test2
参与组group1
参与者test1
参与组group2
最后,需要注意:
1. 在类型为assignment的事件中,获得不到候选者和候选人的信息。
2. 办理人、候选人、候选组不必是Activiti内的组织结构信息。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Flowable - 运行UI | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
53个
Flowable最近的版本已经是6.6了,源码的下载地址:
https://github.com/flowable/flowable-engine.git
不过github的地址下载速度堪忧,所以可以尝试一下国内的镜像:
https://gitee.com/mirrors/flowable.git
之前一直介绍的都是如何整合自带的编辑器,如果只是想入门,或者想体验一下Flowable,可以直接使用其自带的管理界面。
在6.4版本内,它的UI是分为多个Module管理的,如下图:

设计器需要启动idm和modeler(它们都是基于SpringBoot的),然后访问地址:
http://localhost:8080/flowable-idm/
输入账户(admin)和密码(test),就可以进入流程模型的创建和设计界面。
而在6.6版本,整个UI包整合为一个包,如下图:
在6.6中,如果想要尝试创建模型,需要运行位于flowable-ui-app中的应用,启动后访问地址:
http://localhost:8080/flowable-ui/
用户名和密码同6.4版本,即可进入。这个界面是原来所有管理界面的统一入口,所以访问和使用起来体验会更加好一些。
如果从未更改过配置文件,应用运行时,默认使用的是H2数据库。
以下仅做参考,需要自行尝试
如果希望使用Mysql来运行flowable-ui,则需要以下几步:
1. 检查flowable-ui-app的pom文件内是否包含mysql-connector,如果未包含,则增加包:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
2. 更改flowable-default.properties内的数据库地址、用户名和密码,注意数据库链接需要增加&serverTimezone=UTC。
3. 运行distro/sql/create/all中的数据库脚本。
4. 运行应用。
我卡在了第3步,因为我的数据库版本有点低,还要更改数据库属性,使其支持大长度索引。因为时间不够,我就没再尝试了,见谅。
以上,简单的使用说明,接下来会尝试一下新的版本。如有错误,欢迎指正。

觉的不错?可以关注我的公众号↑↑↑
Flowable使用Activiti设计器 | 字痕随行
Flowable和Activiti的渊源就不说了,反正是一个妈生的。最近尝试着使用Activiti6的设计器设计流程,然后给Flowable使用。
之前已经进行过Activiti6设计器的整合(参考这里),这里就可以直接拿过来用了。先创建一个Maven工程,然后将Controller、配置文件、设计器的静态文件拷贝过来,最后如下图:
修改pom.xml内的引用内容,主要是将Activiti的引用改为Flowable的引用,同时修改Spring的版本,如果继续使用Spring4,项目会无法启动。
这里使用的版本如下:
<properties>
<!-- spring版本号 -->
<spring.version>5.1.5.RELEASE</spring.version>
<!-- flowable -->
<flowable.version>6.4.1</flowable.version>
</properties>
然后修改spring-common.xml和spring-servlet.xml,spring-common.xml主要是将Activiti的包名换为Flowable的,比如:
spring-servlet.xml主要是之前使用Spring4的一些类已经不存在了,需要修改为Spring5中对应的类。
最后,需要修改\src\main\webapp\activiti\scripts下的app-cfg.js,将其中的内容替换,如下:
ACTIVITI.CONFIG = {
'onPremise' : true,
'contextRoot' : '/your-app-context',
'webContextRoot' : '/your-app-context/activiti'
};
然后运行,效果如下图:
觉的不错?可以关注我的公众号↑↑↑
流程设计器整合 | 字痕随行
之前只有整合教程,而没有相关的整合代码。这周花了点时间,整理了一下,开源了两个项目。
第一个项目
基于SpringMVC整合了Activiti的流程设计器,开源地址如下:
https://gitee.com/blackzs/activiti-designer
相关的整合教程如下:
运行时说明如下:
启动后的入口地址
http://domain:port/activiti/editor/index.html#/editor/
保存后修改流程的地址
http://domain:port/activiti/editor/index.html#/editor/{modelId}
启动一个流程
http://domain:port/flow/start/{modelId}
完成一个任务
http://domain:port/flow/complate/{taskId}
第二个项目
基于SpringBoot整合了Flowable6.4的流程设计器,这个整合不需要依赖Flowable的idm,开源地址如下:
https://gitee.com/blackzs/flowable-designer
相关的整合教程如下:
运行时说明如下:
启动后的入口地址
http://domain:port/designer/editor/index.html#/editor/
保存后修改流程的地址
http://domain:port/designer/editor/index.html#/editor/{modelId}
启动一个流程
http://domain:port/flow/start/{modelId}
完成一个任务
http://domain:port/flow/complate/{taskId}
其它的相关教程可以参见:流程引擎大杂烩
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 – 整合流程设计器 | 字痕随行
之前一直凑合用Activiti6的流程设计器,这些天琢磨着把流程设计器整合到Web应用中,就挤出点时间搞了一下Flowable的流程设计器,在此记录一下整个的整合过程。
其实,有了之前的整合经验,Flowable6.4的整合没有什么难点,而且发现相对容易了一些。
在之前SpringBoot整合Flowable6.4的基础上,将flowable-ui-modeler-app中的源码文件拷贝出来,如下图:
将这些文件拷贝至已有的工程内,文件结构如下图所示:
在运行之前,一定先把app-cfg.js文件中的路径更改掉,比如我这里:
FLOWABLE.CONFIG = {
'onPremise' : true,
'contextRoot' : '',
'webContextRoot' : '/designer',
'datesLocalization' : false
};
运行工程,并访问对应的地址:
http://localhost:8080/designer/index.html#/editor
不出意外的话,页面肯定显示异常。此时,按下F12调用开发人员工具,查看Network情况,会发现URL account报错,具体的地址如下:
http://localhost:8080/app/rest/account
这个地址的调用,其实在文件app.js中,具体的位置如下:
\src\main\resources\static\designer\scripts
具体的代码如下:
$http.get(FLOWABLE.APP_URL.getAccountUrl())
.success(function (data, status, headers, config) {
$rootScope.account = data;
$rootScope.invalidCredentials = false;
$rootScope.authenticated = true;
});
这段代码其实没什么特别的,就是去服务端获取登录用户信息,如果去Flowable的源码里面找到对应的RequestMapping,其实可以看到服务端是使用SecurityUtils获取的账户信息。
如果是整合,不需要集成原有的身份认证,直接使返回用户信息就完事了,具体可以参照之前的整合教程,代码段如下:
@RequestMapping("account")
public Map<String, Object> getAccount() {
Map<String, Object> map = new HashMap<String, Object>();
map.put("email", "admin");
map.put("firstName", "My");
map.put("fullName", "Administrator");
map.put("id", "admin");
map.put("lastName", "Administrator");
Map<String, Object> groupMap = new HashMap<String, Object>();
map.put("id", "ROLE_ADMIN");
map.put("name", "Superusers");
map.put("type", "security-role");
List<Map<String, Object>> groups = new ArrayList<Map<String, Object>>();
groups.add(groupMap);
map.put("groups", groups);
return map;
}
刷新后继续,页面仍旧异常,这时去阅读app.js中的路由配置,会发现只有:
.when('/editor/:modelId', {
templateUrl: appResourceRoot + 'editor-app/editor.html',
controller: 'EditorController'
})
需要在这段代码之前,增加一段:
.when('/editor', {
templateUrl: appResourceRoot + 'editor-app/editor.html',
controller: 'EditorController'
})
保证可以正常的显示页面。再刷新之后,会发现在获得Model时,直接就访问了以下地址:
/app/rest/models/undefined/editor/json
中间的“undefined”肯定是不正确的,追踪中路由中配置的controller,在editor-controller.js中发现和之前Acitiviti整合时不太一样,缺少新建时的请求路径。
分析源码,需要在url-config.js中补充配置:
newModelInfo: function () {
return FLOWABLE.CONFIG.contextRoot + '/app/rest/models/';
}
需要注意的是,这个url-config.js的路径为:
\src\main\resources\static\designer\editor-app\configuration
然后还需要修改此文件中的getStencilSet,否则的话会发现无法获得所需要的Json数据:
getStencilSet: function() {
// return FLOWABLE.CONFIG.contextRoot + '/app/rest/stencil-sets/editor?version=' + Date.now();
return FLOWABLE.CONFIG.webContextRoot + '/editor-app/stencilset.json';
}
然后修改editor-controller.js中请求Model数据的代码段,使其能够直接初始化一个空的数据,代码如下:
//要注意这个modelId,在bootEditor()有相对应的修改
var modelId = $routeParams.modelId || '-1';
var modelUrl;
if ($routeParams.modelId) {
modelUrl = FLOWABLE.URL.getModel($routeParams.modelId);
} else {
//这个是新增的,为的就是能够在没有modelId时能够获取初始数据
modelUrl = FLOWABLE.URL.newModelInfo();
}
editorManager.setModelId(modelId);
//we first initialize the stencilset used by the editor. The editorId is always the modelId.
$http.get(modelUrl).then(function (response) {
editorManager.setModelData(response);
return response;
}).then(function (modelData) {
if(modelData.data.model.stencilset.namespace == 'http://b3mn.org/stencilset/cmmn1.1#') {
return $http.get(FLOWABLE.URL.getCmmnStencilSet());
} else {
return $http.get(FLOWABLE.URL.getStencilSet());
}
}).then(function (response) {
var baseUrl = "http://b3mn.org/stencilset/";
editorManager.setStencilData(response.data);
//the stencilset alters the data ref!
var stencilSet = new ORYX.Core.StencilSet.StencilSet(baseUrl, response.data);
ORYX.Core.StencilSet.loadStencilSet(baseUrl, stencilSet, modelId);
//after the stencilset is loaded we make sure the plugins.xml is loaded.
return $http.get(ORYX.CONFIG.PLUGINS_CONFIG);
}).then(function (response) {
ORYX._loadPlugins(response.data);
return response;
}).then(function (response) {
editorManager.bootEditor();
}).catch(function (error) {
console.log(error);
});
刷新页面,仍旧错误,会报找不到findRootStencilName()这个错误,这个问题很麻烦,后来逐行代码调试,发现其实要通过之前设置的modelId去取指定的对象。
所以在上面的代码中需要给modelId设置一个实际的值,然后在editorManager.bootEditor()这个方法中,增加一段代码,如下:
this.canvasTracker = new Hash();
var config = jQuery.extend(true, {}, this.modelData); //avoid a reference to the original object.
if (!config.modelId) {
config.modelId = '-1';
}
if(!config.model.childShapes){
config.model.childShapes = [];
}
再刷新页面,就可以看到正常的页面了:
以上就是本次整合的主要内容,欢迎指正和探讨。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 - 排他网关 | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
52个
一般情况下,通过开始事件、用户任务、网关、结束事件,就可以组成一个简单的顺序流。
在之前的文章中,开始事件、用户任务、结束事件都有过介绍,这次就来着重介绍一下网关中的排他网关。
顾名思义,排他网关只会选择一条顺序流,即当流程到达排他网关这个节点时,会按顺序(XML中定义的前后顺序)选择出口顺序流(sequenceFlow)计算其定义的条件,如果被计算的条件为True,则按照该出口顺序流向下执行。如果所有出口顺序流的条件都为False,则会抛出异常。
在流程设计器内,排他网关位于Gateways内,其英文名称为Exclusive gateway,如下图所示:
下面就以一个简单流程实验一下排他网关的用法,流程图如下:
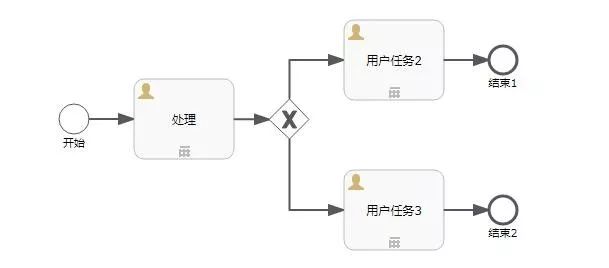
由排他网关到达用户任务2的Flow condition设置为:
${assigneeUserId != "admin"}
由排他网关到达用户任务3的Flow condition设置为:
${assigneeUserId == "admin"}
启动流程时如下设置:
map.put("assigneeUserId", "admin");
runtimeService.startProcessInstanceByKey(modelData.getKey(), "myTestFlow1", map);
整体的流程运行如下:

启动后

通过排他网关后
可以看到,由排他网关到达用户任务3的Flow condition为True,所以流程会自动流转至对应的节点。
如果新加入一个节点,如下图:
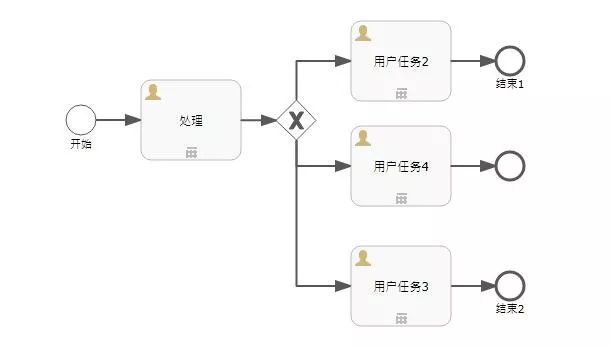
由排他网关到达用户任务4的Flow condition设置为:
${assigneeUserId == "admin"}
然后再启动流程,此时流程到达排他网关的流转规则会按照XML中的顺序流转,如下图所示:

实际运行时的结果也是如此:

如果将用户任务3和用户任务4的Flow condition设置为:
${assigneeUserId != "admin"}
此时,再次启动流程,并流转,将输出异常:
org.springframework.web.util.NestedServletException: Request processing failed;
nested exception is org.flowable.common.engine.api.FlowableException:
No outgoing sequence flow of the exclusive gateway 'sid-07951B0A-225A-440C-A8C9-60D7C00E962F' could be selected for continuing the process
大概的意思就是:
排他网关没有任何向外路径,流程无法流转。
以上,相继介绍了排他网关的用法、条件生效的顺序、全都不符合条件时所产生的异常。
可以点击”阅读原文“查看流程的XML文件,如有错误欢迎指出和讨论。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 – 并行网关和包容网关 | 字痕随行
这个春节的节奏就是:吃喝睡、吃喝睡,手机都懒的刷了。今天开始提振一下心情,整理一下思路,开始缓慢更新。
这次补完一下之前的一篇《Flowable6.4-排他网关》,简单介绍一下并行网关和包容网关的使用。
首先,并行网关。
顾名思义,就是通过这个网关,可以把一个顺序流分成多个顺序流来执行,然后再通过这个网关,把分出来的多条顺序流合并为一个顺序流继续执行。
还是上个简单例子来演示一下,便于理解。流程图如下:
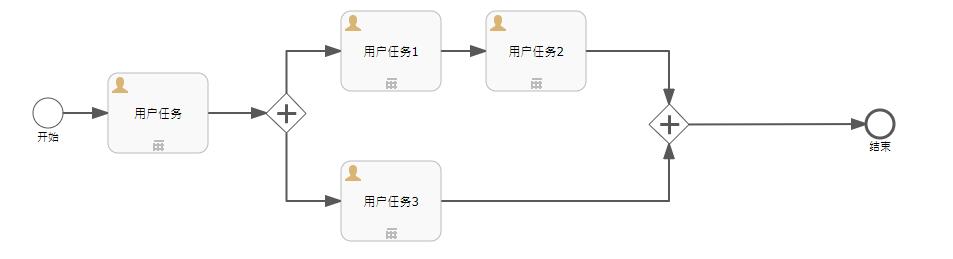
直接启动该流程,完成开始后的第一个用户任务,数据库中的数据显示如下:

可以看到,整个流程分为两条,一条会执行用户任务1->用户任务2这条线,一条会执行用户任务3这个条线。直接完成用户任务3,数据库中的数据显示如下:

此时,只剩下用户任务1,用户任务3那条线处于等待当中,等待用户任务1这条线完成后,整个流程会流转至结束。
如果为并行网关后的连接线增加条件,会发生什么呢?结果是,什么也不会发生,依然会创建两条记录:

可见,并行网关不会执行连线的计算条件。
那么,包容网关是什么呢?
排他网关是只执行第一个符合条件的分支,并行网关是同时执行所有的分支。那么,包容网关同时执行所有符合条件的分支。
比如下面这个流程图:
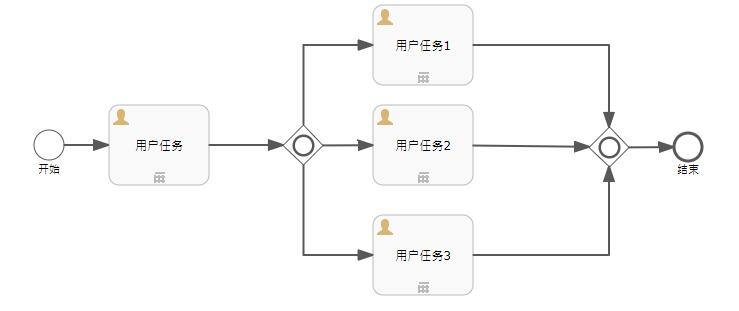
如果没有为包容网关的出口连接线设置过任何条件,在经过包容网关后的效果其实等同于上面的并行网关,它会生成多个顺序流:

如果加上条件的话,设置用户任务1和用户任务3的执行条件为True,用户任务2的执行条件为False,则只有用户任务1和用户任务3这两个分支会被执行:

至此,排他网关、并行网关、包容网关的作用已经介绍完毕。如果有问题欢迎留言讨论。
觉的不错?可以关注我的公众号↑↑↑
命令和责任链模式 | 字痕随行
之前关于Activiti和Flowable的示例,都会实现Command接口,通过命令和责任链模式执行。
下面是命令和责任链模式的解释:
命令模式(Command Pattern)是一种数据驱动的设计模式,它属于行为型模式。请求以命令的形式包裹在对象中,并传给调用对象。调用对象寻找可以处理该命令的合适的对象,并把该命令传给相应的对象,该对象执行命令。
责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。在这种模式中,通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推。
读起来有些拗口,我个人理解就是把一段业务逻辑封装在一个类内,然后按照预设的顺序执行这些类的对象,从而实现更复杂的业务逻辑。
优点自然是解耦和可扩展。
下面是一段简单的示例代码:
首先,声明一个接口:
public interface Command {
void excute();
void setNext(Command command);
Command getNext();
}
接着,使用一个抽象类实现此接口,并实现一些通用的方法:
public abstract class AbstractCommand implements Command {
Command nextCommand;
@Override
public void setNext(Command command) {
this.nextCommand = command;
}
@Override
public Command getNext() {
return this.nextCommand;
}
}
声明一个日志类,实现此抽象类,模拟日志输出:
public class LogCommandImpl extends AbstractCommand {
@Override
public void excute() {
System.out.println("开始执行命令");
if (null != this.nextCommand) {
this.nextCommand.excute();
}
}
}
在声明一个业务类,也实现此抽象类,模拟业务逻辑的执行:
public class ServiceCommand extends AbstractCommand {
@Override
public void excute() {
System.out.println("执行业务逻辑1+1=2");
if (null != this.nextCommand) {
this.nextCommand.excute();
}
}
}
最后,组装这两个命令,让它们按规则运行,比如:
public class CommandTest {
public static void main(String[] args) {
Command serviceCmd = new ServiceCommand();
Command logCmd = new LogCommandImpl();
logCmd.setNext(serviceCmd);
logCmd.excute();
}
}
输出的结果为:
Connected to the target VM, address: '127.0.0.1:55261', transport: 'socket'
开始执行命令
执行业务逻辑1+1=2
Disconnected from the target VM, address: '127.0.0.1:55261', transport: 'socket'
如果想要前后都加上日志输出,可以这样:
public class CommandTest {
public static void main(String[] args) {
Command serviceCmd = new ServiceCommand();
Command logCmd1 = new LogCommandImpl();
Command logCmd2 = new LogCommandImpl();
logCmd1.setNext(serviceCmd);
serviceCmd.setNext(logCmd2);
logCmd1.excute();
}
}
输出的结果变成了:
Connected to the target VM, address: '127.0.0.1:55279', transport: 'socket'
开始执行命令
执行业务逻辑1+1=2
开始执行命令
Disconnected from the target VM, address: '127.0.0.1:55279', transport: 'socket'
本文简单的说明和试验一下命令和职责链模式,便于接下来解读Activiti和Flowable的源码。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 - 流程变量
原创 字痕随行 字痕随行
收录于话题
#流程引擎
52个
这次分享一下流程变量的相关API,有关流程变量的解释如下:
流程实例按步骤执行时,需要使用一些数据。__在Flowable中,这些数据称作“变量(variable)”,并会存储在数据库中。变量可以用在表达式中(例如在排他网关中用于选择正确的出口路径),也可以在Java服务任务(service task)中用于调用外部服务(例如为服务调用提供输入或结果存储),等等。
有关流程局部变量的解释如下:
局部变量将只在该执行中可见,对执行树的上层则不可见。任务与执行一样,可以持有局部变量,其生存期为任务持续的时间。
流程变量有以下几种写入方式:
1. 启动流程时。
启动流程时写入变量的代码如下:
//声明一个JsonObject
JSONObject jsonObject = new JSONObject();
jsonObject.put("id", "1");
jsonObject.put("name", "zhangsan");
jsonObject.put("desc", "sssssssssssssss");
//将JsonObject放入map中
map.put("formData", jsonObject);
//将map作为参数传递
ProcessInstance processInstance = runtimeService.startProcessInstanceByKey(modelData.getKey(), "myTestFlow1", map);
2. 完成Task时。
完成Task时写入变量的代码如下:
Map<String, Object> map = new HashMap<>();
//声明一个JsonObject
JSONObject jsonObject = new JSONObject();
jsonObject.put("id", "2");
jsonObject.put("name", "zhangsan2");
jsonObject.put("desc", "dddddddddddddddddddd");
//将JsonObject放入map中
map.put("formData", jsonObject);
//声明局部变量
Map<String, Object> localMap = new HashMap<>();
localMap.put("num", 1);
localMap.put("string", "1");
//将map作为流程变量,localMap作为局部变量
taskService.complete(taskId, map, localMap);
3. 通过set方法。
通过TaskService内的Set方法的代码如下:
Map<String, Object> map = new HashMap<>();
//声明一个JsonObject
JSONObject jsonObject = new JSONObject();
jsonObject.put("id", "2");
jsonObject.put("name", "zhangsan2");
jsonObject.put("desc", "dddddddddddddddddddd");
//将JsonObject放入map中
map.put("formData", jsonObject);
//声明局部变量
Map<String, Object> localMap = new HashMap<>();
localMap.put("num", 1);
localMap.put("string", "1");
//将map作为流程变量,localMap作为局部变量
taskService.setVariables(taskId, map);
taskService.setVariablesLocal(taskId, localMap);
流程变量的获得方式如下:
1. 通过ExecutionId获得流程变量,代码如下:
//获得流程变量
Map<String, Object> execMap = runtimeService.getVariables(task.getExecutionId());
//获得局部变量
Map<String, Object> execLocalMap = runtimeService.getVariablesLocal(task.getExecutionId());
2. 通过TaskId获得流程变量,代码如下:
//获得流程变量
Map<String, Object> map = taskService.getVariables(taskId);
//获得局部变量
Map<String, Object> localMap = taskService.getVariablesLocal(taskId);
需要特别注意的是:
流程变量在数据库中的存储方式。一般情况下一个流程变量会在act_ru_variable中存储为一行,如果格式为普通格式,就会在这张表中可见,如下图:

但是,当传入的参数为复杂类型时,比如上文中传入的JsonObject,这时流程变量会存储为二进制格式,通过BYTEARRAY_ID_字段关联存储至表act_ge_bytearray中,如下图:
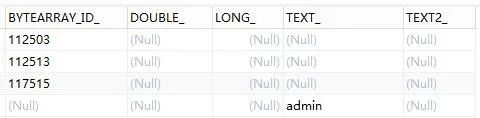
act_ru_variable

act_ge_bytearray
以上就是关于流程变量的分享,如果有问题欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Flowable6 - 事件 | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
53个
貌似从来没有专门介绍过Flowable的事件,只是在流程设计器部分提到过,那么就总结一下吧。
Flowable所有的事件类型,可以参见枚举:
org.flowable.common.engine.api.delegate.event.FlowableEngineEventType
比如最常用的:
/**
* A task has been created. This is thrown when task is fully initialized (before TaskListener.EVENTNAME_CREATE).
*/
TASK_CREATED,
/**
* A task has been completed. Dispatched before the task entity is deleted ( #ENTITY_DELETED). If the task is part of a process, this event is dispatched before the process moves on, as a
* result of the task completion. In that case, a #ACTIVITY_COMPLETED will be dispatched after an event of this type for the activity corresponding to the task.
*/
TASK_COMPLETED,
/**
* A process instance has been started. Dispatched when starting a process instance previously created. The event PROCESS_STARTED is dispatched after the associated event ENTITY_INITIALIZED and
* after the variables have been set.
*/
PROCESS_STARTED,
/**
* A process has been completed. Dispatched after the last activity is ACTIVITY_COMPLETED. Process is completed when it reaches state in which process instance does not have any transition to
* take.
*/
PROCESS_COMPLETED,
这些事件是如何触发的呢?在AbstractEngineConfiguration内初始化了事件的Dispatcher:
public void initEventDispatcher() {
if (this.eventDispatcher == null) {
this.eventDispatcher = new FlowableEventDispatcherImpl();
}
//省略...
}
调用Dispatcher的dispatchEvent来触发事件,比如:
eventDispatcher.dispatchEvent(
FlowableTaskEventBuilder.createEntityEvent(
FlowableEngineEventType.TASK_CREATED,
task
),
processEngineConfiguration.getEngineCfgKey()
);
如何自定义监听这些事件呢?有两个办法:
- 像之前介绍的那样,在流程设计时,加入自定义的事件处理类。
- 在初始化ProcessEngineConfiguration时定义自己的处理类。
简单说一下第二种方法,首先需要实现接口:
public interface FlowableEventListener {
void onEvent(FlowableEvent var1);
boolean isFailOnException();
boolean isFireOnTransactionLifecycleEvent();
String getOnTransaction();
}
然后在实例化ProcessEngineConfiguration时引入实现类的集合:
configuration.setEventListeners(new ArrayList<FlowableEventListener>(){
{
add(new FlowableEventListenerImpl());
}
});
最后,想特别说一下:
/**
* A multi-instance activity has met its condition and completed successfully.
*/
MULTI_INSTANCE_ACTIVITY_COMPLETED_WITH_CONDITION
这个事件的触发条件:
- 多实例情况下。
- 达到了多实例节点的结束条件,也就是Completion condition的表达式为True。
这个事件比较有用,比如:流程的会签(多实例)节点达到结束条件时,可以清理一下冗余的数据,或者发送一条通知消息。
以上,就是关于事件的介绍,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 – 事件,事务 | 字痕随行
最近有个需求,假设流程节点都是同步的,在UserTask创建完成后,推送一条企业微信消息。
需求很简单,实现上也没有什么难度,但是在实现FlowableEventListener这个接口的时候,发现和事务有所联系。
然后,很自然的想到一个问题:这个事件的触发到底是在事务提交之后,还是在事务提交之前。如果在事务提交之前触发了事件,事务提交时又失败回滚,这条发出的消息岂不是无用的。
所以,我又去翻了一遍代码。以TaskService.complete(String taskId)作为切入点,跟踪下去,很容易找到:
TaskHelper.completeTask(task, variables, transientVariables, localScope, commandContext);
然后在上面这个方法内,就会找到事件的触发点:
FlowableEventDispatcher eventDispatcher = CommandContextUtil.getProcessEngineConfiguration(commandContext).getEventDispatcher();
if (eventDispatcher != null && eventDispatcher.isEnabled()) {
if (variables != null) {
eventDispatcher.dispatchEvent(FlowableEventBuilder.createEntityWithVariablesEvent(
FlowableEngineEventType.TASK_COMPLETED, taskEntity, variables, localScope));
} else {
eventDispatcher.dispatchEvent(
FlowableEventBuilder.createEntityEvent(FlowableEngineEventType.TASK_COMPLETED, taskEntity));
}
}
如果继续跟踪下去,就会找到最终的触发代码:
protected void dispatchEvent(FlowableEvent event, FlowableEventListener listener) {
if (listener.isFireOnTransactionLifecycleEvent()) {
//与事务有关的事件
dispatchTransactionEventListener(event, listener);
} else {
//一般的事件
dispatchNormalEventListener(event, listener);
}
}
然后就会看到if...else...判断,而这个判断的条件恰好是在实现FlowableEventListener这个接口时需要实现的方法。
从字面意思上来看,也比较容易理解,一个是触发与事务有关的事件,一个是触发正常的事件。
如果触发与事务有关的事件,可以看到代码是如下运行的:
protected void dispatchTransactionEventListener(FlowableEvent event, FlowableEventListener listener) {
//此处省略代码若干
ExecuteEventListenerTransactionListener transactionListener = new ExecuteEventListenerTransactionListener(listener, event);
//注意这个listener.getOnTransaction()
if (listener.getOnTransaction().equalsIgnoreCase(TransactionState.COMMITTING.name())) {
transactionContext.addTransactionListener(TransactionState.COMMITTING, transactionListener);
}
//此处省略代码若干
}
上面代码中的getOnTransaction(),正好也是在实现FlowableEventListener这个接口时需要实现的方法。
所以结论就是:
1. 在实现FlowableEventListener这个接口时,如果返回了False,事件就会包裹在事务内。
@Override
public boolean isFireOnTransactionLifecycleEvent() {
return false;
}
2. 在实现FlowableEventListener这个接口时,如果返回了True,事件会按照TransactionState的值来触发,与事务的关系也会不同。
@Override
public boolean isFireOnTransactionLifecycleEvent() {
return true;
}
@Override
public String getOnTransaction() {
//事务提交后触发
return TransactionState.COMMITTED.name();
}
3. 所以开头那个问题,最好是设置一下TransactionState,并且在事务提交后触发,可以保证发送的消息是有效的。当然为了保证消息能够可靠送达,还需要一些其它的手段。
以上,如有问题,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 – 在事件中使用API接口 | 字痕随行
标题名称有点长,因为不太好描述今天所分享的内容。今天这篇的目的有两个:
1. 在事件中,处于不同的阶段,使用不同的API进行数据操作。
2. 从侧面验证上一篇文章《Flowable6.4 - 事件,事务》的结论。
如果事件包裹在事务内,即:
@Override
public boolean isFireOnTransactionLifecycleEvent() {
return false;
}
如果使用createXXXXQuery()来进行数据查询,是无法查找出正确的数据的,比如下面的语句:
runtimeService.createExecutionQuery().executionId(executionId).singleResult()
有时候,查找出的结果是null,可能的原因是:新生成的Execution还未被Commit,所以根本无法查到。
新的问题由此产生:在事务提交之前,该怎么来进行数据查询呢?
通过Flowable的源代码来看,会发现一个经常出现的工具类:
CommandContextUtil
比如,查找Execution,就可以使用下面的方法:
CommandContextUtil.getExecutionEntityManager().findById(executionId)
这也从侧面说明,如果isFireOnTransactionLifecycleEvent返回了False,其实是被包裹在事务内的。
也从另外一面说明为什么在《Flowable6.4 - 设置流程分类》中,只是做了以下操作,就可以改变Task的属性:
TaskEntityImpl.setCategory(deploymentEntity.getCategory());
如果事件在Commit之后呢?
就可以使用Flowable提供的API接口来进行数据访问了,比如:
runtimeService.createExecutionQuery().executionId(executionId).singleResult()
taskService.createTaskQuery().taskId(taskId).singleResult()
以上,如有问题,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 - 分派办理人 | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
52个
这次分享的是从一个开源项目的代码里面学来的,有兴趣的同学可以去阅读一下该项目的源码,还是有很多可以参考的地方,项目地址如下:
https://gitee.com/threefish/NutzFw.git
首先,存储办理人的表:act_ru_identitylink。如果想为一个Task分配办理人,可以使用以下的API:
task.addCandidateGroup(String groupId);
task.addCandidateUser(String userId);
task.addCandidateGroups(Collection<String> candidateGroups);
task.addCandidateUsers(Collection<String> candidateUsers);
如果使用以上的API增加一个办理人,会在act_ru_identitylink表中增加一条记录,如下:

使用上述API设置的人员或者组,表中的TYPE_为“candidate”。如果阅读Flowable的源代码,就会发现原因:
//设置人员
public IdentityLinkEntity addCandidateUser(String taskId, String userId) {
return this.addTaskIdentityLink(taskId, userId, (String)null, "candidate");
}
//设置组
public IdentityLinkEntity addCandidateGroup(String taskId, String groupId) {
return this.addTaskIdentityLink(taskId, (String)null, groupId, "candidate");
}
但是,有时候这种固定的属性无法满足我们的业务需要。比如,有时候期望设置部门、岗位、角色。这时候,就需要使用其它的API进行设置,如下:
task.addUserIdentityLink(String userId, String identityLinkTyp);
task.addGroupIdentityLink(String groupId, String identityLinkType);
通过上面的“identityLinkTyp”,就可以自定义TYPE_的值,如下图所示:

之后,就可以进入本次的主要内容了,如何为UserTask节点分配办理人。这里提供的一个方案是通过重写UserTaskActivityBehavior来实现。
关于如何重写UserTaskActivityBehavior,可以参考之前的文章,链接如下:
这里需要重写UserTaskActivityBehavior内的handleAssignments方法,主要的代码如下:
public class ExtUserTaskActivityBehavior extends UserTaskActivityBehavior {
private static final long serialVersionUID = 7711531472879418236L;
public ExtUserTaskActivityBehavior(UserTask userTask) {
super(userTask);
}
/**
* 分配办理人员
*/
@Override
protected void handleAssignments(TaskService taskService, String assignee, String owner, List<String> candidateUsers, List<String> candidateGroups, TaskEntity task, ExpressionManager expressionManager, DelegateExecution execution) {
//此处可以根据业务逻辑自定义
super.handleAssignments(taskService, assignee, owner, candidateUsers, candidateGroups, task, expressionManager, execution);
}
}
比如NutzFW这个开源项目就是通过如下的过程设置的:
- 通过扩展UserTask节点属性,设置办理人。
- 当触发handleAssignments方法时,读取UserTask节点属性。
- 根据节点属性设置办理人。
主要的设置代码如下:
case SINGLE_USER:
//单人情况下,直接设置办理人
assignee = taskExtensionDTO.getAssignee();
break;
case MULTIPLE_USERS:
//多人情况下,设置candidateUsers
candidateUsers = taskExtensionDTO.getCandidateUsers().stream().map(CandidateUsersDTO::getUserName).collect(Collectors.toList());
break;
case USER_ROLE_GROUPS:
//角色时,设置group
candidateGroups = taskExtensionDTO.getCandidateGroups().stream().map(CandidateGroupsDTO::getRoleCode).collect(Collectors.toList());
break;
以上,就是本次的分享,如有问题欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 – 设置流程分类 | 字痕随行
这次的内容是从NutzFW里面学来的,我很喜欢Nutz这个框架。所以,我觉得Nutz的衍生项目都很优秀,包括我的权限管理。
如果查看过act_re_deployment和act_ru_task,会发现这两张表里面都有一个相同的字段 —— Category。使用这个字段,可以为流程和任务添加分类,便于在不同的环境使用。
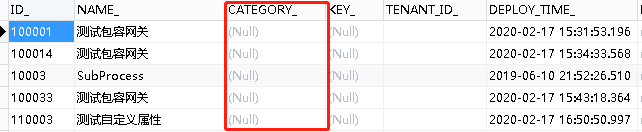
act_re_deployment
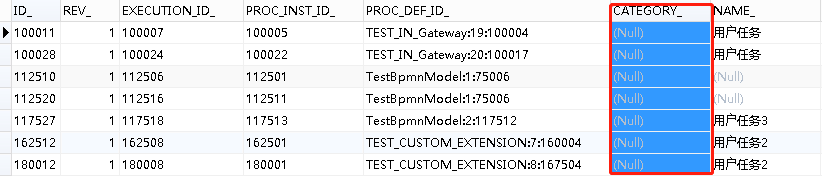
act_ru_task
首先,如何设置act_re_deployment中的Category?
为Deployment设置Category属性还是比较容易的,只需要在Deploy流程定义的时候增加相对应的属性即可,代码如下:
Deployment deployment = repositoryService.createDeployment()
.name(modelData.getName())
.category(modelData.getCategory())//设置此属性即可
.addString(processName, new String(bpmnBytes))
.deploy();
如何在modelData中增加Category?使用以下代码即可:
Model model = repositoryService.getModel(id);
if (null == model) {
model = repositoryService.newModel();
}
//json是流程设计器发回服务端的
ObjectNode modelNode = (ObjectNode) new ObjectMapper().readTree(json);
model.setMetaInfo(modelObjectNode.toString());
model.setName(name);
model.setKey(key);
model.setCategory(category);
repositoryService.saveModel(model);
然后,如何设置act_ru_task中的Category?
为Task设置Category有些麻烦,因为在TaskService中没有找到直接设置的API。所以参考NutzFW中的设置方式,是通过在TaskCreateEvent中,直接修改的TaskEntityImpl中的Category属性。
在这里就不再详细说明如何增加TaskCreateEvent了,可以参考之前的文章:《Activiti执行监听器-启动和结束》。
在事件触发的方法体中,增加以下代码即可设置Category:
FlowableEntityEvent entityEvent = (FlowableEntityEvent) event;
//act_ru_task的实体
TaskEntityImpl entity = (TaskEntityImpl) entityEvent.getEntity();
if (StrUtil.isBlank(entity.getCategory())) {
//前提是Deployment已经设置过Category
ProcessDefinitionEntity processDefinitionEntity = CommandContextUtil.getProcessDefinitionEntityManager().findById(entity.getProcessDefinitionId());
DeploymentEntity deploymentEntity = CommandContextUtil.getDeploymentEntityManager().findById(processDefinitionEntity.getDeploymentId());
//直接修改act_ru_task实体的属性
//因为事件是同步事件,所以会包裹在整体事务中提交
entity.setCategory(deploymentEntity.getCategory());
}
需要注意的是:Task的Category其实是来自于Deployment,所以一定要设置Deployment的Category。
以上,如有问题,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 – BpmnModel | 字痕随行
在Flowable的官方文档中,有一段这样的描述:
在V6中,所有流程定义的信息都可以通过BpmnModel_获取。这是一个BPMN 2.0 XML流程定义的Java表现形式(并对特定操作及搜索进行了增强)。
这一次就看一看BpmnModel到底能够干什么。
如何在一个已知的流程定义中获得BpmnModel呢?
已有模型标识,获得BpmnModel:
byte[] modelEditorSource = repositoryService.getModelEditorSource(modelId);
JsonNode editorNode = new ObjectMapper().readTree(modelEditorSource);
BpmnJsonConverter jsonConverter = new BpmnJsonConverter();
BpmnModel bpmnModel = jsonConverter.convertToBpmnModel(editorNode);
最快的办法,通过流程定义ID获得BpmnModel:
BpmnModel bpmnModel = repositoryService.getBpmnModel(myProcessDefinitionId);
获得BpmnModel后,可以做什么呢?
发布流程:
BpmnModel model = new BpmnJsonConverter().convertToBpmnModel(modelNode);
repositoryService.createDeployment().name("test").addBpmnModel("test.bpmn20.xml", model).deploy();
导出流程定义:
BpmnXMLConverter xmlConverter = new BpmnXMLConverter();
byte[] exportBytes = xmlConverter.convertToXML(bpmnModel);
获得流程节点信息:
Process process = bpmnModel.getMainProcess();
Collection<FlowElement> flowElements = process.getFlowElements();
List<UserTask> userTasks = new ArrayList<>();
for (FlowElement flowElement : flowElements) {
if (flowElement instanceof UserTask) {
UserTask userTask = (UserTask)flowElement;
System.out.println(userTask.getId() + ":" + userTask.getName());
}
}
获得流程图坐标信息:
//获得流程节点信息
Map<String, GraphicInfo> locationMap = bpmnModel.getLocationMap();
//获得流程节点之间连线信息
Map<String, List<GraphicInfo>> flowLocationMap = bpmnModel.getFlowLocationMap();
以上就是BpmnModel的相关介绍,如有问题欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
SpringBoot整合Flowable6.4 | 字痕随行
大量的配置文件让人很烦躁,尤其是某个项目中无处不在却怎么也找不到的配置文件,所以之前的示例项目也是时候改成SpringBoot了。
基于上一篇的示例,首先在Pom文件中新增加DataSource、Flowable和其它一些将要用到的配置:
然后,配置DataSource:
@Configuration
@EnableTransactionManagement
public class DataSourceConfig {
@Primary
@Bean(name = "dataSource")
@ConditionalOnBean(PropertiesConfigurer.class)
public DataSource getDataSource() throws Exception {
DruidDataSource dataSource = new DruidDataSource();
//PropertiesConfigurer是一个获得配置文件属性的持久类
dataSource.setDriverClassName(PropertiesConfigurer.getProperty("db.driver"));
dataSource.setUrl(PropertiesConfigurer.getProperty("db.url"));
dataSource.setUsername(PropertiesConfigurer.getProperty("db.user"));
dataSource.setPassword(PropertiesConfigurer.getProperty("db.password"));
dataSource.setInitialSize(1);
dataSource.setMinIdle(1);
dataSource.setMaxActive(20);
dataSource.setFilters("stat");
return dataSource;
}
@Primary
@Bean(name = "transactionManager")
public DataSourceTransactionManager getDataSourceTransactionManager(@Qualifier("dataSource")DataSource dataSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();
dataSourceTransactionManager.setDataSource(dataSource);
return dataSourceTransactionManager;
}
}
配置Flowable:
@Configuration
public class FlowableConfig {
@Primary
@Bean(name = "processEngineConfiguration")
public SpringProcessEngineConfiguration getSpringProcessEngineConfiguration(@Qualifier("dataSource") DataSource dataSource, @Qualifier("transactionManager")DataSourceTransactionManager transactionManager) {
SpringProcessEngineConfiguration configuration = new SpringProcessEngineConfiguration();
configuration.setDataSource(dataSource);
configuration.setTransactionManager(transactionManager);
configuration.setDatabaseSchemaUpdate("true");
configuration.setAsyncExecutorActivate(true);
configuration.setCustomPostDeployers(new ArrayList<EngineDeployer>(){
private static final long serialVersionUID = 4041439225480991716L;
{
add(new RulesDeployer());
}
});
return configuration;
}
}
配置一下数据库连接字符串,指向一个空库,启动App,就会开始自动创建所需表,如下图:
这里有两个地方值得注意一下:
1. 如果使用flowable-spring-boot-starter,就相当于引入了Flowable全家桶,运行程序后会将所有的表创建出来,如下图:
2. 不需要再像之前使用Spring的时候,将7大接口全都声明一遍,可以在项目中直接使用。
以后有空的话,再看看starter的源码。以上,如果有错误,欢迎探讨和指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 - Behavior使用初探 | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
52个
通过之前分析Behavior的源码,基本上搞清楚了它的作用,这次就简单试验一下它的用法。
如果看过ProcessEngineConfigurationImpl的源码,会在其中的init()方法中发现BehaviorFactory的初始化方法。由此入手,就能够了解如何定制Behavior。
这块的源码暂时先不分析,本次直接使用一个简单的Demo介绍一下如何定制UserTaskActivityBehavior。
首先,声明一个自定义类,直接继承自UserTaskActivityBehavior,具体的代码如下:
/**
* 自定义UserTask节点的Behavior
*/
public class ExtUserTaskActivityBehavior extends UserTaskActivityBehavior {
private static final long serialVersionUID = 7711531472879418236L;
ExtUserTaskActivityBehavior(UserTask userTask) {
super(userTask);
}
@Override
public void execute(DelegateExecution execution) {
System.out.println("这是自定义Behavior的输出:进入节点" + execution.getCurrentActivityId());
super.execute(execution);
}
@Override
public void trigger(DelegateExecution execution, String signalName, Object signalData) {
System.out.println("这是自定义Behavior的输出:触发离开节点" + execution.getCurrentActivityId());
super.trigger(execution, signalName, signalData);
}
}
非常简单,就是在进入和离开节点之前,输出一段日志。如果想让这个自定义的Behavior生效,就必须依靠BehaviorFactory实现。
自定义BehaviorFactory,然后使用上文中已定义的ExtUserTaskActivityBehavior替换原有的UserTaskActivityBehavior,具体代码如下:
/**
* 自定义的BehaviorFactory,在ProcessEngineConfiguration中引入
*/
public class ExtActivityBehaviorFactory extends DefaultActivityBehaviorFactory {
@Override
public UserTaskActivityBehavior createUserTaskActivityBehavior(UserTask userTask) {
return new ExtUserTaskActivityBehavior(userTask);
}
}
此时,已经在自定义的Factory中替换了原有的UserTaskActivityBehavior,但是这只是准备工作,接下来需要让Flowable知晓ExtActivityBehaviorFactory的存在。
在配置文件中,将ExtActivityBehaviorFactory注入到ProcessEngineConfiguration中,具体代码如下:
经过上面的操作后,ExtUserTaskActivityBehavior就会正式生效,在遇到流程中的UserTask节点时,会输出日志。
比如,下面这个流程:

请求以下地址,启动流程:
http://localhost:8080/flowabledemo/flow/start/1
输出的日志如下:

请求以下地址,完成用户任务1:
http://localhost:8080/flowabledemo/flow/complate/60011
输出的日志如下:

至此,自定义的Behavior已经生效。这次的Demo比较简单,下次搞个稍微复杂点的。
以上,如有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 - Behavior的用途分析(execute) | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
52个
上一篇分析了一下Behavior的用途,不过只是追踪到leave()方法就结束了。后来在实际工作当中发现,其内部的execute也挺重要,所以本次就看一下execute()方法的主要作用。
在上一篇中,调用了super.leave()方法后,其实就会离开当前节点,主要是通过下面的代码实现的:
/**
* Default way of leaving a BPMN 2.0 activity: evaluate the conditions on the outgoing sequence flow and take those that evaluate to true.
*/
public void leave(DelegateExecution execution) {
bpmnActivityBehavior.performDefaultOutgoingBehavior((ExecutionEntity) execution);
}
这次代码跟踪,就由此方法开始,看看离开当前节点之后,都发生了什么。
首先,进入performDefaultOutgoingBehavior,一直跟踪下去,最终发现会调用TakeOutgoingSequenceFlowsOperation这个命令。
查看这个命令的run()方法,最终会看到一般的节点会调用leaveFlowNode()方法,这个方法很重要,因为它会按照条件挑选符合的流转路径(Sequence),最终确定目标节点是哪个。
// Determine which sequence flows can be used for leaving
List<SequenceFlow> outgoingSequenceFlows = new ArrayList<>();
for (SequenceFlow sequenceFlow : flowNode.getOutgoingFlows()) {
//省略代码若干,会按condition判断那个sequenceFlow可以使用
}
leaveFlowNode()这个方法的最后,会使当前的流程按照流转路径继续执行下去:
// Leave (only done when all executions have been made, since some queries depend on this)
for (ExecutionEntity outgoingExecution : outgoingExecutions) {
agenda.planContinueProcessOperation(outgoingExecution);
}
planContinueProcessOperation()这个方法其实比较眼熟了,跟踪过去的话,最重要的命令类ContinueProcessOperation就会进入视野了,它的run()方法相当重要,这个方法会按照规则调用不同的方法保证流程运行。
@Override
public void run() {
FlowElement currentFlowElement = getCurrentFlowElement(execution);
if (currentFlowElement instanceof FlowNode) {
continueThroughFlowNode((FlowNode) currentFlowElement);
} else if (currentFlowElement instanceof SequenceFlow) {
continueThroughSequenceFlow((SequenceFlow) currentFlowElement);
} else {
throw new FlowableException("Programmatic error: no current flow element found or invalid type: " + currentFlowElement + ". Halting.");
}
}
基于前面的代码分析,着重关注continueThroughSequenceFlow()这个方法,继续一路跟踪下去,中间有一段关键代码需要关注一下:
//如果是流程节点,就去进入到目标节点内,否则继续重复之前的操作
if (targetFlowElement instanceof FlowNode) {
continueThroughFlowNode((FlowNode) targetFlowElement);
} else {
agenda.planContinueProcessOperation(execution);
}
最后会进入到executeActivityBehavior()这个方法内,于是一切都开始明朗了,最终会看到如下的代码:
try {
activityBehavior.execute(execution);
} catch (RuntimeException e) {
if (LogMDC.isMDCEnabled()) {
LogMDC.putMDCExecution(execution);
}
throw e;
}
可以看到,进入流程节点时,就会调用Behavior的execute方法,如果看一下这个方法的代码,就会发现,这个方法其实主要是创建Task和触发Task事件,以普通的UserTask为例:
@Override
public void execute(DelegateExecution execution) {
//创建Task
TaskEntity task = taskService.createTask();
//省略若干代码,为Task属性赋值
// Handling assignments need to be done after the task is inserted, to have an id
if (!skipUserTask) {
//处理任务分派
handleAssignments(taskService, activeTaskAssignee, activeTaskOwner,
activeTaskCandidateUsers, activeTaskCandidateGroups, task, expressionManager, execution);
//开始触发事件
processEngineConfiguration.getListenerNotificationHelper().executeTaskListeners(task, TaskListener.EVENTNAME_CREATE);
// All properties set, now firing 'create' events
FlowableEventDispatcher eventDispatcher = CommandContextUtil.getTaskServiceConfiguration(commandContext).getEventDispatcher();
if (eventDispatcher != null && eventDispatcher.isEnabled()) {
eventDispatcher.dispatchEvent(
FlowableTaskEventBuilder.createEntityEvent(FlowableEngineEventType.TASK_CREATED, task));
}
} else {
}
}
所以Behavior不只是控制了是否leave当前节点,还控制了进入此节点时,所要执行的业务逻辑。
以上,就是本次的分析,欢迎指正和讨论。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 - Behavior的用途分析 | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
52个
Flowable和Activiti里面有一个很重要的部分 - Behavior,接下来分析一下这部分的主要作用是什么。
首先,要找一个切入点,看一下在调用TaskServiceImpl.complete()时发生了什么。下面是该函数的源码:
@Override
public void complete(String taskId) {
commandExecutor.execute(new CompleteTaskCmd(taskId, null));
}
这里可以看到执行了CompleteTaskCmd,进入这个类的内部,基于以前的文章,看一看这个命令的execute()方法发生了什么,这里主要关注以下的方法:
TaskHelper.completeTask(task, variables, transientVariables, localScope, commandContext);
追踪下去,可以在completeTask()的最末尾找到一段代码:
// Continue process (if not a standalone task)
if (taskEntity.getExecutionId() != null) {
ExecutionEntity executionEntity = CommandContextUtil.getExecutionEntityManager(commandContext).findById(taskEntity.getExecutionId());
CommandContextUtil.getAgenda(commandContext).planTriggerExecutionOperation(executionEntity);
}
继续追踪下去,就进入了TriggerExecutionOperation这个类,在这个类的run()方法内就可以看到Behavior出现了。
@Override
public void run() {
FlowElement currentFlowElement = getCurrentFlowElement(execution);
if (currentFlowElement instanceof FlowNode) {
ActivityBehavior activityBehavior = (ActivityBehavior) ((FlowNode) currentFlowElement).getBehavior();
if (activityBehavior instanceof TriggerableActivityBehavior) {
if (currentFlowElement instanceof BoundaryEvent
|| currentFlowElement instanceof ServiceTask) { // custom service task with no automatic leave (will not have a activity-start history entry in ContinueProcessOperation)
CommandContextUtil.getActivityInstanceEntityManager(commandContext).recordActivityStart(execution);
}
if(!triggerAsync) {
((TriggerableActivityBehavior) activityBehavior).trigger(execution, null, null);
}
else {
//此处省略代码若干
}
}
}
}
当跟踪((TriggerableActivityBehavior) activityBehavior).trigger()的实现时,会发现一堆实现类:

挑选一个最简单的UserTaskActivityBehavior进入,看看发生了什么。会发现调用了一个最关键的方法leave()。然后看看leave()的实现:
@Override
public void leave(DelegateExecution execution) {
FlowElement currentFlowElement = execution.getCurrentFlowElement();
Collection<BoundaryEvent> boundaryEvents = findBoundaryEventsForFlowNode(execution.getProcessDefinitionId(), currentFlowElement);
if (CollectionUtil.isNotEmpty(boundaryEvents)) {
executeCompensateBoundaryEvents(boundaryEvents, execution);
}
//关键在这里,如果没有loop的关键字,就不是多实例,直接调用super.leave
if (!hasLoopCharacteristics()) {
super.leave(execution);
} else if (hasMultiInstanceCharacteristics()) {
multiInstanceActivityBehavior.leave(execution);
}
}
再看看super.leave()的实现,如下:
/**
* Default way of leaving a BPMN 2.0 activity: evaluate the conditions on the outgoing sequence flow and take those that evaluate to true.
*/
public void leave(DelegateExecution execution) {
bpmnActivityBehavior.performDefaultOutgoingBehavior((ExecutionEntity) execution);
}
到这里,通过这些关键字就大体可以猜测出接下来的实现了,同时也应该大概明白Behavior的作用了。
如果再看一下多实例用户节点的Behavior也许就会更加清晰,比如ParallelMultiInstanceBehavior,关键的代码如下:
/**
* Called when the wrapped {@link ActivityBehavior} calls the {@link AbstractBpmnActivityBehavior#leave(DelegateExecution)} method. Handles the completion of one of the parallel instances
*/
@Override
public void leave(DelegateExecution execution) {
//代码略.....
int loopCounter = getLoopVariable(execution, getCollectionElementIndexVariable());
int nrOfInstances = getLoopVariable(execution, NUMBER_OF_INSTANCES);
int nrOfCompletedInstances = getLoopVariable(execution, NUMBER_OF_COMPLETED_INSTANCES) + 1;
int nrOfActiveInstances = getLoopVariable(execution, NUMBER_OF_ACTIVE_INSTANCES) - 1;
//代码略.....
if (zeroNrOfInstances) {
return;
}
ExecutionEntity executionEntity = (ExecutionEntity) execution;
if (executionEntity.getParent() != null) {
//代码略.....
//只有满足跳出条件时,才会调用super.leave
if (nrOfCompletedInstances >= nrOfInstances || isCompletionConditionSatisfied) {
//代码略.....
if (isCompletionConditionSatisfied) {
//代码略.....
sendCompletedWithConditionEvent(leavingExecution);
}
else {
sendCompletedEvent(leavingExecution);
}
super.leave(leavingExecution);
}
} else {
sendCompletedEvent(execution);
super.leave(execution);
}
}
所以综上分析,我个人觉得,Behavior就是控制节点是否跳转的,每一次流转,都会进入到这里,然后在此判断是否满足离开此节点的条件,如果满足就离开此节点,进入到下一个节点,否则的话仍旧保持处于此节点。
以上,就是关于Behavior的分析,欢迎指正和讨论。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 - Behavior改变ConditionExpression | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
52个
上一篇简单介绍了一下如何自定义Behavior,此篇就试验一个稍微复杂一些的:使用Behavior改变ExclusiveGateway的Outgoing条件。
先上流程图:
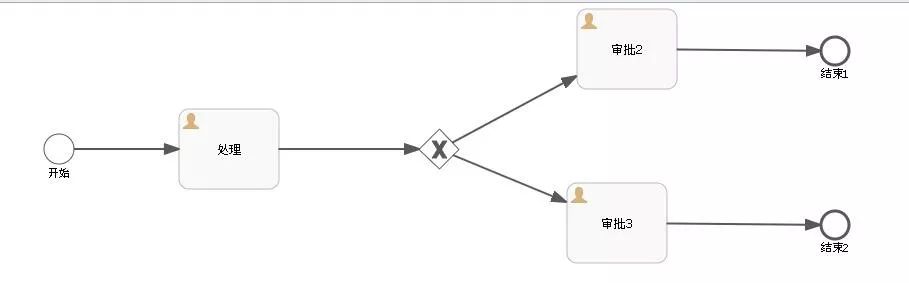
设置一下分支节点(ExclusiveGateway)后面两条路径(SequenceFlow)的执行条件:
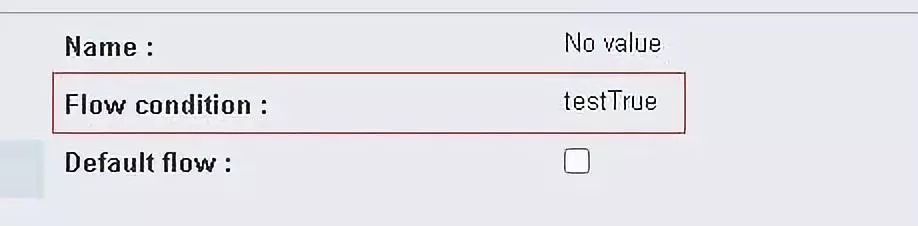
第一条路径
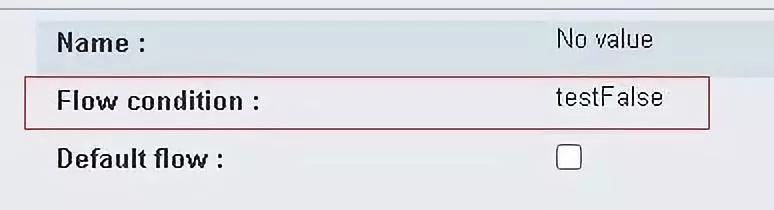
第二条路径
然后,扩展一个ExclusiveGatewayActivityBehavior,源码如下:
public class ExtExclusiveGatewayActivityBehavior extends ExclusiveGatewayActivityBehavior {
private static final long serialVersionUID = -2245991955225188129L;
@Override
public void leave(DelegateExecution execution) {
ExclusiveGateway exclusiveGateway = (ExclusiveGateway) execution.getCurrentFlowElement();
for (SequenceFlow sequenceFlow : exclusiveGateway.getOutgoingFlows()) {
if ("testTrue".equals(sequenceFlow.getConditionExpression())) {
sequenceFlow.setConditionExpression("${1==1}");
System.out.println("经历过网关,设置条件为1==1");
} else if ("testFalse".equals(sequenceFlow.getConditionExpression())) {
sequenceFlow.setConditionExpression("${1!=1}");
System.out.println("经历过网关,设置条件为1!=1");
} else {
System.out.println("经历过网关,保持原条件");
}
}
super.leave(execution);
}
}
上面代码的逻辑很简单,在遇到testTrue时,自动将条件变更为${1=1},即永远为True,在遇到testFalse时,正好与testTrue时相反。
在上一篇中的BehaviorFactory设置一下,代码如下:
@Override
public ExclusiveGatewayActivityBehavior createExclusiveGatewayActivityBehavior(ExclusiveGateway exclusiveGateway) {
return new ExtExclusiveGatewayActivityBehavior();
}
直接运行一下这个流程,控制台内就会输出:

上图中的UserTask2代表审批2,可以看到条件起作用了。
如果将Behavior的代码改为下面这样:
public class ExtExclusiveGatewayActivityBehavior extends ExclusiveGatewayActivityBehavior {
private static final long serialVersionUID = -2245991955225188129L;
@Override
public void leave(DelegateExecution execution) {
ExclusiveGateway exclusiveGateway = (ExclusiveGateway) execution.getCurrentFlowElement();
for (SequenceFlow sequenceFlow : exclusiveGateway.getOutgoingFlows()) {
if ("testTrue".equals(sequenceFlow.getConditionExpression())) {
sequenceFlow.setConditionExpression("${1!=1}");
System.out.println("经历过网关,设置条件为1!=1");
} else if ("testFalse".equals(sequenceFlow.getConditionExpression())) {
sequenceFlow.setConditionExpression("${1==1}");
System.out.println("经历过网关,设置条件为1==1");
} else {
System.out.println("经历过网关,保持原条件");
}
}
super.leave(execution);
}
}
也就是将条件反转一下,再执行一下流程,就会发现如下的输出:

上图中的UserTask3代表审批3,可以看到条件依然生效了。
究其原因,可以阅读一下ExclusiveGatewayActivityBehavior的源码,在其leave()方法中,可以看到比较关键的一段:
Iterator<SequenceFlow> sequenceFlowIterator = exclusiveGateway.getOutgoingFlows().iterator();
while (outgoingSequenceFlow == null && sequenceFlowIterator.hasNext()) {
SequenceFlow sequenceFlow = sequenceFlowIterator.next();
String skipExpressionString = sequenceFlow.getSkipExpression();
if (!SkipExpressionUtil.isSkipExpressionEnabled(skipExpressionString, sequenceFlow.getId(), execution, commandContext)) {
//开始寻找条件为True的那条路径,如果找到之后就使用这条路径流转
boolean conditionEvaluatesToTrue = ConditionUtil.hasTrueCondition(sequenceFlow, execution);
if (conditionEvaluatesToTrue && (defaultSequenceFlowId == null || !defaultSequenceFlowId.equals(sequenceFlow.getId()))) {
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("Sequence flow '{}' selected as outgoing sequence flow.", sequenceFlow.getId());
}
outgoingSequenceFlow = sequenceFlow;
}
} else if (SkipExpressionUtil.shouldSkipFlowElement(skipExpressionString, sequenceFlow.getId(), execution, Context.getCommandContext())) {
outgoingSequenceFlow = sequenceFlow;
}
// Already store it, if we would need it later. Saves one for loop.
if (defaultSequenceFlowId != null && defaultSequenceFlowId.equals(sequenceFlow.getId())) {
defaultSequenceFlow = sequenceFlow;
}
}
这个示例如果扩展一下,其实可以加入Groovy脚本引擎来作为条件控制方,具体的实现就看自身场景需要了。
以上就是本次的内容,欢迎指正和探讨。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 – 加签和减签的源码解析 | 字痕随行
上一篇简单实现了一下加签和减签的操作,这次主要是看看Flowable是如何实现加签和减签的。
首先,加签。
Flowable实现加签主要是通过下面的方法实现的:
runtimeService.addMultiInstanceExecution(String activityId, String parentExecutionId, Map<String, Object> executionVariables)
跟踪代码进入其方法体,发现执行了下面这个命令:
AddMultiInstanceExecutionCmd(activityId, parentExecutionId, executionVariables)
这里的三个参数所代表的的意义是:
activityId:流程节点的标识。
parentExecutionId:流程执行实例标识,proInstId。
executionVariables:所要传入的参数。
查看AddMultiInstanceExecutionCmd这个类的源码,主要关注方法execute(),此方法就是加签操作实现的关键。
关键的代码加注释,如下:
@Override
public Execution execute(CommandContext commandContext) {
ExecutionEntityManager executionEntityManager = CommandContextUtil.getExecutionEntityManager();
//获得multi instance execution,即IS_MI_ROOT
ExecutionEntity miExecution = searchForMultiInstanceActivity(activityId, parentExecutionId, executionEntityManager);
if (miExecution == null) {
throw new FlowableException("No multi instance execution found for activity id " + activityId);
}
if (Flowable5Util.isFlowable5ProcessDefinitionId(commandContext, miExecution.getProcessDefinitionId())) {
throw new FlowableException("Flowable 5 process definitions are not supported");
}
//创建新的流程执行实例
ExecutionEntity childExecution = executionEntityManager.createChildExecution(miExecution);
childExecution.setCurrentFlowElement(miExecution.getCurrentFlowElement());
//获得BPMN模型中节点的配置信息
BpmnModel bpmnModel = ProcessDefinitionUtil.getBpmnModel(miExecution.getProcessDefinitionId());
Activity miActivityElement = (Activity) bpmnModel.getFlowElement(miExecution.getActivityId());
MultiInstanceLoopCharacteristics multiInstanceLoopCharacteristics = miActivityElement.getLoopCharacteristics();
//设置流程参数nrOfInstances
Integer currentNumberOfInstances = (Integer) miExecution.getVariable(NUMBER_OF_INSTANCES);
miExecution.setVariableLocal(NUMBER_OF_INSTANCES, currentNumberOfInstances + 1);
//设置子流程执行实例的参数
if (executionVariables != null) {
childExecution.setVariablesLocal(executionVariables);
}
//如果是并行,需要执行操作,生成Task记录
if (!multiInstanceLoopCharacteristics.isSequential()) {
miExecution.setActive(true);
miExecution.setScope(false);
childExecution.setCurrentFlowElement(miActivityElement);
CommandContextUtil.getAgenda().planContinueMultiInstanceOperation(childExecution, miExecution, currentNumberOfInstances);
}
return childExecution;
}
需要注意的就是最后部分的操作,因为节点有并行和串行的区分,所以需要不同的处理。
再看,减签。
Flowable实现加签主要是通过下面的方法实现的:
runtimeService.deleteMultiInstanceExecution(String executionId, boolean executionIsCompleted)
跟踪代码进入其方法体,发现执行了下面这个命令:
DeleteMultiInstanceExecutionCmd(executionId, executionIsCompleted)
这里的两个参数所代表的的意义是:executionId:需要删除的流程执行实例标识。
executionIsCompleted:是否完成此流程执行实例。查看
DeleteMultiInstanceExecutionCmd这个类的源码,主要关注方法execute(),此方法就是加签操作实现的关键。
关键的代码加注释,如下:
@Override
public Void execute(CommandContext commandContext) {
ExecutionEntityManager executionEntityManager = CommandContextUtil.getExecutionEntityManager();
ExecutionEntity execution = executionEntityManager.findById(executionId);
//获得BPMN模型中节点的配置信息
BpmnModel bpmnModel = ProcessDefinitionUtil.getBpmnModel(execution.getProcessDefinitionId());
Activity miActivityElement = (Activity) bpmnModel.getFlowElement(execution.getActivityId());
MultiInstanceLoopCharacteristics multiInstanceLoopCharacteristics = miActivityElement.getLoopCharacteristics();
if (miActivityElement.getLoopCharacteristics() == null) {
throw new FlowableException("No multi instance execution found for execution id " + executionId);
}
if (!(miActivityElement.getBehavior() instanceof MultiInstanceActivityBehavior)) {
throw new FlowableException("No multi instance behavior found for execution id " + executionId);
}
if (Flowable5Util.isFlowable5ProcessDefinitionId(commandContext, execution.getProcessDefinitionId())) {
throw new FlowableException("Flowable 5 process definitions are not supported");
}
//删除指定的流程执行实例和与其关联的数据
ExecutionEntity miExecution = getMultiInstanceRootExecution(execution);
executionEntityManager.deleteChildExecutions(execution, "Delete MI execution", false);
executionEntityManager.deleteExecutionAndRelatedData(execution, "Delete MI execution", false);
//获得循环的索引值,以便之后重新设置
int loopCounter = 0;
if (multiInstanceLoopCharacteristics.isSequential()) {
//如果是串行,则获得当前的索引值
SequentialMultiInstanceBehavior miBehavior = (SequentialMultiInstanceBehavior) miActivityElement.getBehavior();
loopCounter = miBehavior.getLoopVariable(execution, miBehavior.getCollectionElementIndexVariable());
}
//如果设置为流程执行实例已经完成,则已完成数量+1,并且索引值也+1
//如果设置为流程执行实例未完成,则流程实例数量-1,索引值不变
if (executionIsCompleted) {
Integer numberOfCompletedInstances = (Integer) miExecution.getVariable(NUMBER_OF_COMPLETED_INSTANCES);
miExecution.setVariableLocal(NUMBER_OF_COMPLETED_INSTANCES, numberOfCompletedInstances + 1);
loopCounter++;
} else {
Integer currentNumberOfInstances = (Integer) miExecution.getVariable(NUMBER_OF_INSTANCES);
miExecution.setVariableLocal(NUMBER_OF_INSTANCES, currentNumberOfInstances - 1);
}
//生成一个新的流程执行实例(个人觉得这个是专为串行准备的)
ExecutionEntity childExecution = executionEntityManager.createChildExecution(miExecution);
childExecution.setCurrentFlowElement(miExecution.getCurrentFlowElement());
//如果是串行,需要执行一次生成Task,并且设置正确的loopCounter
if (multiInstanceLoopCharacteristics.isSequential()) {
SequentialMultiInstanceBehavior miBehavior = (SequentialMultiInstanceBehavior) miActivityElement.getBehavior();
miBehavior.continueSequentialMultiInstance(childExecution, loopCounter, childExecution);
}
return null;
}
所以,通过分析上述源码,如果是并行的多实例节点,并且删除了最后一个流程执行实例,会发现没有了Task,导致整个流程中断。
以上,就是对于Flowable6.4的加签和减签的源码分析,如果有错误,请指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 – 加签和减签 | 字痕随行
趁着旅游归来的短暂休息,了解一下Flowable中的加签和减签操作。主要是以下两个方法来实现:
runtimeService.addMultiInstanceExecution(String activityId, String parentExecutionId, Map<String, Object> executionVariables)
runtimeService.deleteMultiInstanceExecution(String executionId, boolean executionIsCompleted)
依然是先上流程图:
其中会签节点是多实例节点,此流程的关键xml片段如下:
<process id="TestMutiTask" isExecutable="true">
<startEvent id="Start1" name="开始"></startEvent>
<userTask id="UserTask1" name="处理"></userTask>
<sequenceFlow id="sid-D14A5BC6-A61E-461F-AD33-0042E91B8B13" sourceRef="Start1" targetRef="UserTask1"></sequenceFlow>
<userTask id="UserTask2" name="会签">
<multiInstanceLoopCharacteristics isSequential="false" flowable:collection="${subProcessHelper.getUserNames()}" flowable:elementVariable="assignee">
<completionCondition>${subProcessHelper.isComplete(execution)}</completionCondition>
</multiInstanceLoopCharacteristics>
</userTask>
<sequenceFlow id="sid-E6847EF6-F54F-409B-AF8B-DCA62ECDC76F" sourceRef="UserTask1" targetRef="UserTask2"></sequenceFlow>
<userTask id="UserTask3" name="审批"></userTask>
<sequenceFlow id="sid-AF828B84-DDAA-4056-88C5-9D4F6EA9F725" sourceRef="UserTask2" targetRef="UserTask3"></sequenceFlow>
<endEvent id="End1" name="结束"></endEvent>
<sequenceFlow id="sid-C49B6256-0827-4CF5-8A47-5860A107142A" sourceRef="UserTask3" targetRef="End1"></sequenceFlow>
</process>
subProcessHelper.getUserNames():会返回一个List集合,会签节点会根据此集合的数量生成相对应的实例。
subProcessHelper.isComplete(execution):用来判断会签节点是否完成,这里设置的条件为“已完成数量/总数量>2/3”。
调用加签和减签的方法如下:
/**
* 增加流程执行实例
* @param nodeId
* @param proInstId
* @param assigneeStr 以逗号隔开的字符串
*/
@RequestMapping(value = "addExecution/{nodeId}/{proInstId}/{assignees}")
public void addExecution(@PathVariable("nodeId") String nodeId,
@PathVariable("proInstId") String proInstId,
@PathVariable("assignees") String assigneeStr) {
String[] assignees = assigneeStr.split(",");
for (String assignee : assignees) {
runtimeService.addMultiInstanceExecution(nodeId, proInstId, Collections.singletonMap("assignee", (Object) assignee));
}
}
/**
* 删除流程执行实例
* @param excutionId
* @param complated 是否完成此流程执行实例
*/
@RequestMapping(value = "delExecution/{excutionId}/{complated}")
public void delExecution(@PathVariable("excutionId") String excutionId,
@PathVariable("complated") Boolean complated) {
runtimeService.deleteMultiInstanceExecution(excutionId, complated);
}
启动流程,将流程跳转至会签节点,如下图所示:

act_ru_task

act_ru_execution
此时请求加签方法:
http://localhost:8080/flowabledemo/flow/addExecution/UserTask2/55001/test004
流程会增加一个新的子实例,并且会增加相对应的参数,如下:

act_ru_task

act_ru_execution

act_ru_variable
此时如果请求减签的方法:
http://localhost:8080/flowabledemo/flow/delExecution/55034/0
流程中相对应的Task和Variable会被删除:

act_ru_task
以上,就是本次试验的内容,需要注意的是,在减签时,如果Task正好是该多实例节点中的最后一个,将导致流程无法继续流转。下次可以分析一下源码,看看为何会这样。
有问题的话,欢迎指正和讨论。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4多实例流程节点跳转 | 字痕随行
本文将试验一下多实例流程节点的跳转。
首先,试验一下多实例用户任务节点。
流程图如下:
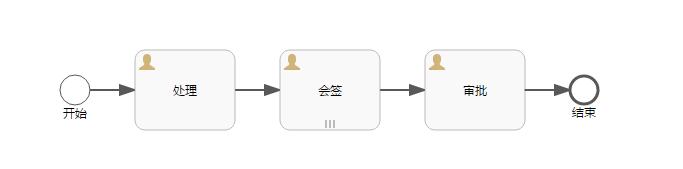
可以看到,上图中的“会签”节点为多实例节点,并且为并行模式。启动这个流程,并且使流程流转至“会签”节点:

请求下面的地址:
http://localhost:8080/flowabledemo/flow/move/40001/UserTask2/UserTask1
流程会由“会签”节点流转至“处理”节点:

继续请求下面的地址:
http://localhost:8080/flowabledemo/flow/move/40001/UserTask1/UserTask2
流程会由“处理”节点流转至“会签”节点:

然后,试验一下多实例子流程。
流程图如下:

启动这个流程,使流程进入子流程节点:

请求下面的地址:
http://localhost:8080/flowabledemo/flow/move/40061/SubProcess1/UserTask1
流程会由“子流程”流转至“处理”节点:

继续请求下面的地址:
http://localhost:8080/flowabledemo/flow/move/40061/UserTask1/SubProcess1
流程会由“处理”流转至“子流程”节点:

如果子流程内的节点需要跳转,可以使用以下代码进行跳转:
/**
* 移动流程实例
*/
@RequestMapping(value = "moveExecution/{proInstId}/{toNodeId}")
public void moveExecution(@PathVariable("proInstId") String proInstId,
@PathVariable("toNodeId") String toNodeId) {
runtimeService.createChangeActivityStateBuilder()
.moveExecutionToActivityId(proInstId, toNodeId)
.changeState();
}
请求以下地址:
http://localhost:8080/flowabledemo/flow/moveExecution/40122/SubUserTask2
EXECUTION_ID等于40122的子流程将跳转至“子处理2”,如图:

以上,就是本次试验的全部记录。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4子流程节点跳转 | 字痕随行
本文将继续试验一下子流程的节点跳转,包含以下两种子流程:内嵌子流程和调用子流程。
首先,试验一下内嵌子流程。
流程图如下:
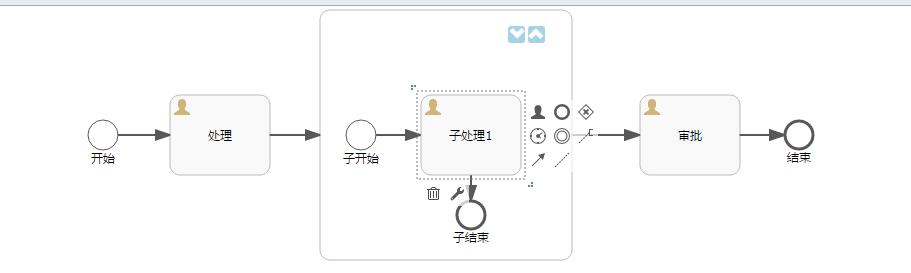
启动流程,流程处于“处理”节点:

使用以下代码进行跳转:
/**
* 移动节点
*/
@RequestMapping(value = "move/{proInstId}/{nodeId}/{toNodeId}")
public void move(@PathVariable("proInstId") String proInstId,
@PathVariable("nodeId") String nodeId,
@PathVariable("toNodeId") String toNodeId) {
runtimeService.createChangeActivityStateBuilder()
.processInstanceId(proInstId)
.moveActivityIdTo(nodeId, toNodeId)
.changeState();
}
在浏览器地址栏中输入跳转地址进行测试:
http://localhost:8080/flowabledemo/flow/move/37501/UserTask1/SubUserTask1
节点可以由UserTask1跳转至SubUserTask1:

同样的,节点也可以由SubUserTask1跳转至UserTask1。
然后,试验一下调用子流程。
流程图如下:
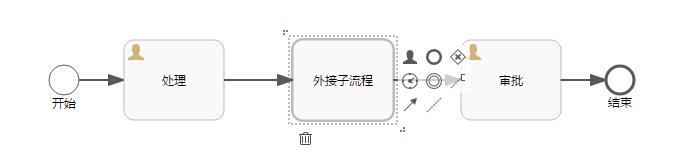
外接的子流程如下(见上一篇):

启动流程,流程处于“处理”节点:

因为进入到外接子流程时,会单独启动一个流程实例,所以跳转的代码也比较特殊,如下所示:
/**
* 移动到子流程
* @param proInstId
* @param subProcess
* @param subNodeId
* @param parentNodeId
*/
@RequestMapping(value = "moveToSub/{proInstId}/{parentNodeId}/{subNodeId}/{subProcess}")
public void moveToSub(@PathVariable("proInstId") String proInstId,
@PathVariable("subProcess") String subProcess,
@PathVariable("subNodeId") String subNodeId,
@PathVariable("parentNodeId") String parentNodeId) {
runtimeService.createChangeActivityStateBuilder()
.processInstanceId(proInstId)
.moveActivityIdToSubProcessInstanceActivityId(parentNodeId, subNodeId, subProcess)
.changeState();
}
其中参数subProcess为节点“外接子流程”的ID,如下图:
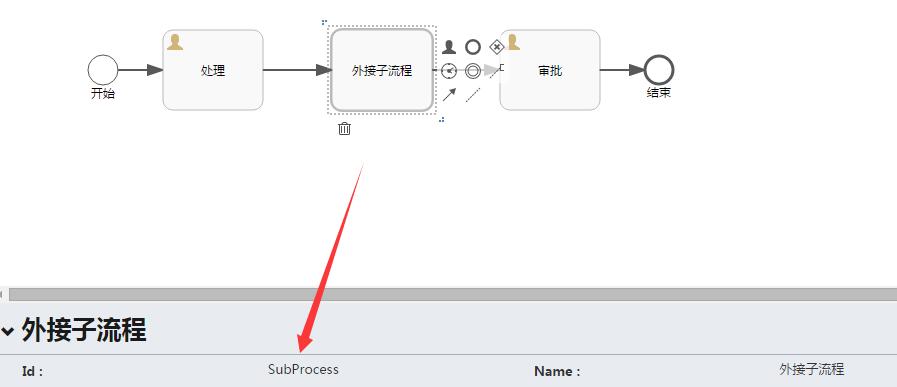
此时在浏览器地址栏输入:
http://localhost:8080/flowabledemo/flow/moveToSub/37530/UserTask1/UserTask1/SubProcess
可以跳转至子流程内的UserTask1节点:

如果需要将流程由子流程内的UserTask1节点跳转至父流程的“审批(UserTask2)”节点,则需要另外一段代码:
/**
* 移动到父节点
* @param subProInstId
* @param subNodeId
* @param parentNodeId
*/
@RequestMapping(value = "moveToParent/{subProInstId}/{subNodeId}/{parentNodeId}")
public void moveToParent(@PathVariable("subProInstId") String subProInstId,
@PathVariable("subNodeId") String subNodeId,
@PathVariable("parentNodeId") String parentNodeId) {
runtimeService.createChangeActivityStateBuilder()
.processInstanceId(subProInstId)
.moveActivityIdToParentActivityId(subNodeId, parentNodeId)
.changeState();
}
此时在浏览器地址栏输入:
http://localhost:8080/flowabledemo/flow/moveToParent/37543/UserTask1/UserTask2
流程将跳转至“审批”节点:

以上就是本次关于子流程节点跳转的全部试验过程,下一次将试验一下多实例节点的跳转。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4节点跳转初探 | 字痕随行
Flowable6已经实现了流程节点间的跳转,本次就初探一下相关的API。
相关的示例代码在Flowable的开源代码中可以找到,具体的位置如下:
\flowable\6.4.2\modules\flowable-engine\src\test\java\org\flowable\engine\test\api\runtime\changestate
本次试验先介绍普通节点间的跳转,主要用到的API如下:
//普通节点间跳转
runtimeService.createChangeActivityStateBuilder()
.processInstanceId(proInstId)
.moveActivityIdTo(nodeId, toNodeId)
.changeState();
1. 普通流程图
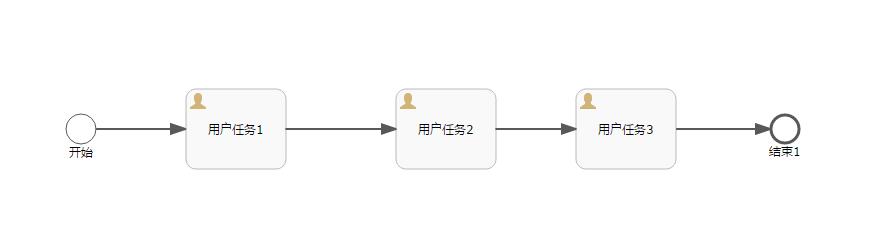
这种流程下,节点的跳转非常容易,这里做了一个rest接口来试验,代码如下:
/**
* 移动节点
*/
@RequestMapping(value = "move/{proInstId}/{nodeId}/{toNodeId}")
public void move(@PathVariable("proInstId") String proInstId,
@PathVariable("nodeId") String nodeId,
@PathVariable("toNodeId") String toNodeId) {
runtimeService.createChangeActivityStateBuilder()
.processInstanceId(proInstId)
.moveActivityIdTo(nodeId, toNodeId)
.changeState();
}
流程启动后,在地址栏输入:
http://localhost:8080/flowabledemo/flow/move/25094/UserTask1/UserTask3
流程节点由UserTask1变化为UserTask3:

再在地址栏输入:
http://localhost:8080/flowabledemo/flow/move/25094/UserTask3/UserTask1
流程节点由UserTask3变化为UserTask1:

2. 多实例流程图
此处以并行的多实例节点为例,相关的代码同第一节。流程图如下:
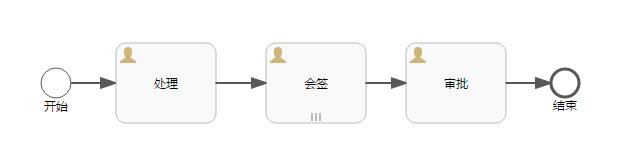
流程启动后,在地址栏输入:
http://localhost:8080/flowabledemo/flow/move/25005/UserTask1/UserTask2
流程节点由UserTask1变为UserTask2,数据库表内会创建三个新的流程实例,如下图:

完成一个任务节点,流程变为:

在地址栏输入:
http://localhost:8080/flowabledemo/flow/move/25005/UserTask2/UserTask3
流程节点由UserTask2变为UserTask3:

在地址栏再次输入:
http://localhost:8080/flowabledemo/flow/move/25005/UserTask3/UserTask2
流程节点再次变为UserTask2,数据库表内再次创建三个新的流程实例,如下图:

其它复杂的流程,比如分支、子流程等,会在接下来的实验中带来。
觉的不错?可以关注我的公众号↑↑↑
Flowable6 - 多实例子流程(会签的方案) | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
55个
今天我要写这篇文章的时候,关注量变成了一个傻数,哈哈:
/640.png)
之前有一篇文章,介绍过基于多实例用户任务实现会签的方案 - 《Flowable6.4 - 会签实现方案》。
有的场景,使用多实例用户任务无法实现,比如下面这种会签场景:

在会签时,需要“部门普通员工”先审核,然后“部门主管”再审核,这种情况使用多实例用户任务显然无法实现,即使勉强实现,最终所描述的场景肯定有所欠缺。
在使用多实例子流程实现会签时,最主要的两个问题是:
- 办理人如何分派。
- 会签结束时,投票结果如何统计。
这篇文章介绍一下我能想到的方案,梳理自己思路的同时,希望对大家有所帮助。
1. 办理人如何分派
在这里首先需要确定一个规则:多实例子流程内,用户任务节点的办理人只能由多实例子流程决定(设置)。
也就是说,在多实例子流程这个元素上设置办理人,多实例子流程按照设置的办理人来决定产生多少个流程实例,然后决定每个流程实例中用户任务的办理人。
多实例子流程设置的办理人只能是:角色、部门、岗位等这种用户组,不能是具体的人员。
如果是具体的人员,我觉得使用子流程就显得毫无意义,比如上面的流程图中,先不说是否符合需求,单说每个子流程都是确定的人来执行的话,用多实例用户任务来实现是一样的。
设定了这个规则以后,基本的实现就和多实例用户任务差不多了:

2. 会签结束时,投票结果如何统计
首先,多实例用户任务时,投票的结果以“SIGN_VOTE_TASKID”来表示,这在多实例子流程时,就无法使用这种规则了。
这时候,可以使以“SIGN_VOTE_EXECUTIONID”表示。其实多实例子流程生成的每一个流程实例,其ExecutionId在执行期间是不变的,这样就能够保证每一次用户任务的操作,可以改变自己所属子流程的投票结果。
然后,每一个子流程执行完毕时,如何判断会签是否达到结束条件。这个判断的关键点在于“SIGN_VOTE_EXECUTIONID”的设置。
如果像UserTask一样,在每次Complete时,就设置。那么每一次子流程执行完毕,需要进行Completion Condition判断时,如果只是判断是否包含关键字“SIGN_VOTE_”,统计到的子流程的投票结果可能是未执行完毕的。
这时候怎么办?我觉得可以通过判断loopCounter参数是否存在,来判断子流程是否结束完毕,然后再通过获得“SIGN_VOTE_”作为投票结果。
还有一种方式,就是在流程结束事件内对“SIGN_VOTE_”进行设置。当然,每一次流程结束事件,还需要判断这个流程是否是子流程,如果是,再设置。否则的话,正常的主流程结束了也是会抛出这个事件的。
最后,以上的方案,我没有想过子流程再嵌套子流程的情况,太复杂了。也没有想过调用子流程的情况,因为调用子流程的机制不太一样,也是比较复杂。
全是文字,因为这只是个想法,我还没有实现呢。如果以上有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6 - 多实例子流程(会签的方案) | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
55个
今天我要写这篇文章的时候,关注量变成了一个傻数,哈哈:

之前有一篇文章,介绍过基于多实例用户任务实现会签的方案 - 《Flowable6.4 - 会签实现方案》。
有的场景,使用多实例用户任务无法实现,比如下面这种会签场景:
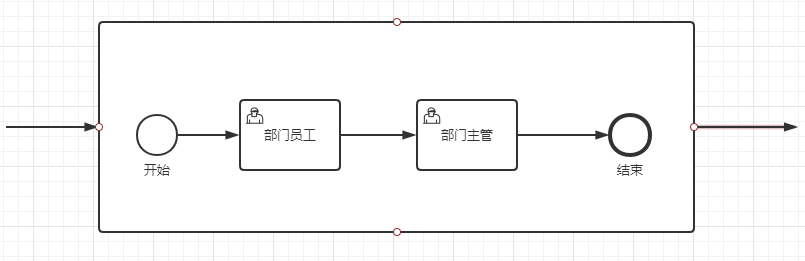
在会签时,需要“部门普通员工”先审核,然后“部门主管”再审核,这种情况使用多实例用户任务显然无法实现,即使勉强实现,最终所描述的场景肯定有所欠缺。
在使用多实例子流程实现会签时,最主要的两个问题是:
- 办理人如何分派。
- 会签结束时,投票结果如何统计。
这篇文章介绍一下我能想到的方案,梳理自己思路的同时,希望对大家有所帮助。
1. 办理人如何分派
在这里首先需要确定一个规则:多实例子流程内,用户任务节点的办理人只能由多实例子流程决定(设置)。
也就是说,在多实例子流程这个元素上设置办理人,多实例子流程按照设置的办理人来决定产生多少个流程实例,然后决定每个流程实例中用户任务的办理人。
多实例子流程设置的办理人只能是:角色、部门、岗位等这种用户组,不能是具体的人员。
如果是具体的人员,我觉得使用子流程就显得毫无意义,比如上面的流程图中,先不说是否符合需求,单说每个子流程都是确定的人来执行的话,用多实例用户任务来实现是一样的。
设定了这个规则以后,基本的实现就和多实例用户任务差不多了:
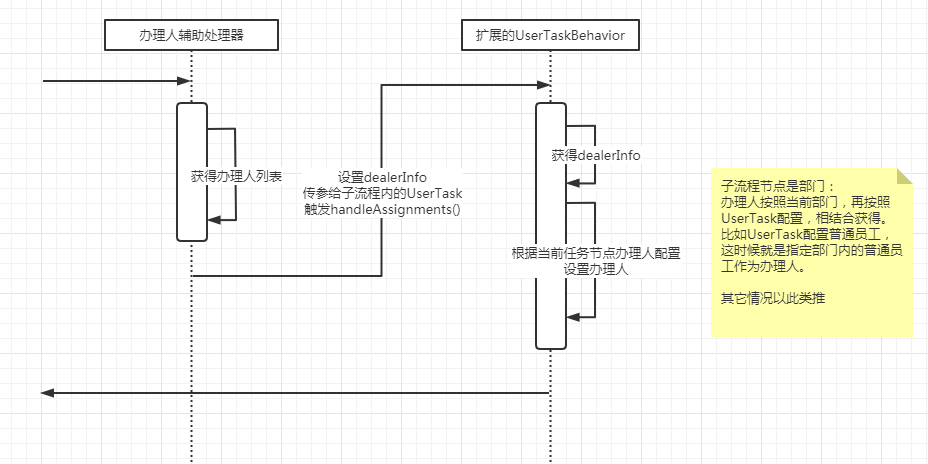
2. 会签结束时,投票结果如何统计
首先,多实例用户任务时,投票的结果以“SIGN_VOTE_TASKID”来表示,这在多实例子流程时,就无法使用这种规则了。
这时候,可以使以“SIGN_VOTE_EXECUTIONID”表示。其实多实例子流程生成的每一个流程实例,其ExecutionId在执行期间是不变的,这样就能够保证每一次用户任务的操作,可以改变自己所属子流程的投票结果。
然后,每一个子流程执行完毕时,如何判断会签是否达到结束条件。这个判断的关键点在于“SIGN_VOTE_EXECUTIONID”的设置。
如果像UserTask一样,在每次Complete时,就设置。那么每一次子流程执行完毕,需要进行Completion Condition判断时,如果只是判断是否包含关键字“SIGN_VOTE_”,统计到的子流程的投票结果可能是未执行完毕的。
这时候怎么办?我觉得可以通过判断loopCounter参数是否存在,来判断子流程是否结束完毕,然后再通过获得“SIGN_VOTE_”作为投票结果。
还有一种方式,就是在流程结束事件内对“SIGN_VOTE_”进行设置。当然,每一次流程结束事件,还需要判断这个流程是否是子流程,如果是,再设置。否则的话,正常的主流程结束了也是会抛出这个事件的。
最后,以上的方案,我没有想过子流程再嵌套子流程的情况,太复杂了。也没有想过调用子流程的情况,因为调用子流程的机制不太一样,也是比较复杂。
全是文字,因为这只是个想法,我还没有实现呢。如果以上有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6 - 获得下一节点 | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
55个
打了个疫苗,找个借口歇一下。面试太多,再找个借口歇一下。没啥内容可写,继续歇一下。
躺着是最舒服的。好了,言归正传(本文基于Flowable6.6测试通过)。
有的集成了流程引擎的系统提供流程执行预测功能,说白了就是按照流程图提前跑一下,看看会到达哪个节点。
要实现这个功能,大概的步骤如下:
- 获得当前的节点。
- 获得当前节点的出口连接线。
- 按照连接线获得下一个节点。
- 如果是非用户任务节点,则继续重复第2和第3步。
- 返回最终的用户任务节点。
从编码上来说,麻烦的点在于:
- 连接线的目标节点。
- 连接线如果有条件,如何判断是否执行。
其实以上的点都可以通过Flowable的源码得到答案。还是通过TaskService的complete()方法入手,大概的代码查找过程如下:
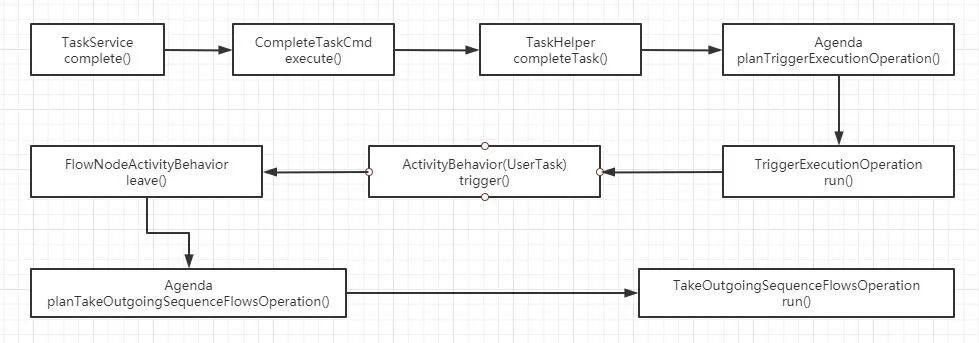
在最后一个run()方法中,有一段关键的代码:
if (currentFlowElement instanceof FlowNode) {
handleFlowNode((FlowNode) currentFlowElement);
} else if (currentFlowElement instanceof SequenceFlow) {
handleSequenceFlow();
}
其实大概的过程就是,complete用户任务时,会触发UserTask Behavior中的leave()方法离开此节点,从而触发寻找出口的连接线,就能找到我们所需的代码了:
// Determine which sequence flows can be used for leaving
List<SequenceFlow> outgoingSequenceFlows = new ArrayList<>();
for (SequenceFlow sequenceFlow : flowNode.getOutgoingFlows()) {
String skipExpressionString = sequenceFlow.getSkipExpression();
if (!SkipExpressionUtil.isSkipExpressionEnabled(skipExpressionString, sequenceFlow.getId(), execution, commandContext)) {
//关键的在这里
if (!evaluateConditions
|| (evaluateConditions && ConditionUtil.hasTrueCondition(sequenceFlow, execution) && (defaultSequenceFlowId == null || !defaultSequenceFlowId.equals(sequenceFlow.getId())))) {
outgoingSequenceFlows.add(sequenceFlow);
}
} else if (flowNode.getOutgoingFlows().size() == 1 || SkipExpressionUtil.shouldSkipFlowElement(
skipExpressionString, sequenceFlow.getId(), execution, commandContext)) {
// The 'skip' for a sequence flow means that we skip the condition, not the sequence flow.
outgoingSequenceFlows.add(sequenceFlow);
}
}
最关键的代码就是这个了:
ConditionUtil.hasTrueCondition(sequenceFlow, execution)
上面这段代码就是判断连接线是否符合执行条件,是不是会流转到这条连接线的所连接的节点。至于参数execution,其实是为了使用其携带的参数计算表达式。
麻烦的点基本解决了,于是我简单的写了一段代码做测试:
private FlowElement getTargetFlowElement(Execution execution, FlowElement sourceFlowElement) {
//遇到下一个节点是UserTask就返回
FlowElement flowElement = null;
if (sourceFlowElement instanceof FlowNode) {
//当前节点必须是FlowNode才做处理,比如UserTask或者GateWay
FlowNode thisFlowNode = (FlowNode) sourceFlowElement;
if (thisFlowNode.getOutgoingFlows().size() == 1) {
//如果只有一条连接线,直接找这条连接线的出口节点,然后继续递归获得接下来的节点
SequenceFlow sequenceFlow = thisFlowNode.getOutgoingFlows().get(0);
FlowElement targetFlowElement = sequenceFlow.getTargetFlowElement();
if (targetFlowElement instanceof UserTask) {
flowElement = targetFlowElement;
} else {
flowElement = getTargetFlowElement(execution, targetFlowElement);
}
} else if (thisFlowNode.getOutgoingFlows().size() > 1) {
//如果有多条连接线,遍历连接线,找出一个连接线条件执行为True的,获得它的出口节点
for (SequenceFlow sequenceFlow : thisFlowNode.getOutgoingFlows()) {
boolean result = true;
if (StrUtil.isNotBlank(sequenceFlow.getConditionExpression())) {
//计算连接线上的表达式
Expression expression = processEngineConfiguration.getExpressionManager().createExpression(sequenceFlow.getConditionExpression());
Condition condition = new UelExpressionCondition(expression);
result = condition.evaluate(sequenceFlow.getId(), (ExecutionEntity) execution);
}
if (result) {
FlowElement targetFlowElement = sequenceFlow.getTargetFlowElement();
if (targetFlowElement instanceof UserTask) {
flowElement = targetFlowElement;
} else {
flowElement = getTargetFlowElement(execution, targetFlowElement);
}
}
}
}
}
return flowElement;
}
差不多,简单的流程图,比如下面这个,还是能够正常获得的:
以上,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6 - 获得待办 | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
55个
十年前,同时带三个项目,还能记清楚各种细节。十年后,记事本翻页,就已经记不清楚上一页内容了。
花有重开日,人无再少年。
相逢拌酩酊,何必备芳鲜。
距离上一篇好长时间了,今天有点力气,简单说说Flowable的待办吧。
其实所谓的待办,归根到底就是通过查询act_ru_identitylink这张表得到的。
如果使用它的API接口来实现,简单的代码如下:
taskService.createTaskQuery().taskCandidateUser().list();
taskService.createTaskQuery().taskCandidateGroup().list();
taskService.createTaskQuery().taskAssignee().list();
但是使用这些接口来查询,太过理想化,很难适应复杂的业务场景。
如果使用自定义组(角色、部门、岗位等)分配办理人,然后查出当前登录人员所有的待办信息,并且还要分页展示的时候,用以上的接口就显得过于复杂。
所以,在单体项目中,将查询归根到数据库层面,通过自定义SQL查询是再好不过的。
比如角色,就可以使用下面的SQL进行查询:
SELECT task_.*, execution_.BUSINESS_KEY_ FROM act_ru_task task_
INNER JOIN act_ru_execution execution_ ON task_.PROC_INST_ID_ = execution_.ID_
INNER JOIN act_ru_identitylink identitylink_ ON task_.ID_ = identitylink_.TASK_ID_
WHERE identitylink_.TYPE_ = 'ROLE' AND identitylink_.GROUP_ID_ IN (@roleIds)
如果想查询这个人属于各种自定义组的待办,就可以:
SELECT task_.*, execution_.BUSINESS_KEY_ FROM act_ru_task task_
INNER JOIN act_ru_execution execution_ ON task_.PROC_INST_ID_ = execution_.ID_
INNER JOIN act_ru_identitylink identitylink_ ON task_.ID_ = identitylink_.TASK_ID_
WHERE identitylink_.TYPE_ = 'ROLE' AND identitylink_.GROUP_ID_ IN (@roleIds)
UNION
SELECT task_.*, execution_.BUSINESS_KEY_ FROM act_ru_task task_
INNER JOIN act_ru_execution execution_ ON task_.PROC_INST_ID_ = execution_.ID_
INNER JOIN act_ru_identitylink identitylink_ ON task_.ID_ = identitylink_.TASK_ID_
WHERE identitylink_.TYPE_ = 'DEPT' AND identitylink_.GROUP_ID_ IN (@roleIds)
通过自定义SQL进行查询,可以适应绝大多数业务场景,缺点就是需要熟悉Flowable的数据表结构。
上面的查询语句,只是解决了流程任务的查询问题。但是真正的待办,显示的是业务数据,我个人常用的有两种实现方法:
- 每种业务数据通过不同的页面独立展示。这种实现方法,只需要在查询的时候关联指定的业务表即可。实现起来比较简单,但是待办无法集中展示。
- 将每种业务数据的待办信息都抽象为通用的组成方式。比如待办都有:标题、创建时间、办理人、工单号等等。通过流程事件触发或其它拦截方式,在流程启动、任务创建时生成这部分信息,然后结合上面的查询SQL使用。这种实现起来较为复杂,而且怎么抽象是个问题,但是待办可以集中展示。
以上是单体项目的实现方式,分布式系统更加麻烦一些,我个人主要尝试过两种办法来实现:
- 回写。在每个调用方存放一份副表,使用事件触发的方式,将流程数据回写,从而实现待办的查询,可以轻松的和业务数据合并展示。缺点也是同上,集中展示就无法实现了,而且极端情况下会遇到数据一致性问题。
- 在流程服务中存储抽象后的通用信息。普通的待办可以集中读取,但是因为业务数据分布在自己的数据库中,所以根本无法进行联合查询。
到现在为止,关于流程待办的经验就这么多,欢迎分享和指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 - Agenda到底是个什么东西? | 字痕随行
原创 字痕随行 字痕随行
收录于合集
#流程引擎 58 个
#Flowable 2 个
之前梳理过命令和责任链大概是个什么东西,简单的说过Flowable内部运行的过程?
详细可以戳这里:
今天主要说两点:
- 更详细的说说Flowable的命令链。
- 更详细的说说Agenda到底是个什么?
首先,从初始化入手:
org.flowable.engine.impl.cfg.ProcessEngineConfigurationImpl
有一段函数执行了Command相关的初始化方法:
@Override
public void initCommandExecutors() {
initDefaultCommandConfig();
initSchemaCommandConfig();
initCommandInvoker();
initCommandInterceptors();
initCommandExecutor();
}
从最后的initCommandExecutor()入手,看看调用Api接口时,传入的Command到底是怎么运行的:
public void initCommandExecutor() {
if (commandExecutor == null) {
//先找头,这就是执行的开始
CommandInterceptor first = initInterceptorChain(commandInterceptors);
commandExecutor = new CommandExecutorImpl(getDefaultCommandConfig(), first);
}
}
first是什么?其实就是commandInterceptors里面的第一个执行器,如果这中间没有自定义过CommandInterceptor,那第一个执行的就是:
public Collection<? extends CommandInterceptor> getDefaultCommandInterceptors() {
if (defaultCommandInterceptors == null) {
List<CommandInterceptor> interceptors = new ArrayList<>();
//这就是那第一个
interceptors.add(new LogInterceptor());
//省略代码若干...
}
return defaultCommandInterceptors;
}
而最后一个就是:
public void initCommandInterceptors() {
if (commandInterceptors == null) {
commandInterceptors = new ArrayList<>();
if (customPreCommandInterceptors != null) {
commandInterceptors.addAll(customPreCommandInterceptors);
}
//这里决定的是第一个
commandInterceptors.addAll(getDefaultCommandInterceptors());
if (customPostCommandInterceptors != null) {
commandInterceptors.addAll(customPostCommandInterceptors);
}
//这里就是最后一个
commandInterceptors.add(commandInvoker);
}
}
从名字上大概来看,除了最后一个之外,都是用来做辅助的。而最后一个Invoker才是真正的执行器。
接下来,通过CommandInvoker就可以看一看一个Command到底是怎么执行的。同时,也可以看一看Agenda到底是个什么。
直接上内部代码:
@Override
@SuppressWarnings("unchecked")
public <T> T execute(final CommandConfig config, final Command<T> command, CommandExecutor commandExecutor) {
final CommandContext commandContext = Context.getCommandContext();
FlowableEngineAgenda agenda = CommandContextUtil.getAgenda(commandContext);
if (commandContext.isReused() && !agenda.isEmpty()) { // there is already an agenda loop being executed
return (T) command.execute(commandContext);
} else {
// Execute the command.
// This will produce operations that will be put on the agenda.
agenda.planOperation(new Runnable() {
@Override
public void run() {
commandContext.setResult(command.execute(commandContext));
}
});
// Run loop for agenda
executeOperations(commandContext);
//此处省略代码若干...
//只看上面核心的
return (T) commandContext.getResult();
}
}
直接看else就行了,未特殊设置情况下isReused是false。
可以看到,所有的命令最终都是交给Agenda去执行的,在创建一个Agenda执行计划之后,又不停的去循环执行Agenda里面的执行计划。
所以,最终就落到题目那个问题:Agenda到底是个什么东西?
最后,看看Agenda到底是个什么东西。
结论,Agenda就是个链表:
protected LinkedList<Runnable> operations = new LinkedList<>();
所以,理论上来说,Flowable的执行,就是遍历这张链表,执行存储于这张链表内的Runnable对象。
这算扒完了整个过程,但是我还是有一些疑问的:
本来我以为它这样设计,可能是因为能够异步执行,这样可以有序执行,不过代码显示的是同步执行,所以肯定不是这个原因。
那只可能是为了封装和解耦了,毕竟把一个一个链条封装好,然后在需要复用的时候,直接压入链表,然后它就会按照设计有序执行,最终得到需要的结果,就很符合它的设计思想。
好了,以上的个人观点,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 - 一种同步返回用户任务的想法 | 字痕随行
原创 字痕随行 字痕随行
收录于合集
#Flowable 2 个
#流程引擎 58 个
为什么之前重新梳理了一下Agenda?
主要是因为有人问过我,为什么调用TaskService.complete()方法没有返回值。
如果无法获得返回值,就不知道任务到达哪个节点,可能无法满足某些业务场景。
当时,我想可能是因为基于流程引擎进行流转,无法预测最终会流转到什么节点。
可是,后来我觉得不对,如果节点不需要进行异步流转,所有的处理都是同步的,按理来说应该是可以获得的。
所以,才有了之前的那篇梳理。也就找到了根本原因,这是由于Flowable的运行原理导致的。
Flowable基于链表执行命令链,无法在Complete Command里面嵌入查询最终用户任务的语句,原因如下图:
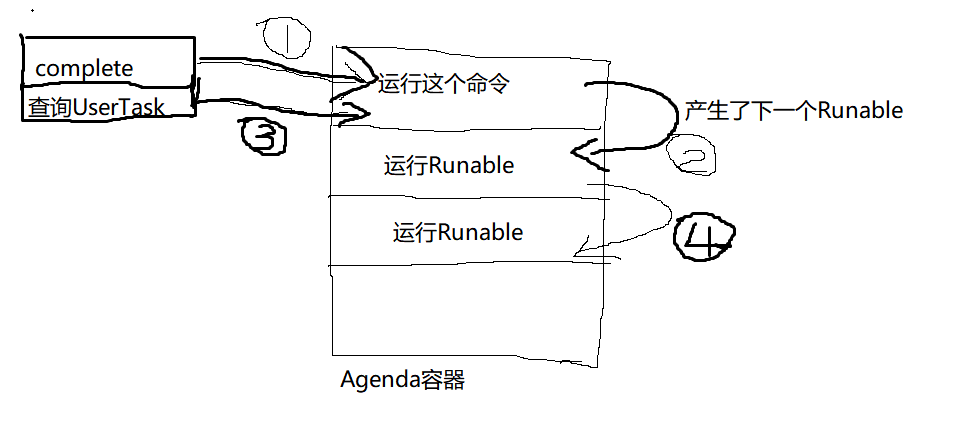
画的粗糙了点,但是意思差不多了,就是在查询UserTask命令之后,Flowable还会执行一堆命令链,然后才能停止在UserTask节点。
所以想在事务内查询不太可能,除非自定义一个拦截器,但是自定义拦截器是不是能够返回结果,还是个问题。
所以,我尝试了一种方案,没经过生产环境测试,只是以供参考(只限定于节点都是同步处理的情况)。
主要的过程如下:
- 声明一个ThreadLocal,用来存储在当前线程中生成的UserTask。
- 捕捉UserTask的Complete和Create事件,更新ThreadLocal中的UserTask。
- 在同步执行完TaskService.complete()后,返回ThreadLocal中的UserTask。
整个过程,应该是可以包裹在事务中的,应该不会出现线程安全问题。
ThreadLocal代码如下:
1public class ThreadLoaclCache {
2
3 private final static ThreadLocal<ThreadLoaclCache> threadLocalCache = new ThreadLocal<>();
4
5 private Set<String> taskIds;
6
7 public ThreadLoaclCache() {
8 this.taskIds = new HashSet<>();
9 }
10
11 public Set<String> getTaskIds() {
12 return taskIds;
13 }
14
15 public void setTaskIds(Set<String> taskIds) {
16 this.taskIds = taskIds;
17 }
18
19 public static ThreadLoaclCache getInstance() {
20 return threadLocalCache.get();
21 }
22
23 public static Set<String> addTaskIds(String taskId) {
24 ThreadLoaclCache threadLoaclCache = threadLocalCache.get();
25 if (null == threadLoaclCache) {
26 threadLoaclCache = new ThreadLoaclCache();
27 threadLocalCache.set(threadLoaclCache);
28 }
29 threadLoaclCache.getTaskIds().add(taskId);
30 return threadLoaclCache.getTaskIds();
31 }
32
33 public static void removeTaskIds(String taskId) {
34 ThreadLoaclCache threadLoaclCache = threadLocalCache.get();
35 if (null == threadLoaclCache) {
36 threadLoaclCache = new ThreadLoaclCache();
37 threadLocalCache.set(threadLoaclCache);
38 }
39 threadLoaclCache.getTaskIds().remove(taskId);
40 }
41}
TaskComplete和TaskCreate的事件处理如下:
1public class TaskCreateEventListenerHandleImpl implements EventListenerHandle {
2
3 @Override
4 public void onEvent(FlowableEvent event) {
5 if (event instanceof FlowableEntityEvent) {
6 FlowableEntityEvent entityEvent = (FlowableEntityEvent) event;
7 TaskEntity entity = (TaskEntity) entityEvent.getEntity();
8 ThreadLoaclCache.addTaskIds(entity.getId());
9 }
10 }
11}
12
13public class TaskCompleteEventListenerHandleImpl implements EventListenerHandle {
14
15 @Override
16 public void onEvent(FlowableEvent event) {
17 if (event instanceof FlowableEntityEvent) {
18 FlowableEntityEvent entityEvent = (FlowableEntityEvent) event;
19 TaskEntity entity = (TaskEntity) entityEvent.getEntity();
20 ThreadLoaclCache.removeTaskIds(entity.getId());
21 }
22 }
23}
然后就可以测试一下了:
1@ResponseBody
2@RequestMapping(value = "customCompleteTask/{taskId}")
3public List<String> customCompleteTask(@PathVariable("taskId") String taskId) {
4 taskService.complete(taskId);
5 return new ArrayList<>(ThreadLoaclCache.getInstance().getTaskIds());
6}
以上,一种设想,纯粹是闲得没事干。
如果有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Flowable6 - 自定义缓存(1) | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
53个
我本来以为自定义缓存是个很容易的事情,毕竟接口是已经存在的,所以理论上只要实现接口,然后完成序列化和反序列化就可以了。
而实际上,折腾了一周多的时间,最后也不是真正意义上的成功。
先上结论:分析了一下源码,发现从Activiti6开始,缓存的类有了些许改变,加入了BpmnModel和Process。
public class ProcessDefinitionCacheEntry implements Serializable {
private static final long serialVersionUID = 6833801933658529070L;
protected ProcessDefinition processDefinition;
protected BpmnModel bpmnModel;
protected Process process;
public ProcessDefinitionCacheEntry(ProcessDefinition processDefinition, BpmnModel bpmnModel, Process process) {
this.processDefinition = processDefinition;
this.bpmnModel = bpmnModel;
this.process = process;
}
}
问题就在这两个类上面,BpmnModel和Process并不支持序列化:
public class BpmnModel {
}
public class Process extends BaseElement implements FlowElementsContainer, HasExecutionListeners {
}
它们并没有实现Serializable接口,这就导致反序列化的时候会出现很多意想不到的问题,所以不可能愉快的使用Redis了。
在Github上已经有人问过这个问题,地址见:
https://github.com/flowable/flowable-engine/issues/481
这个issues至今仍旧是open状态。所以我觉得,可以洗洗睡了。
上面就是结论了,如果想了解更多一点,可以继续往下看。
缓存是怎么写入的,其实可以看一下源码,关键在于BpmnDeployer这个类。
看这个类的源码,按照以下顺序来:
deploy(DeploymentEntity deployment, Map<String, Object> deploymentSettings)
->
bpmnParse.execute();
->
addProcessDefinitionToCache(processDefinition, bpmnModelMap, processEngineConfiguration, commandContext);
最开始的时候,我尝试着将流程定义的XML字符串缓存到Redis,然后再取出来,使用BpmnXMLConverter转换成BpmnModel对象,然后能够变相生成ProcessDefinitionCacheEntry。
很不幸的是,直接转换出的BpmnModel缺少很多的属性。如果去阅读源码就会发现,在bpmnParse.execute()中,不但convert出了BpmnModel,在之后还做了一些额外的工作:
bpmnModel.setSourceSystemId(sourceSystemId);
//这个对象不能为空,否则发布的时候报错
bpmnModel.setEventSupport(new FlowableEventSupport());
//这里用每一个流程节点的bpmnParserHandler进行了处理
transformProcessDefinitions();
最麻烦的就是它用了bpmnParserHandler去处理节点,然后回写给了BpmnModel的Process。
也就是,直接从XML字符串转换出来的BpmnModel天生缺点东西,当启动流程的时候会报异常,因为Process缺东西。
然后,我就死心了。除了上面的原因之外,另外一个原因就是,如果不使用进程外缓存,我觉得应该不会对分布式造成太大影响。
比如,部署了两个Flowable Engine,它们都是用的默认缓存,即一个HashMap。
当需要获得流程定义时,就会先去缓存中使用processDefinitionId获得,如果缓存中不存在该流程定义,则会从数据库中读取,然后同步缓存,而这个processDefinitionId其实是每次发布才会生成的。
这就是说:
1. 在Flowable Engine A中进行了流程定义,并且发布。Flowable Engine B中的缓存不存在,如果这时候启动流程,会将数据库中新的流程定义同步到B的缓存中。
2. 如果需要修改流程定义,直接读取的是act_de_model表中的信息,发布的时候会生成新的processDefinitionId,应该也不会造成差异。
所以,我觉得应该可以正常使用,不过这块我还没时间测试,建议完全测试后再上生产。
如果非得使用Redis作为缓存,可以看看下一章。在下一章里,我会变着法子实现一下,权当一个参考。
以上,就是本次的内容,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6 - 自定义缓存(2) | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
53个
接上一篇的自定义缓存,这次具体说说如何自定义缓存,以及使用了Redis后,我是如何能够让它正常运行。
首先,自定义缓存需要实现一个接口,代码如下:
public class ProcessDefinitionRedisCache implements DeploymentCache<ProcessDefinitionCacheEntry> {
@Override
public ProcessDefinitionCacheEntry get(String id) {
}
@Override
public boolean contains(String id) {
}
@Override
public void add(String id, ProcessDefinitionCacheEntry processDefinitionCacheEntry) {
}
@Override
public void remove(String id) {
}
@Override
public void clear() {
}
@Override
public Collection<ProcessDefinitionCacheEntry> getAll() {
}
@Override
public int size() {
}
}
然后,需要使用自定义的缓存替代原生的缓存:
configuration.setProcessDefinitionCache(new ProcessDefinitionRedisCache());
上一篇说过,即使实现了这个接口,但是由于BpmnModel和Process不能简单的序列化和反序列化,导致无法正常运行。
我试了很多办法,最后只能每次取缓存的时候调用ParsedDeployment来实现。
首先,加入缓存的时候,把Deployment加入缓存,因为Deployment支持序列化,并且可以一同将流程定义的XML加入缓存,就像这样:
@Override
public void add(String id, ProcessDefinitionCacheEntry processDefinitionCacheEntry) {
redisTemplate.opsForValue().set(id + "_def", processDefinitionCacheEntry.getProcessDefinition());
DeploymentEntity deployment = CommandContextUtil.getDeploymentEntityManager().findById(processDefinitionCacheEntry.getProcessDefinition().getDeploymentId());
redisTemplate.opsForValue().set(id + "_dly", deployment);
}
然后,在取出缓存的时候,调用ParsedDeployment来获得BpmnModel和Process。
@Override
public ProcessDefinitionCacheEntry get(String id) {
Object objectDef = redisTemplate.opsForValue().get(id + "_def");
JSONObject jsonDef = (JSONObject) objectDef;
Object objectDeployment = redisTemplate.opsForValue().get(id + "_dly");
JSONObject jsonDeployment = (JSONObject) objectDeployment;
ProcessDefinitionEntity processDefinitionEntity = jsonDef.toJavaObject(ProcessDefinitionEntityImpl.class);
DeploymentEntity deployment = jsonDeployment.toJavaObject(DeploymentEntityImpl.class);
ParsedDeploymentBuilderFactory factory = CommandContextUtil.getProcessEngineConfiguration().getParsedDeploymentBuilderFactory();
ParsedDeployment parsedDeployment = factory
.getBuilderForDeploymentAndSettings(deployment, null)
.build();
BpmnModel bpmnModel = parsedDeployment.getBpmnModelForProcessDefinition(parsedDeployment.getAllProcessDefinitions().get(0));
Process process = parsedDeployment.getProcessModelForProcessDefinition(parsedDeployment.getAllProcessDefinitions().get(0));
ProcessDefinitionCacheEntry cacheEntry = new ProcessDefinitionCacheEntry(processDefinitionEntity, bpmnModel, process);
return cacheEntry;
}
这样的话,能够保证BpmnModel和Process是完整的。我测试了一下,倒是没发现什么问题。
但是,我不建议这么做,因为每一次都相当于重新解析XML,相当于重新执行流程发布时的耗时操作,失去了缓存的意义。
这一篇我觉得只是个总结,没有什么实际应用的价值,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.6-再试自定义缓存 | 字痕随行
很久之前,我写过两篇文章来介绍Flowable的自定义缓存,然后完败。
这次再折腾这个,起因是群里的大佬告诉我可以用编辑字节码的方式来实现,我就寻了个空又重新折腾了一下。
最开始尝试了字节码的方式搞不定,实在没时间折腾了,所以使用笨办法绕了绕,在这期间遇到的坑点如下:
- 官方在一些属性上标识了@JsonIgnore,但是反序列化之后的对象缺需要这些属性不为Null。
- 某些Behavior没有默认的构造函数,导致反序列化失败,比如UserTaskActivityBehavior。
- 有很多循环引用,比如FlowElement,循环引用直接导致堆栈溢出。
- getter、setter不规范,有的包含了业务逻辑,返回的类型和属性类型不一致。
- 官方用Object类型来恶心人。
所谓的笨办法:
- 把标识了@JsonIgnore但是却需要用到属性单独处理get、set。
- 重新定义一个子类,给子类定义默认构造函数,使用子类替代父类。
- 一般循环引用的官方都给了@JsonIgnore,所以使用Jackson来处理序列化和反序列化。
- 不要使用getter、setter来进行序列化,只使用原始属性。
- 对Object类型进行特殊处理。
关键的代码:
public class ProcessDefinitionRedisCache implements DeploymentCache<ProcessDefinitionCacheEntry> {
@Override
public ProcessDefinitionCacheEntry get(String id) {
RedisTemplate<String, Object> redisTemplate = BeanFactory.getBean("redisTemplate", RedisTemplate.class);
if (null == redisTemplate) {
return null;
}
Object objectDef = redisTemplate.opsForValue().get(id + "_def");
Object objectProc = redisTemplate.opsForValue().get(id + "_proc");
Object objectModel = redisTemplate.opsForValue().get(id + "_model");
Object objectSupport = redisTemplate.opsForValue().get(id + "_support");
Object objectBehavior = redisTemplate.opsForValue().get(id + "_behavior");
Object objectSource = redisTemplate.opsForValue().get(id + "_source");
Object objectTarget = redisTemplate.opsForValue().get(id + "_target");
if (null == objectDef || null == objectProc
|| null == objectModel || null == objectSupport
|| null == objectBehavior || null == objectSource
|| null == objectTarget) {
return null;
}
ProcessDefinitionEntity processDefinitionEntity = (ProcessDefinitionEntity) objectDef;
BpmnModel bpmnModel = (BpmnModel) objectModel;
Process process = (Process) objectProc;
FlowableEventSupport eventSupport = (FlowableEventSupport) objectSupport;
bpmnModel.setEventSupport(eventSupport);
//处理循环引用那些属性
setOther(objectBehavior, objectSource, objectTarget, process, bpmnModel);
ProcessDefinitionCacheEntry cacheEntry = new ProcessDefinitionCacheEntry(processDefinitionEntity, bpmnModel, process);
return cacheEntry;
}
@Override
public boolean contains(String id) {
}
@Override
public void add(String id, ProcessDefinitionCacheEntry processDefinitionCacheEntry) {
RedisTemplate<String, Object> redisTemplate = BeanFactory.getBean("redisTemplate", RedisTemplate.class);
if (null != redisTemplate) {
redisTemplate.opsForValue().set(id + "_def", processDefinitionCacheEntry.getProcessDefinition());
redisTemplate.opsForValue().set(id + "_proc", processDefinitionCacheEntry.getProcess());
redisTemplate.opsForValue().set(id + "_model", processDefinitionCacheEntry.getBpmnModel());
//下面都是需要特殊处理的属性
FlowableEventSupport eventSupport = (FlowableEventSupport) processDefinitionCacheEntry.getBpmnModel().getEventSupport();
redisTemplate.opsForValue().set(id + "_support", eventSupport);
Map<String, Object> mapBehavior = new HashMap<>();
Map<String, FlowElement> mapSource = new HashMap<>();
Map<String, FlowElement> mapTarget = new HashMap<>();
for (FlowElement flowElement : processDefinitionCacheEntry.getProcess().getFlowElements()) {
if (flowElement instanceof FlowNode) {
FlowNode flowNode = (FlowNode) flowElement;
mapBehavior.put(flowElement.getId(), flowNode.getBehavior());
}
if (flowElement instanceof SequenceFlow) {
SequenceFlow sequenceFlow = (SequenceFlow) flowElement;
mapSource.put(flowElement.getId(), sequenceFlow.getSourceFlowElement());
mapTarget.put(flowElement.getId(), sequenceFlow.getTargetFlowElement());
}
}
redisTemplate.opsForValue().set(id + "_behavior", mapBehavior);
redisTemplate.opsForValue().set(id + "_source", mapSource);
redisTemplate.opsForValue().set(id + "_target", mapTarget);
}
}
@Override
public void remove(String id) {
}
@Override
public void clear() {
}
@Override
public Collection<ProcessDefinitionCacheEntry> getAll() {
}
@Override
public int size() {
}
/**
* 要递归将循环引用的那些属性赋值,这是最麻烦的地方
* 测试的是一个简单的流程,所以只有这些节点,复杂点的我也不知道行不行啊
*/
private void setOther(Object objectBehavior, Object objectSource, Object objectTarget,
Process process, BpmnModel bpmnModel) {
Map<String, Object> mapBehavior = (Map<String, Object>) objectBehavior;
Map<String, FlowElement> mapSource = (Map<String, FlowElement>) objectSource;
Map<String, FlowElement> mapTarget = (Map<String, FlowElement>) objectTarget;
for (FlowElement flowElement : process.getFlowElements()) {
setFlowElement(flowElement, mapBehavior, mapSource, mapTarget);
}
for (Process proc : bpmnModel.getProcesses()) {
for (FlowElement flowElement : proc.getFlowElements()) {
setFlowElement(flowElement, mapBehavior, mapSource, mapTarget);
}
}
for (FlowElement flowElement : process.getFlowElementMap().values()) {
setFlowElement(flowElement, mapBehavior, mapSource, mapTarget);
}
for (Process proc : bpmnModel.getProcesses()) {
for (FlowElement flowElement : proc.getFlowElementMap().values()) {
setFlowElement(flowElement, mapBehavior, mapSource, mapTarget);
}
}
FlowNode flowNode = (FlowNode) process.getInitialFlowElement();
flowNode.setBehavior(mapBehavior.get(flowNode.getId()));
setFlowElement(flowNode, mapBehavior, mapSource, mapTarget);
}
private void setFlowElement(FlowElement flowElement,
Map<String, Object> mapBehavior,
Map<String, FlowElement> mapSource,
Map<String, FlowElement> mapTarget) {
if (flowElement instanceof FlowNode) {
FlowNode flowNode = (FlowNode) flowElement;
flowNode.setBehavior(mapBehavior.get(flowElement.getId()));
}
if (flowElement instanceof StartEvent) {
StartEvent startEvent = (StartEvent) flowElement;
for (SequenceFlow sequenceFlow : startEvent.getOutgoingFlows()) {
FlowElement source = mapSource.get(sequenceFlow.getId());
FlowElement target = mapTarget.get(sequenceFlow.getId());
sequenceFlow.setSourceFlowElement(source);
sequenceFlow.setTargetFlowElement(target);
if (null != target) {
setFlowElement(target, mapBehavior, mapSource, mapTarget);
}
}
}
if (flowElement instanceof UserTask) {
UserTask userTask = (UserTask) flowElement;
for (SequenceFlow sequenceFlow : userTask.getOutgoingFlows()) {
FlowElement source = mapSource.get(sequenceFlow.getId());
FlowElement target = mapTarget.get(sequenceFlow.getId());
sequenceFlow.setSourceFlowElement(source);
sequenceFlow.setTargetFlowElement(target);
if (null != target) {
setFlowElement(target, mapBehavior, mapSource, mapTarget);
}
}
}
if (flowElement instanceof SequenceFlow) {
SequenceFlow sequenceFlow = (SequenceFlow) flowElement;
FlowElement source = mapSource.get(sequenceFlow.getId());
FlowElement target = mapTarget.get(sequenceFlow.getId());
sequenceFlow.setSourceFlowElement(source);
sequenceFlow.setTargetFlowElement(target);
if (null != target) {
setFlowElement(target, mapBehavior, mapSource, mapTarget);
}
}
}
}
public class ExtUserTaskActivityBehavior extends UserTaskActivityBehavior {
private static final long serialVersionUID = 7711531472879418236L;
//要命的默认构造函数
public ExtUserTaskActivityBehavior() {
super(null);
}
public ExtUserTaskActivityBehavior(UserTask userTask) {
super(userTask);
}
}
但是,上面这一切都太麻烦了,并没有稳妥的解决问题,直到看到群友们一些关于序列化工具的讨论后,我尝试了一批序列化工具。
在先后尝试了Protostuff、FST、Kryo、Fury,尝试的结果如下:
- Protostuff直接Stack Overflow,估计还是因为循环引用的问题。
- FST能够进行序列化,但是有一个致命的问题就是Object类型,它无法反序列化。
- Kryo能够成功,它和FST的原理差不多,区别在于Kryo可以处理Object类型,能够获取其真正的类型。
- Fury能够成功,看官方的性能对比图要比Kryo和FST快,但是其版本还是Snapshot。
现在貌似能够进行序列化和反序列化了,但是还要尝试一下是否能够支撑流程运行,我要先去试验一下,本章只给出关键的代码,有兴趣的同学可以自行尝试下。
Kryo要进行一些设置:
//不需要注册类,让kryo自己决定
kryo.setRegistrationRequired(false);
//无需构造函数
kryo.setInstantiatorStrategy(new DefaultInstantiatorStrategy(new StdInstantiatorStrategy()));
//启用引用追踪,这涉及到kryo的机制,可以避免StackOverflow
kryo.setReferences(true);
Fury也要进行一些设置:
Fury fury = Fury.builder().withLanguage(Language.JAVA)
.withRefTracking(true)
// Allow to deserialize objects unknown types,
// more flexible but less secure.
.withSecureMode(false)
.build();
//不要直接用fury.deserializeJavaObject()
Object obj = fury.deserialize(bytes);
cacheEntry = (ProcessDefinitionCacheEntry) obj;
以上,就这样吧,耗尽了精力,如果有错误,欢迎探讨和指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.6-再谈自定义缓存 | 字痕随行
很久之前,我写过两篇文章来介绍Flowable的自定义缓存,然后完败。
这次再折腾这个,起因是群里的大佬告诉我可以用编辑字节码的方式来实现,我就寻了个空又重新折腾了一下。
先说我折腾之后的结论:
- 字节码的方式我实在搞不定,需要各种调试,实在没时间搞了。
- 仍旧不建议使用进程外缓存,官方挖的坑也太多了些。
- 这次不需要重新解析,但是需要递归处理,再加上序列化和反序列化,性价比贼差。
我遇到的坑点:
- 官方在一些属性上标识了@JsonIgnore,但是反序列化之后的对象缺需要这些属性不为Null。
- 某些Behavior没有默认的构造函数,导致反序列化失败,比如UserTaskActivityBehavior。
- 有很多循环引用,比如FlowElement,循环引用直接导致堆栈溢出。
- getter、setter不规范,有的包含了业务逻辑,返回的类型和属性类型不一致。
- 官方用Object类型来恶心人。
我解决的办法:
- 把标识了@JsonIgnore但是却需要用到属性单独处理get、set。
- 重新定义一个子类,给子类定义默认构造函数,使用子类替代父类。
- 一般循环引用的官方都给了@JsonIgnore,所以使用Jackson来处理序列化和反序列化。
- 不要使用getter、setter来进行序列化,只使用原始属性。
- 对Object类型进行特殊处理。
下面是一些关键的代码(非生产代码,凑合参考吧):
/** Redis配置 **/
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 配置连接工厂
template.setConnectionFactory(factory);
//使用Jackson作为序列化和反序列化工具
Jackson2JsonRedisSerializer<Object> jsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
objectMapper.configure(MapperFeature.USE_GETTERS_AS_SETTERS, false);
objectMapper.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS, false);
objectMapper.setVisibility(GETTER, JsonAutoDetect.Visibility.NONE);
objectMapper.setVisibility(SETTER, JsonAutoDetect.Visibility.NONE);
objectMapper.setVisibility(FIELD, JsonAutoDetect.Visibility.ANY);
jsonRedisSerializer.setObjectMapper(objectMapper);
//FlowableEventType这个类是个枚举,需要特殊处理
SimpleModule simpleModule = new SimpleModule();
simpleModule.addKeyDeserializer(FlowableEventType.class, new KeyDeserializer() {
@Override
public Object deserializeKey(String s, DeserializationContext deserializationContext) throws IOException {
//因为是测试所以偷懒了,也懒得改了
return FlowableEngineEventType.TASK_CREATED;
}
});
objectMapper.registerModule(simpleModule);
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(jsonRedisSerializer);
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(jsonRedisSerializer);
return template;
}
@Configuration
public class FlowableConfig {
@Primary
@Bean(name = "processEngineConfiguration")
public SpringProcessEngineConfiguration getSpringProcessEngineConfiguration(@Qualifier("dataSource") DataSource dataSource, @Qualifier("transactionManager") DataSourceTransactionManager transactionManager) {
SpringProcessEngineConfiguration configuration = new SpringProcessEngineConfiguration();
configuration.setDataSource(dataSource);
configuration.setTransactionManager(transactionManager);
configuration.setDatabaseSchemaUpdate("true");
configuration.setAsyncExecutorActivate(true);
configuration.setActivityFontName("宋体");
configuration.setLabelFontName("宋体");
//使用自定义的UserTaskBehavior
configuration.setActivityBehaviorFactory(new ExtActivityBehaviorFactory());
//使用进程外缓存
configuration.setProcessDefinitionCache(new ProcessDefinitionRedisCache());
return configuration;
}
}
public class ProcessDefinitionRedisCache implements DeploymentCache<ProcessDefinitionCacheEntry> {
@Override
public ProcessDefinitionCacheEntry get(String id) {
RedisTemplate<String, Object> redisTemplate = BeanFactory.getBean("redisTemplate", RedisTemplate.class);
if (null == redisTemplate) {
return null;
}
Object objectDef = redisTemplate.opsForValue().get(id + "_def");
Object objectProc = redisTemplate.opsForValue().get(id + "_proc");
Object objectModel = redisTemplate.opsForValue().get(id + "_model");
Object objectSupport = redisTemplate.opsForValue().get(id + "_support");
Object objectBehavior = redisTemplate.opsForValue().get(id + "_behavior");
Object objectSource = redisTemplate.opsForValue().get(id + "_source");
Object objectTarget = redisTemplate.opsForValue().get(id + "_target");
if (null == objectDef || null == objectProc
|| null == objectModel || null == objectSupport
|| null == objectBehavior || null == objectSource
|| null == objectTarget) {
return null;
}
ProcessDefinitionEntity processDefinitionEntity = (ProcessDefinitionEntity) objectDef;
BpmnModel bpmnModel = (BpmnModel) objectModel;
Process process = (Process) objectProc;
FlowableEventSupport eventSupport = (FlowableEventSupport) objectSupport;
bpmnModel.setEventSupport(eventSupport);
//处理循环引用那些属性
setOther(objectBehavior, objectSource, objectTarget, process, bpmnModel);
ProcessDefinitionCacheEntry cacheEntry = new ProcessDefinitionCacheEntry(processDefinitionEntity, bpmnModel, process);
return cacheEntry;
}
@Override
public boolean contains(String id) {
}
@Override
public void add(String id, ProcessDefinitionCacheEntry processDefinitionCacheEntry) {
RedisTemplate<String, Object> redisTemplate = BeanFactory.getBean("redisTemplate", RedisTemplate.class);
if (null != redisTemplate) {
redisTemplate.opsForValue().set(id + "_def", processDefinitionCacheEntry.getProcessDefinition());
redisTemplate.opsForValue().set(id + "_proc", processDefinitionCacheEntry.getProcess());
redisTemplate.opsForValue().set(id + "_model", processDefinitionCacheEntry.getBpmnModel());
//下面都是需要特殊处理的属性
FlowableEventSupport eventSupport = (FlowableEventSupport) processDefinitionCacheEntry.getBpmnModel().getEventSupport();
redisTemplate.opsForValue().set(id + "_support", eventSupport);
Map<String, Object> mapBehavior = new HashMap<>();
Map<String, FlowElement> mapSource = new HashMap<>();
Map<String, FlowElement> mapTarget = new HashMap<>();
for (FlowElement flowElement : processDefinitionCacheEntry.getProcess().getFlowElements()) {
if (flowElement instanceof FlowNode) {
FlowNode flowNode = (FlowNode) flowElement;
mapBehavior.put(flowElement.getId(), flowNode.getBehavior());
}
if (flowElement instanceof SequenceFlow) {
SequenceFlow sequenceFlow = (SequenceFlow) flowElement;
mapSource.put(flowElement.getId(), sequenceFlow.getSourceFlowElement());
mapTarget.put(flowElement.getId(), sequenceFlow.getTargetFlowElement());
}
}
redisTemplate.opsForValue().set(id + "_behavior", mapBehavior);
redisTemplate.opsForValue().set(id + "_source", mapSource);
redisTemplate.opsForValue().set(id + "_target", mapTarget);
}
}
@Override
public void remove(String id) {
}
@Override
public void clear() {
}
@Override
public Collection<ProcessDefinitionCacheEntry> getAll() {
}
@Override
public int size() {
}
/**
* 要递归将循环引用的那些属性赋值,这是最麻烦的地方
* 测试的是一个简单的流程,所以只有这些节点,复杂点的我也不知道行不行啊
*/
private void setOther(Object objectBehavior, Object objectSource, Object objectTarget,
Process process, BpmnModel bpmnModel) {
Map<String, Object> mapBehavior = (Map<String, Object>) objectBehavior;
Map<String, FlowElement> mapSource = (Map<String, FlowElement>) objectSource;
Map<String, FlowElement> mapTarget = (Map<String, FlowElement>) objectTarget;
for (FlowElement flowElement : process.getFlowElements()) {
setFlowElement(flowElement, mapBehavior, mapSource, mapTarget);
}
for (Process proc : bpmnModel.getProcesses()) {
for (FlowElement flowElement : proc.getFlowElements()) {
setFlowElement(flowElement, mapBehavior, mapSource, mapTarget);
}
}
for (FlowElement flowElement : process.getFlowElementMap().values()) {
setFlowElement(flowElement, mapBehavior, mapSource, mapTarget);
}
for (Process proc : bpmnModel.getProcesses()) {
for (FlowElement flowElement : proc.getFlowElementMap().values()) {
setFlowElement(flowElement, mapBehavior, mapSource, mapTarget);
}
}
FlowNode flowNode = (FlowNode) process.getInitialFlowElement();
flowNode.setBehavior(mapBehavior.get(flowNode.getId()));
setFlowElement(flowNode, mapBehavior, mapSource, mapTarget);
}
private void setFlowElement(FlowElement flowElement,
Map<String, Object> mapBehavior,
Map<String, FlowElement> mapSource,
Map<String, FlowElement> mapTarget) {
if (flowElement instanceof FlowNode) {
FlowNode flowNode = (FlowNode) flowElement;
flowNode.setBehavior(mapBehavior.get(flowElement.getId()));
}
if (flowElement instanceof StartEvent) {
StartEvent startEvent = (StartEvent) flowElement;
for (SequenceFlow sequenceFlow : startEvent.getOutgoingFlows()) {
FlowElement source = mapSource.get(sequenceFlow.getId());
FlowElement target = mapTarget.get(sequenceFlow.getId());
sequenceFlow.setSourceFlowElement(source);
sequenceFlow.setTargetFlowElement(target);
if (null != target) {
setFlowElement(target, mapBehavior, mapSource, mapTarget);
}
}
}
if (flowElement instanceof UserTask) {
UserTask userTask = (UserTask) flowElement;
for (SequenceFlow sequenceFlow : userTask.getOutgoingFlows()) {
FlowElement source = mapSource.get(sequenceFlow.getId());
FlowElement target = mapTarget.get(sequenceFlow.getId());
sequenceFlow.setSourceFlowElement(source);
sequenceFlow.setTargetFlowElement(target);
if (null != target) {
setFlowElement(target, mapBehavior, mapSource, mapTarget);
}
}
}
if (flowElement instanceof SequenceFlow) {
SequenceFlow sequenceFlow = (SequenceFlow) flowElement;
FlowElement source = mapSource.get(sequenceFlow.getId());
FlowElement target = mapTarget.get(sequenceFlow.getId());
sequenceFlow.setSourceFlowElement(source);
sequenceFlow.setTargetFlowElement(target);
if (null != target) {
setFlowElement(target, mapBehavior, mapSource, mapTarget);
}
}
}
}
public class ExtUserTaskActivityBehavior extends UserTaskActivityBehavior {
private static final long serialVersionUID = 7711531472879418236L;
//要命的默认构造函数
public ExtUserTaskActivityBehavior() {
super(null);
}
public ExtUserTaskActivityBehavior(UserTask userTask) {
super(userTask);
}
}
像上面东拼西凑的,终于可以跑了,在这调试过程中,我又把流转的源码翻出来看了一遍。
测试使用的流程非常简单,如下图:
太复杂的我也不想试验了,太TM的麻烦了。以上,有错误你指正我也懒得改。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.6-Redis搭配Fury自定义缓存 | 字痕随行
之前通过一些简单的代码试验过序列/反序列化ProcessDefinitionCacheEntry,这次就使用Redis完整的试验一下。
选定的序列/反序列化工具为Fury,Redis版本是x64-5.0.14.1。
首先,在工程内引入Fury。
<dependency>
<groupId>org.furyio</groupId>
<artifactId>fury-core</artifactId>
<version>0.1.0-alpha.1</version>
</dependency>
然后,创建一个RedisSerializer的实现类。
public class FurySerializer<T> implements RedisSerializer<T> {
//使用线程安全模式
ThreadSafeFury fury = Fury.builder()
.withLanguage(Language.JAVA)
// enable referecne tracking for shared/circular reference.
// Disable it will have better performance if no duplciate reference.
.withRefTracking(true)
// Allow to deserialize objects unknown types,
// more flexible but less secure.
.withSecureMode(false)
.buildThreadSafeFury();
@Override
public byte[] serialize(T t) throws SerializationException {
return fury.serialize(t);
}
@Override
public T deserialize(byte[] bytes) throws SerializationException {
if (null == bytes) {
return null;
}
return (T) fury.deserialize(bytes);
}
}
再创建Redis的配置类,这里只展示主要的代码。
@Configuration
@EnableCaching
public class RedisConfig extends CachingConfigurerSupport {
/**
* retemplate相关配置
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 配置连接工厂
template.setConnectionFactory(factory);
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new FurySerializer<>());
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(new FurySerializer<>());
return template;
}
//这里省略了一些数据操作配置
}
自定义一个使用Redis的缓存类。
public class ProcessDefinitionRedisCache implements DeploymentCache<ProcessDefinitionCacheEntry> {
@Override
public ProcessDefinitionCacheEntry get(String id) {
//BeanFactory是自定义的,可以帮助取出Spring容器内的对象
RedisTemplate<String, Object> redisTemplate = BeanFactory.getBean("redisTemplate", RedisTemplate.class);
if (null == redisTemplate) {
return null;
}
Object obj = redisTemplate.opsForValue().get(id);
if (null == obj) {
return null;
}
ProcessDefinitionCacheEntry cacheEntry = (ProcessDefinitionCacheEntry) redisTemplate.opsForValue().get(id);
return cacheEntry;
}
@Override
public void add(String id, ProcessDefinitionCacheEntry processDefinitionCacheEntry) {
RedisTemplate<String, Object> redisTemplate = BeanFactory.getBean("redisTemplate", RedisTemplate.class);
if (null != redisTemplate) {
redisTemplate.opsForValue().set(id, processDefinitionCacheEntry);
}
}
Flowable的配置类内,需要使用自定义的缓存。
@Primary
@Bean(name = "processEngineConfiguration")
public SpringProcessEngineConfiguration getSpringProcessEngineConfiguration(@Qualifier("dataSource") DataSource dataSource, @Qualifier("transactionManager") DataSourceTransactionManager transactionManager) {
SpringProcessEngineConfiguration configuration = new SpringProcessEngineConfiguration();
//此处省略一大堆配置
//使用自定义的缓存
configuration.setProcessDefinitionCache(new ProcessDefinitionRedisCache());
return configuration;
}
最后,可以直接启动一个流程跑一下。我跑了一个比较简单的流程,没有异常产生。
以上,如果有错误,欢迎探讨和指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.6 - ID生成器 | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
53个
最近被Flowable的自定义缓存搞的神烦,今天先看看如何自定义它的ID生成器,后面再细说缓存的事。
如果只是想使用自定义ID生成策略,只需要以下代码就好了:
configuration.setIdGenerator(new IdGenerator() {
@Override
public String getNextId() {
//这里使用hutool的UUID工具类生成
return IdUtil.simpleUUID();
}
});
然后随便启动个流程,就可以看到所有的ID都变成UUID了:

如果还想了解一下为什么,可以继续往下看。
在UserTaskActivityBehavior的execute()中可以找到创建Task的方法。
这个方法可以追踪到TaskHelper中,一路追踪下去:
TaskHelper.insertTask->
TaskService.insertTask->
TaskEntityManagerImpl.insert->
AbstractEntityManager.insert->
AbstractDataManager.insert->
DbSqlSession.insert->
String id = idGenerator.getNextId();
就可以找到为Task赋予ID的方法,至于idGenerator来源于哪里,其实是在ProcessEngineConfigurationImpl中。
public void initIdGenerator() {
if (idGenerator == null) {
DbIdGenerator dbIdGenerator = new DbIdGenerator();
dbIdGenerator.setIdBlockSize(idBlockSize);
idGenerator = dbIdGenerator;
}
if (idGenerator instanceof DbIdGenerator) {
DbIdGenerator dbIdGenerator = (DbIdGenerator) idGenerator;
if (dbIdGenerator.getIdBlockSize() == 0) {
dbIdGenerator.setIdBlockSize(idBlockSize);
}
if (dbIdGenerator.getCommandExecutor() == null) {
dbIdGenerator.setCommandExecutor(getCommandExecutor());
}
if (dbIdGenerator.getCommandConfig() == null) {
dbIdGenerator.setCommandConfig(getDefaultCommandConfig().transactionRequiresNew());
}
}
}
同样,在这个方法中可以发现我们之前自定义ID生成策略的Set方法:
public ProcessEngineConfigurationImpl setIdGenerator(IdGenerator idGenerator) {
this.idGenerator = idGenerator;
return this;
}
以上就是自定义ID生成策略的简单实现,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.6 - 升级初体验 | 字痕随行
原创 字痕随行 字痕随行
收录于话题
#流程引擎
53个
上次在Flowable - 运行UI时,遇到了索引超长的问题,后来我又仔细琢磨了一下。
当时运行的语句是:
CREATE TABLE ACT_APP_DEPLOYMENT (ID_ VARCHAR(255) NOT NULL, NAME_ VARCHAR(255) NULL, CATEGORY_ VARCHAR(255) NULL, KEY_ VARCHAR(255) NULL, DEPLOY_TIME_ datetime NULL, TENANT_ID_ VARCHAR(255) DEFAULT '' NULL, CONSTRAINT PK_ACT_APP_DEPLOYMENT PRIMARY KEY (ID_));
因为要创建主键索引,所以遇到了索引超长的问题。开始也没仔细看,就想着增大索引允许的长度,但是未果。
后来,仔细看了看,觉得很蹊跷,一个255字符长度,不至于索引超长。想了想字符和字节的转换,大概问题在于,我开始创建的数据库,字符集类型是UTF-8mb4的。
如果是UTF-8mb4,一个字符可能占用4个字节长度,最大的索引长度是255*4,自然超长了。
所以,重新创建了一个数据库,改为UTF-8,按照之前的步骤,Flowable-UI终于能够正常的运行起来了。
这里顺带提一下,如果使用Flowable-UI应用创建的流程模型,是保存在act_de_model中的,和act_re_model没有关系。
然后,又把之前的项目升级了一下,使用Flowable6.6.0:
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-spring-boot-starter-process</artifactId>
<version>6.6.0</version>
</dependency>
简单运行了一下,过程中没有发现什么问题。
如果创建一个新库,使用升级后的应用运行,自动创建的数据库表并没有什么变化,如下图所示:
Gitee上分享的项目也已经更新到6.6.0版本:
https://gitee.com/blackzs/flowable-designer
以上,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 – 删除流程 | 字痕随行
上周忙的要死,微信号的留言都过期了。留言中有个问题,我觉得就是问如何删除一个流程。
这个问题,我能想到的有两个方法,就抛砖引玉一下了:
1. 直接跳转到结束节点,流程自然就没了,可以见Flowable6.4节点跳转初探。
2. 使用API接口删除流程实例。
第一个方法在这里就不详细说了,之前的分享应该就可以解决问题了。这次主要说说第二个办法。
这里用到的API很简单,如下:
/**
* instId 流程实例ID
* delReason 删除原因
*/
runtimeService.deleteProcessInstance(instId, delReason);
我做了一下测试,使用这个API删除的流程实例,数据也会保存至历史表,感觉还是比较安全的。
比如,删除了一个子流程,act_hi_taskinst是这样的:
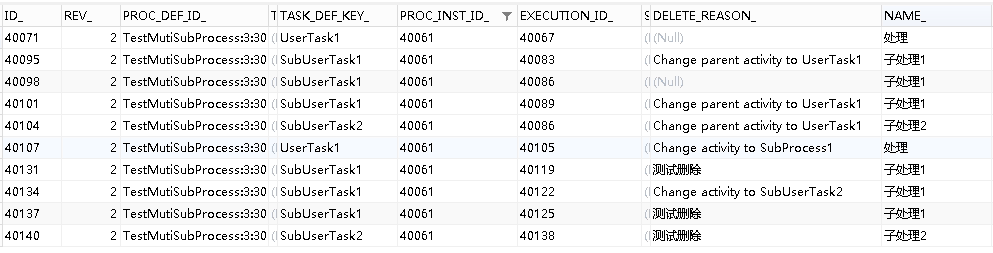
再比如,删除一个带有多实例节点的流程,act_hi_taskinst是这样的:

这个API内部到底干了什么呢?以下是关键部分的源码解析。
@Override
public void deleteProcessInstance(String processInstanceId, String deleteReason) {
//定义了一个删除的Command
commandExecutor.execute(new DeleteProcessInstanceCmd(processInstanceId, deleteReason));
}
这个Command调用的关键方法如下:
CommandContextUtil.getExecutionEntityManager(commandContext).deleteProcessInstance(processInstanceEntity.getProcessInstanceId(), deleteReason, false);
接着就是删数据的方法了:
protected void deleteProcessInstanceCascade(ExecutionEntity execution, String deleteReason, boolean deleteHistory) {
// fill default reason if none provided
if (deleteReason == null) {
deleteReason = DeleteReason.PROCESS_INSTANCE_DELETED;
}
getActivityInstanceEntityManager().deleteActivityInstancesByProcessInstanceId(execution.getId());
List<ExecutionEntity> childExecutions = collectChildren(execution.getProcessInstance());
for (ExecutionEntity subExecutionEntity : childExecutions) {
//删子级的流程执行实例
}
//删任务
TaskHelper.deleteTasksByProcessInstanceId(execution.getId(), deleteReason, deleteHistory);
if (getEventDispatcher() != null && getEventDispatcher().isEnabled()) {
getEventDispatcher().dispatchEvent(FlowableEventBuilder.createCancelledEvent(execution.getProcessInstanceId(),
execution.getProcessInstanceId(), execution.getProcessDefinitionId(), deleteReason));
}
//删子级流程执行实例的关联数据
//删子级关联的数据
deleteExecutionAndRelatedData(execution, deleteReason, deleteHistory);
//保存历史数据
}
在执行完上述方法后,接着为SubProcess做一些处理,就完成了流程删除工作。
如果希望加上自己的业务逻辑,可以在调用此API后加上自己的业务逻辑。也可以自定义一个命令,包裹上自己的业务逻辑。
以上,有需要的朋友可以试试,如有问题,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.4 – 异步执行器 | 字痕随行
最近看了看Flowable的相关文档,我对一段说明比较感兴趣,这段说明的中文翻译如下:
Flowable V5版本中,在之前的作业执行器(job executor)之外,还提供了异步执行器(async executor)。__异步执行器已被许多Flowable的用户及我们自己的跑分证明,性能比老的作业执行器好。
从Flowable V6起,将只提供异步执行器。__在V6中,对异步执行器进行了完全的重构,以提升性能及易用性。
所以,我特地去看了一下这部分的源码,以下就是异步执行器的相关源码解析。
首先,来看一下异步执行器的构造过程。
先由ProcessEngineConfigurationImpl.init()方法入手,在此方法内初始化了异步执行器:
public void initAsyncExecutor() {
if (asyncExecutor == null) {
//声明了一个默认的异步执行器
DefaultAsyncJobExecutor defaultAsyncExecutor = new DefaultAsyncJobExecutor();
//此处省略代码若干
}
asyncExecutor.setJobServiceConfiguration(jobServiceConfiguration);
//需要注意这个属性,false时不会启动执行器
asyncExecutor.setAutoActivate(asyncExecutorActivate);
jobServiceConfiguration.setAsyncExecutor(asyncExecutor);
}
在new ProcessEngineImpl()会控制是否启动执行器:
//autoActivate为false时就不会启动
if (asyncExecutor != null && asyncExecutor.isAutoActivate()) {
asyncExecutor.start();
}
在这个过程中,asyncExecutor.start()方法很重要,它会影响之后是否会使用异步控制器,主要是该方法内的一个参数:
/** Starts the async executor */
@Override
public void start() {
//isActive这个参数会影响是否使用该执行器
if (isActive) {
return;
}
isActive = true;
//以下省略代码若干
}
这里梳理一下:
如果asyncExecutorActivate等于false,isActive就等于false。
如果asyncExecutorActivate等于true,isActive就等于true。
而asyncExecutorActivate的默认值为false。
然后,什么时候调用执行器。
这个问题如果自己一点一点去读代码,就会很麻烦。其实官方文档有一段描述,中文翻译如下:
在API调用成功后触发的事务监听器(transaction commit listener),将会触发同一引擎中的异步执行器,让其执行该作业(因此可以保证数据库中已经保存了数据)。
既然提示的这么明显,就可以去事务提交的地方去追踪代码,事务提交都在TransactionContext内,具体的以SpringTransactionContext作为示例,查找方法addTransactionListener()的调用,如下图:
其中jobAddedTransactionListener就是调用异步执行器的源头:
@Override
public void execute(CommandContext commandContext) {
CommandConfig commandConfig = new CommandConfig(false, TransactionPropagation.REQUIRES_NEW);
commandExecutor.execute(commandConfig, new Command<Void>() {
@Override
public Void execute(CommandContext commandContext) {
if (LOGGER.isTraceEnabled()) {
LOGGER.trace("notifying job executor of new job");
}
//调用异步执行
asyncExecutor.executeAsyncJob(job);
return null;
}
});
}
如果一层一层追踪上去,会发现一个方法:
protected void triggerExecutorIfNeeded(JobEntity jobEntity) {
// When the async executor is activated, the job is directly passed on to the async executor thread
//此处就是对于isActive的判断,如果为True才增加监听器
if (isAsyncExecutorActive()) {
hintAsyncExecutor(jobEntity);
}
}
最后,在什么位置开始调用。
这个位置比较明显,其实就在ContinueProcessOperation这个类中,这个类关系到整个流程的流转,当进入节点时,它就会被触发。
而它根据当前节点的Asynchronous属性,来决定当前节点的处理是同步还是异步执行。
整个过程梳理一下:
以下一节点为UserTask为例,在通过ContinueProcessOperation进入此节点时,会判断Asynchronous属性的值。
如果为True,则为TransactionListener增加异步执行器(需要注意全局是否开启异步处理)相关的监听,以便数据在Commit时能够调用异步执行器进行处理。
当数据Commit时,触发监听器,异步处理此节点数据。
需要注意的是,如果全局未开启异步处理,但是在节点上却将Asynchronous设置为True,那么到达此节点时,相关的作业会被写入ACT_RU_JOB,但是无法被执行。
以上,如有问题欢迎讨论,如有错误欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.6-动态增加节点
闲话少说,直接进入正题吧。
本文主要分为两个部分:
- 使用原生的SDK动态增加节点。
- 自定义Cmd动态增加节点,更符合现实需要。
Flowable是通过InjectUserTaskInProcessInstanceCmd这个命令类来实现动态增加节点的,调用的示例代码如下:
@ResponseBody
@RequestMapping(value = "executInjectUserTask/{processInstanceId}")
public void executInjectUserTask(@PathVariable("processInstanceId") String processInstanceId) {
DynamicUserTaskBuilder dynamicUserTaskBuilder = new DynamicUserTaskBuilder();
dynamicUserTaskBuilder.setId("TEMP_USER_TASK");
dynamicUserTaskBuilder.setName("新增用户任务");
dynamicUserTaskBuilder.setAssignee("测试");
InjectUserTaskInProcessInstanceCmd injectUserTaskCmd
= new InjectUserTaskInProcessInstanceCmd(processInstanceId, dynamicUserTaskBuilder);
managementService.executeCommand(injectUserTaskCmd);
}
调用上面的方法时,只需要传入流程实例ID即可。定义一个流程,如下图:
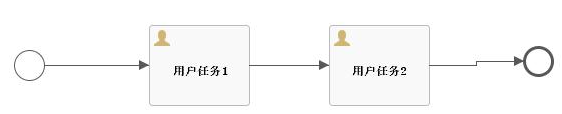
然后启动流程,流程会流转到“用户任务1”,此时task和execution中的数据如下图所示:


接下来调用上面定义的接口executInjectUserTask,就会动态增加一个UserTask,流程图会变成:
task、execution、procdef的数据如下所示:



简单说明一下:
- Flowable通过此命令在流程内增加了一个新的流程定义,此后该流程实例将在新的流程定义上执行。
- 在流程内增加了一个并行网关,然后新增指定的用户任务,而且这个用户任务完成后会直接结束。
- 新增了一个用户任务,并且保留了之前已经存在的用户任务。
- 新增了一个流程执行实例,为了能够执行新增的用户任务。
从新的流程图上来看,虽然动态增加了节点,但是不是特别贴合实际需要。在实际工作中,如果我们要增加节点,基本上应该是如下所示:
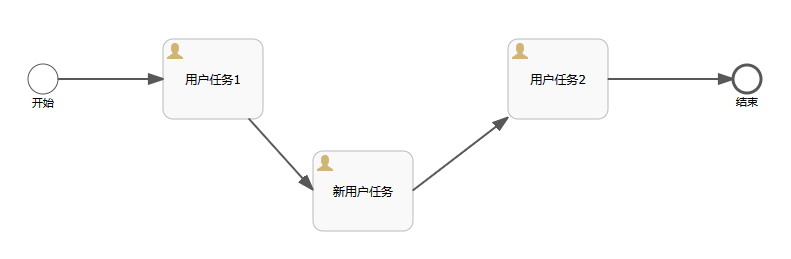

既然有源码,应该就可以进行改造,下一篇会介绍一下如何通过自定义命令实现动态增加用户任务节点。
以上,如有问题,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.6-自定义Cmd动态增加节点
上一篇介绍了如何通过使用Flowable原生的SDK动态增加节点。但是,原生的SDK有瑕疵,无法满足实际的生产需求。本篇,就介绍一下如何通过自定义Cmd动态增加节点。
首先,来看一下InjectUserTaskInProcessInstanceCmd这个类是怎么实现的。这个类的内部结构如下:
public class InjectUserTaskInProcessInstanceCmd extends AbstractDynamicInjectionCmd implements Command<Void> {
protected String processInstanceId;
protected DynamicUserTaskBuilder dynamicUserTaskBuilder;
public InjectUserTaskInProcessInstanceCmd(String processInstanceId, DynamicUserTaskBuilder dynamicUserTaskBuilder) {
this.processInstanceId = processInstanceId;
this.dynamicUserTaskBuilder = dynamicUserTaskBuilder;
}
@Override
public Void execute(CommandContext commandContext) {
createDerivedProcessDefinitionForProcessInstance(commandContext, processInstanceId);
return null;
}
//更新流程定义
@Override
protected void updateBpmnProcess(CommandContext commandContext, Process process,
BpmnModel bpmnModel, ProcessDefinitionEntity originalProcessDefinitionEntity, DeploymentEntity newDeploymentEntity) {
}
//后置更新流程执行所需要的数据
@Override
protected void updateExecutions(CommandContext commandContext, ProcessDefinitionEntity processDefinitionEntity,
ExecutionEntity processInstance, List<ExecutionEntity> childExecutions) {
}
}
这个类有两个方法是需要关注的:
- updateBpmnProcess这个方法主要由两大块功能组成。一部分是动态创建节点和连线,一部分是绘制新的流程图。
- updateExecutions这个方法是用来更新流程执行所需数据的,原生的方法里面是创建了一个新的流程执行实例,并且置为当前活动的任务。
所以,直接照葫芦画瓢就完事了。
接下来,先改造updateBpmnProcess这个方法,直接上代码了。
@Override
protected void updateBpmnProcess(CommandContext commandContext, Process process,
BpmnModel bpmnModel, ProcessDefinitionEntity originalProcessDefinitionEntity, DeploymentEntity newDeploymentEntity) {
if (null == currentElement) {
super.updateBpmnProcess(commandContext, process, bpmnModel, originalProcessDefinitionEntity, newDeploymentEntity);
return;
}
if (!(this.currentElement instanceof UserTask)) {
return;
}
StartEvent startEvent = getStartEvent(process);
if (null == startEvent) {
return;
}
UserTask currentUserTask = (UserTask) this.currentElement;
if (currentUserTask.getOutgoingFlows().size() <= 0) {
return;
}
SequenceFlow currentOutgoingFlow = currentUserTask.getOutgoingFlows().get(0);
FlowElement targetFlowElement = currentOutgoingFlow.getTargetFlowElement();
//创建新的任务节点和两条连线
UserTask newUserTask = createUserTask(process);
SequenceFlow newSequenceFlow1 = createSequenceFlow(currentUserTask, newUserTask);
SequenceFlow newSequenceFlow2 = createSequenceFlow(newUserTask, targetFlowElement);
//加到流程内
process.addFlowElement(newUserTask);
process.addFlowElement(newSequenceFlow1);
process.addFlowElement(newSequenceFlow2);
process.removeFlowElement(currentOutgoingFlow.getId());
//绘制新的流程图
GraphicInfo elementGraphicInfo = bpmnModel.getGraphicInfo(currentUserTask.getId());
if (elementGraphicInfo != null) {
double yDiff = 0;
double xDiff = 80;
if (elementGraphicInfo.getY() < 173) {
yDiff = 173 - elementGraphicInfo.getY();
elementGraphicInfo.setY(173);
}
Map<String, GraphicInfo> locationMap = bpmnModel.getLocationMap();
for (String locationId : locationMap.keySet()) {
if (startEvent.getId().equals(locationId)) {
continue;
}
GraphicInfo locationGraphicInfo = locationMap.get(locationId);
locationGraphicInfo.setX(locationGraphicInfo.getX() + xDiff);
locationGraphicInfo.setY(locationGraphicInfo.getY() + yDiff);
}
Map<String, List<GraphicInfo>> flowLocationMap = bpmnModel.getFlowLocationMap();
for (String flowId : flowLocationMap.keySet()) {
List<GraphicInfo> flowGraphicInfoList = flowLocationMap.get(flowId);
for (GraphicInfo flowGraphicInfo : flowGraphicInfoList) {
flowGraphicInfo.setX(flowGraphicInfo.getX() + xDiff);
flowGraphicInfo.setY(flowGraphicInfo.getY() + yDiff);
}
}
//把之前的连线给移除了
bpmnModel.removeFlowGraphicInfoList(currentOutgoingFlow.getId());
//重新排版,这里需要引入flowable-bpmn-layout
new BpmnAutoLayout(bpmnModel).execute();
}
BaseDynamicSubProcessInjectUtil.processFlowElements(commandContext, process, bpmnModel, originalProcessDefinitionEntity, newDeploymentEntity);
}
这时候,流程图已经变正常了。上面的代码演示的是在当前任务节点之后增加了一个新的任务节点,如果需要在之前增加,可以自行改造一下。
现在,流程图虽然已经变正常了,但是execution现在还是两个,task也是两个。
如果只是想增加个任务节点,而不需要增加execution和task,那么直接将updateExecutions方法置空就行了,如下:
@Override
protected void updateExecutions(CommandContext commandContext, ProcessDefinitionEntity processDefinitionEntity,
ExecutionEntity processInstance, List<ExecutionEntity> childExecutions) {
}
最后,把这个类定义为CustomInjectUserTaskCmd吧,然后就可以试一下了:
public class CustomInjectUserTaskCmd extends InjectUserTaskInProcessInstanceCmd {}
本篇只局限于在主流程内增加一个用户任务节点,接下来我还打算试试在子流程内增加一个任务节点。
以上,如有问题,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.6-调用自定义Cmd动态增加节点
上一篇,通过自定义Cmd实现了动态增加节点,本篇就调用一下自定义的Cmd看看效果。
测试的代码如下:
/**
* 自定义增加节点
* @param processInstanceId 流程实例标识
*/
@ResponseBody
@RequestMapping(value = "executCustomInjectUserTask/{processInstanceId}")
public void executCustomInjectUserTask(@PathVariable("processInstanceId") String processInstanceId) {
DynamicUserTaskBuilder dynamicUserTaskBuilder = new DynamicUserTaskBuilder();
dynamicUserTaskBuilder.setId("TEMP_USER_TASK");
dynamicUserTaskBuilder.setName("新增用户任务");
dynamicUserTaskBuilder.setAssignee("测试");
Task task = taskService.createTaskQuery().processInstanceId(processInstanceId).singleResult();
BpmnModel bpmnModel = repositoryService.getBpmnModel(task.getProcessDefinitionId());
FlowElement thisFlowElement = bpmnModel.getMainProcess().getFlowElement(task.getTaskDefinitionKey());
CustomInjectUserTaskCmd customInjectUserTaskCmd
= new CustomInjectUserTaskCmd(processInstanceId, thisFlowElement, dynamicUserTaskBuilder);
managementService.executeCommand(customInjectUserTaskCmd);
}
仍旧是之前定义的那个简单流程:
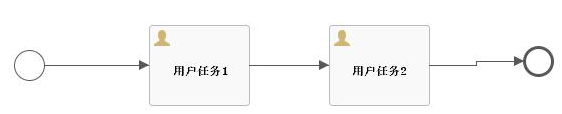
启动流程后,仍旧让其流转到“用户任务1”,其execution和task的数据也没有什么变化。
然后调用executCustomInjectUserTask,传入流程实例标识,来看看流程整体有什么变化。
首先是流程图:

然后再看一下execution和task的数据:


这就实现了我们需要的效果:
- 在“用户任务1”后面增加一个新的节点“新增用户任务”。
- execution和task仍旧只有用户任务1的数据,新增节点等待触发流转后再生成实际数据。
整个流程流转完成后,history的数据如下:
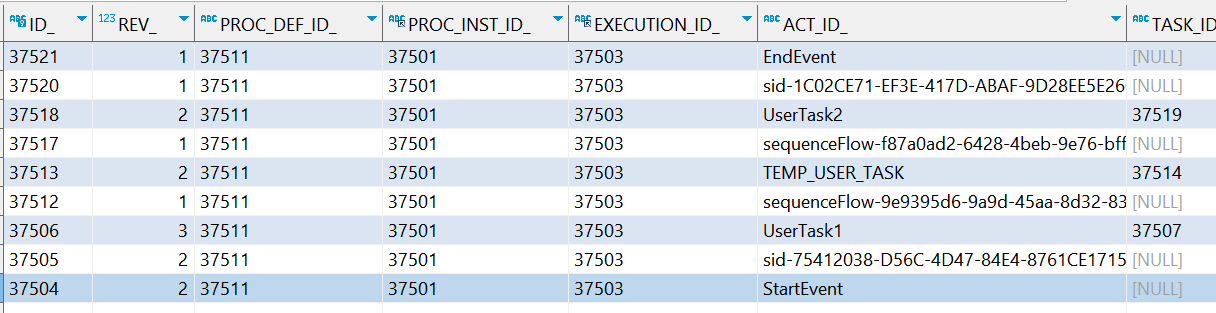
以上,如有问题,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.6-调用自定义Cmd在子流程内动态增加UserTask | 字痕随行
之前说要尝试一下在子流程内动态增加UserTask节点,这篇就简单介绍一下实现和一些注意点。
普通的子流程可以看成在MainProcess内嵌入了另外一个流程。区别于调用子流程,这个嵌入的子流程的所有节点、连接线都在主流程定义文件内。
基于之前的文章,再分析一下流程的定义文件,可以发现动态增加节点的思路是一样的,唯一不同的只在于增加的节点需要在SubProcess内。
那么,同样的,定义一个Cmd即可:
@Override
protected void updateBpmnProcess(CommandContext commandContext, Process process,
BpmnModel bpmnModel, ProcessDefinitionEntity originalProcessDefinitionEntity, DeploymentEntity newDeploymentEntity) {
if (null == currentElement) {
super.updateBpmnProcess(commandContext, process, bpmnModel, originalProcessDefinitionEntity, newDeploymentEntity);
return;
}
if (!(this.currentElement instanceof UserTask)) {
return;
}
FlowElementsContainer container = currentElement.getParentContainer();
if (!(container instanceof SubProcess)) {
return;
}
UserTask currentUserTask = (UserTask) this.currentElement;
if (currentUserTask.getOutgoingFlows().size() <= 0) {
return;
}
SequenceFlow currentOutgoingFlow = currentUserTask.getOutgoingFlows().get(0);
FlowElement targetFlowElement = currentOutgoingFlow.getTargetFlowElement();
//需要动态增加的UserTask节点
UserTask newUserTask = createUserTask(process);
SubProcess subProcess = (SubProcess) container;
FlowElement flowElement = process.getFlowElement(subProcess.getId());
if (!(flowElement instanceof SubProcess)) {
return;
}
subProcess = (SubProcess) flowElement;
//新的两条连接线
SequenceFlow newSequenceFlow1 = createSequenceFlow(subProcess, currentUserTask, newUserTask);
SequenceFlow newSequenceFlow2 = createSequenceFlow(subProcess, newUserTask, targetFlowElement);
//加到子流程内
subProcess.addFlowElement(newUserTask);
subProcess.addFlowElement(newSequenceFlow1);
subProcess.addFlowElement(newSequenceFlow2);
//删掉无用的连接线
subProcess.removeFlowElement(currentOutgoingFlow.getId());
//删除流程图内无用的连接线,同时自动排版
bpmnModel.removeFlowGraphicInfoList(currentOutgoingFlow.getId());
new BpmnAutoLayout(bpmnModel).execute();
BaseDynamicSubProcessInjectUtil.processFlowElements(commandContext, process, bpmnModel, originalProcessDefinitionEntity, newDeploymentEntity);
}
创建UserTask的代码:
private UserTask createUserTask(Process process) {
UserTask userTask = new UserTask();
if (dynamicUserTaskBuilder.getId() != null) {
userTask.setId(dynamicUserTaskBuilder.getId());
} else {
userTask.setId(dynamicUserTaskBuilder.nextTaskId(process.getFlowElementMap()));
}
dynamicUserTaskBuilder.setDynamicTaskId(userTask.getId());
userTask.setName(dynamicUserTaskBuilder.getName());
userTask.setAssignee(dynamicUserTaskBuilder.getAssignee());
return userTask;
}
创建SequenceFlow的代码:
private SequenceFlow createSequenceFlow(BaseElement parent, FlowElement source, FlowElement target) {
SequenceFlow sequenceFlow = new SequenceFlow(source.getId(), target.getId());
//要注意生成连接线的id,不生成的话流程图会没有线
if (parent instanceof Process) {
Process process = (Process) parent;
sequenceFlow.setId(dynamicUserTaskBuilder.nextFlowId(process.getFlowElementMap()));
} else if (parent instanceof SubProcess) {
SubProcess subProcess = (SubProcess) parent;
sequenceFlow.setId(dynamicUserTaskBuilder.nextFlowId(subProcess.getFlowElementMap()));
}
return sequenceFlow;
}
然后,就可以用之前的方式调用自定义的Cmd进行测试了,流程图就会变成这样:

最后,我试验了一下这种方式是否支持自由跳转。结论是:支持,至少目前这种动态增加的节点可以在流程内自由跳转。
以上,如果有错误,欢迎探讨和指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.6-从任意节点启动 | 字痕随行
中国式流程有一些很变态的需求,比如流程重启。
我能想到流程重启的三种方式如下:
- 调用startProcessInstanceByKey重新执行一遍流程。
- 调用startProcessInstanceByKey重新启动流程,使用节点自由跳转的方式跳转到指定的UserTask。
- 自定义Cmd,直接从指定的UserTask启动。
需要说明的是,这三种方式在与用户交互时,都需要通过businessKey进行个性化处理。
前两种方式的实现在之前的示例中都有所介绍,本篇主要介绍一下第三种方式。
如果注意过BpmnModel里面的Process,就会发现Process有一个属性:initialFlowElement。
去看一下startProcessInstanceByKey的代码,会发现:
// Create the first execution that will visit all the process definition elements
ExecutionEntity execution = processEngineConfiguration.getExecutionEntityManager().createChildExecution(processInstance);
execution.setCurrentFlowElement(startInstanceBeforeContext.getInitialFlowElement());
这代码挺清晰的,设置了流程执行实例的当前节点元素。后面就会调用planContinueProcessOperation向下继续执行该节点的Behavior了。
所以,只需要定义一个Cmd就行了,只要这个Cmd里面能够改变initialFlowElement。
public class CustomRestartProcessCmd extends StartProcessInstanceCmd<ProcessInstance> {
ProcessInstanceHelper processInstanceHelper;
//从哪个节点开始启动
FlowElement restartFlowElement;
public CustomRestartProcessCmd(String processDefinitionKey, String processDefinitionId, String businessKey, Map<String, Object> variables) {
super(processDefinitionKey, processDefinitionId, businessKey, variables);
}
@Override
public ProcessInstance execute(CommandContext commandContext) {
ProcessEngineConfigurationImpl processEngineConfiguration = CommandContextUtil.getProcessEngineConfiguration(commandContext);
processInstanceHelper = processEngineConfiguration.getProcessInstanceHelper();
ProcessDefinition processDefinition = getProcessDefinition(processEngineConfiguration, commandContext);
Process process = ProcessDefinitionUtil.getProcess(processDefinition.getId());
ProcessInstance processInstance = processInstanceHelper.createAndStartProcessInstanceWithInitialFlowElement(
processDefinition,
businessKey,
businessStatus,
processInstanceName,
restartFlowElement,
process,
variables,
transientVariables,
true);
return processInstance;
}
public FlowElement getRestartFlowElement() {
return restartFlowElement;
}
public void setRestartFlowElement(FlowElement restartFlowElement) {
this.restartFlowElement = restartFlowElement;
}
}
最后,测试的代码如下:
@RequestMapping(value = "restart/{id}")
@ResponseBody
public void restartProcess(@PathVariable("id") String id) {
HistoricActivityInstance historicActivityInstance = historyService.createHistoricActivityInstanceQuery().activityInstanceId(id).singleResult();
BpmnModel bpmnModel = repositoryService.getBpmnModel(historicActivityInstance.getProcessDefinitionId());
FlowElement flowElement = bpmnModel.getFlowElement(historicActivityInstance.getActivityId());
CustomRestartProcessCmd cmd = new CustomRestartProcessCmd(
null,
historicActivityInstance.getProcessDefinitionId(),
UUID.randomUUID().toString(),
new HashMap<>()
);
cmd.setRestartFlowElement(flowElement);
managementService.executeCommand(cmd);
}
以上代码,我简单的测试了一下:
- 可以从任意UserTask启动。
- 可以从任意SubProcess启动(它会触发子流程内的StartEvent,然后流转到UserTask停住)。
以上,如果有错误,欢迎探讨和指正。
觉的不错?可以关注我的公众号↑↑↑
Flowable6.6-使用BpmnModel定义流程 | 字痕随行
基于之前的文章,可以得出一个结论:通过BpmnModel可以使用编程方式完成流程定义。
本篇就简单介绍一下如何实现。首先,创建一个的BpmnModel,包含完整的流程定义,代码如下:
private BpmnModel createBpmnModel() {
BpmnModel bpmnModel = new BpmnModel();
//开始事件
StartEvent startEvent = new StartEvent();
startEvent.setId("startEvent");
startEvent.setName("开始");
//用户任务节点
UserTask userTask = new UserTask();
userTask.setId("userTask1");
userTask.setName("用户任务1");
userTask.setCategory("测试");
//结束事件
EndEvent endEvent = new EndEvent();
endEvent.setId("endEvent");
endEvent.setName("结束");
//两条连接线
SequenceFlow sequenceFlow1 = new SequenceFlow(startEvent.getId(), userTask.getId());
sequenceFlow1.setId("sequenceFlow1");
SequenceFlow sequenceFlow2 = new SequenceFlow(userTask.getId(), endEvent.getId());
sequenceFlow2.setId("sequenceFlow2");
//主流程
Process process = new Process();
process.setId("bpmnModelTestProcess");
process.setName("bpmn模型测试流程");
process.setExecutable(true);
//把流程元素加入到主流程
process.addFlowElement(startEvent);
process.addFlowElement(userTask);
process.addFlowElement(endEvent);
process.addFlowElement(sequenceFlow1);
process.addFlowElement(sequenceFlow2);
//把主流程加入到BpmnModel中
bpmnModel.addProcess(process);
//使用自动排版功能排版,同时定义流程元素的BpmnDI
new BpmnAutoLayout(bpmnModel).execute();
return bpmnModel;
}
然后就是保存发布的代码了:
//将bpmn转成xml文件格式
BpmnXMLConverter xmlConverter = new BpmnXMLConverter();
byte[] bytes = xmlConverter.convertToXML(bpmnModel);
//发布流程
Deployment deployment = repositoryService.createDeployment()
.name(bpmnModel.getMainProcess().getName())
.key(bpmnModel.getMainProcess().getId())
.category("测试")
.addString(bpmnModel.getMainProcess().getName() + ".bpmn20.xml", new String(bytes))
.deploy();
//创建流程模型
Model model = repositoryService.newModel();
ObjectNode modelObjectNode = objectMapper.createObjectNode();
modelObjectNode.put(ModelDataJsonConstants.MODEL_NAME, bpmnModel.getMainProcess().getName());
modelObjectNode.put(ModelDataJsonConstants.MODEL_REVISION, 1);
modelObjectNode.put(ModelDataJsonConstants.MODEL_DESCRIPTION, "测试");
model.setMetaInfo(modelObjectNode.toString());
model.setName(bpmnModel.getMainProcess().getName());
model.setKey(bpmnModel.getMainProcess().getName());
model.setCategory("测试");
model.setDeploymentId(deployment.getId());
repositoryService.saveModel(model);
repositoryService.addModelEditorSource(model.getId(), bytes);
然后就可以用接口来测试了,复杂点的也是这样定义,换汤不换药。
以上,如果有错误,欢迎探讨和指正。
觉的不错?可以关注我的公众号↑↑↑
Camunda7 - 从completeTask看pvm | 字痕随行
其实我也没想好怎么起这个题目,然后这是心血来潮后的一篇记录。
背景就是:我没尝试过Camunda,生产环境也没有任何经验,只是久闻大名之后,突然心痒,所以看了一下源码,切入点集中在pvm而已。
我想看看Camunda里面的pvm到底起了什么作用,它的原理和Flowable到底有何不同,所以才有了这篇文章。
因为只耗费了数个小时而已,所以也不输出结论,以免以偏概全。另外,可能这只是一篇源码走读,稍显枯燥。
从TaskService的Complete入手,看看从一个UserTask是如何流转到另外一个UserTask的,当初看Flowable就这么入手的,所以这次依然这样了。
废话那么多,如果你还想继续看下去,那咱们就继续吧。
本文基于Camunda-7.15.0-alpha1。
总的来说,Flowable操作流程的跳转全靠Behavior,因为Flowable已经完全剔除了Pvm。
但是Camunda完全不同,虽然它也有Behavior,但是节点之间的流转控制完全交给了Pvm。
这里面需要特别注意一个类:PvmAtomicOperation,按这个类里面定义的顺序,已经可以了解整个Pvm的执行过程。
从TaskService的Complete入手:
public void complete(String taskId) {
complete(taskId, null);
}
整个的执行过程是:
taskService.Complete
execution.signal
activityBehavior.signal
userTaskBehavior.signal -> leave //在这里触发了leave方法,一看就是离开节点
execution.dispatchDelayedEventsAndPerformOperation
ACTIVITY_LEAVE //pvm
behavior.doLeave
bpmnActivityBehavior.performDefaultOutgoingBehavior(execution)
TRANSITION_NOTIFY_LISTENER_END //pvm
TRANSITION_DESTROY_SCOPE //pvm
TRANSITION_NOTIFY_LISTENER_TAKE //pvm
TRANSITION_START_NOTIFY_LISTENER_TAKE //pvm
TRANSITION_CREATE_SCOPE //pvm
TRANSITION_NOTIFY_LISTENER_START //pvm
ACTIVITY_EXECUTE //pvm
activityBehavior.execute(execution) //进入了下一个节点
最后,进入下一个UserTask节点结束:
@Override
public void performExecution(ActivityExecution execution) throws Exception {
TaskEntity task = new TaskEntity((ExecutionEntity) execution);
task.insert();
// initialize task properties
taskDecorator.decorate(task, execution);
// fire lifecycle events after task is initialized
task.transitionTo(TaskState.STATE_CREATED);
}
我一直再找流程节点间的连接线,找入口和出口,但是一直没有Sequence这个关键字出现,后来搜索了一下,才知道pvm中的Transition就是连接线的意思(接触Activiti太少了,相关知识储备不够啊)。
这样的话就可以看到代码中的过程是:pvm控制节点离开,然后再控制连接线寻找出口,最后再控制进入下一个节点(这里只讨论UserTask到UserTask)。
我目前的简单理解就是,流程在运行当中,pvm中的对象记载了流程元素在运行过程中的情况,并且加以控制。
但是,很模糊的点在于,什么时候能够使用pvm干什么事情,这个可能需要以后有机会再尝试了。
好了,记录完毕,如果文中有错误,欢迎指正。
如果有问题,欢迎指正讨论。

觉的不错?可以关注我的公众号↑↑↑
Camunda7 - 解析自定义Behavior的生效过程 | 字痕随行
本篇内容源于我在Camunda里面为节点动态设置办理人。不同于之前在Flowable里面通过扩展Behavior实现,这里需要通过BpmnParseListener来重写设置。
在这里我产生了两个疑问:
- 自定义的Behavior在这个过程中是如何生效的。
- MultiInstanceActivityBehavior和UserTaskActivityBehavior的关系是什么。
这篇文章就是为了解答第一个问题而存在的。
这里有两个入手点,第一个是从ProcessEngineConfiguration入手,配置监听器生效:
//增加监听器
configuration.setCustomPreBPMNParseListeners(new ArrayList<BpmnParseListener>() {{
add(new MyBpmnParseListener());
}});
然后就可以去查找这个监听器的触发点了,这里可以看BpmnParse,以parseUserTask为例:
//循环加入Listener
for (BpmnParseListener parseListener : parseListeners) {
parseListener.parseUserTask(userTaskElement, scope, activity);
}
这里的parseListeners就是在初始化的:
protected BpmnDeployer getBpmnDeployer() {
//省略代码若干
BpmnParser bpmnParser = new BpmnParser(expressionManager, bpmnParseFactory);
if (preParseListeners != null) {
bpmnParser.getParseListeners().addAll(preParseListeners);
}
bpmnParser.getParseListeners().addAll(getDefaultBPMNParseListeners());
if (postParseListeners != null) {
bpmnParser.getParseListeners().addAll(postParseListeners);
}
bpmnDeployer.setBpmnParser(bpmnParser);
return bpmnDeployer;
}
所以,从这里可以看到自定义的Listener是如何被加载的。
第二个入手点,就是Behavior的调用时机。
直接看这段代码就可以了:
public class PvmAtomicOperationActivityExecute implements PvmAtomicOperation {
//此处省略代码若干
public void execute(PvmExecutionImpl execution) {
execution.activityInstanceStarted();
execution.continueIfExecutionDoesNotAffectNextOperation(
//此处省略代码若干
ActivityBehavior activityBehavior = getActivityBehavior(execution);
//此处省略代码若干
activityBehavior.execute(execution);
//此处省略代码若干
}
//此处省略代码若干
}
把上面的串起来看,就是整个生效过程:自定义MyBpmnParseListener -> 重写Activity的Behavior -> 加载自定义的Listener -> 调用Activity的Beahavior -> 触发自定义的Behavior。
如果有问题,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Camunda7 - 解析多实例UserTask节点Behavior执行过程 | 字痕随行
本篇内容源于我在Camunda里面为节点动态设置办理人。不同于之前在Flowable里面通过扩展Behavior实现,这里需要通过BpmnParseListener来重写设置。
在这里我产生了两个疑问:
- 自定义的Behavior在这个过程中是如何生效的。
- MultiInstanceActivityBehavior和UserTaskActivityBehavior的关系是什么。
这篇文章就是为了解答第二个问题而存在的。
要解答这个问题,其实只需要看一看多实例UserTask是否仍旧触发UserTaskActivityBehavior,然后再看看MultiInstanceActivityBehavior触发的时机即可。
仍旧可以从taskService.complete()方法入手,大概看一下多实例任务执行的过程:
taskService.complete() ->
CompleteTaskCmd().execute() ->
completeTask() ->
task.complete() ->
execution.signal() ->
//UserTaskActivityBehavior,触发leave方法,处理离开节点逻辑
activityBehavior.signal() ->
PvmAtomicOperation.ACTIVITY_LEAVE ->
FlowNodeActivityBehavior.doLeave() ->
//关键点逻辑开始
BpmnActivityBehavior.performOutgoingBehavior() ->
execution.end(true) ->
PvmAtomicOperation.ACTIVITY_NOTIFY_LISTENER_END ->
//最终的逻辑在这里,是要看的地方了
PvmAtomicOperation.ACTIVITY_END
上面的一系列过程走完后,只需要看ACTIVITY_END里面的execute(),这里面有部分判断,关键的判断是:
PvmScope flowScope = activity.getFlowScope();
if(flowScope == activity.getProcessDefinition()) {
} else {
}
所以,这个flowScope是什么对象,决定了最终要执行的逻辑。
这时候就要去看activity的flowScope是在何时赋值的,找一下就可以在BpmnParse里面发现它的处理过程了。
直接看parseActivity这个方法,这个方法的参数scopeElement就是activity里面flowScope的值。
protected ActivityImpl parseActivity(Element activityElement, Element parentElement, ScopeImpl scopeElement) {}
向上找到入参的地方,可以发现scopeElement正常情况下传递的是processDefinition,而多实例情况下,就会变成miBody。
boolean isMultiInstance = false;
ScopeImpl miBody = parseMultiInstanceLoopCharacteristics(activityElement, scopeElement);
if (miBody != null) {
scopeElement = miBody;
isMultiInstance = true;
}
这里miBody就会被赋予多实例的Behavior:
MultiInstanceActivityBehavior behavior = null;
if (isSequential) {
behavior = new SequentialMultiInstanceActivityBehavior();
} else {
behavior = new ParallelMultiInstanceActivityBehavior();
}
miBodyScope.setActivityBehavior(behavior);
到这里,再看之前的PvmAtomicOperation.ACTIVITY_END.execute(),就能够理解它的逻辑处理过程了。
很明显的,多实例节点的flowScope不是processDefinition,这时候就会执行:
PvmActivity flowScopeActivity = (PvmActivity) flowScope;
ActivityBehavior activityBehavior = flowScopeActivity.getActivityBehavior();
if (activityBehavior instanceof CompositeActivityBehavior) {
CompositeActivityBehavior compositeActivityBehavior = (CompositeActivityBehavior) activityBehavior;
//此处省略代码若干
}
CompositeActivityBehavior这个类,其实就是MultiInstanceActivityBehavior了,至于是并行的还是串行的,就看实际的设置了。
最后总结一下就是,UserTask节点,先执行UserTaskActivityBehavior,如果是多实例节点,就会再执行MultiInstanceActivityBehavior。
如果有问题,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Camunda7 - 集群部署的分析 | 字痕随行
首先,先看一下官方对于Camunda分布式部署的说明。可以参考它的官方文档:
https://docs.camunda.org/manual/latest/introduction/architecture/
这是英文的,大概看一下Clustering Model这个章节。此章节确定了一点,如果多个流程引擎的实例连接的是同一个数据库,是可以在流程引擎层面实现集群部署的。
所以本文主要着眼于两点进行分析:
- 每一次触发流程运行(调用taskComplete),必从数据库获取最新的数据,执行完毕后,必将数据持久化到数据库,即:每一个流程引擎实例不会在运行中缓存数据,影响到下一次的触发。
- 在任何一个流程引擎实例部署新的流程定义,在其它的流程引擎实例启动流程时,会使用最新的流程定义。
先分析第一点:
仍旧由taskComplete方法入手,很明显的一段查询代码如下:
TaskManager taskManager = commandContext.getTaskManager();
TaskEntity task = taskManager.findTaskById(taskId);
看看最终是怎么查询task数据的:
public <T extends DbEntity> T selectById(Class<T> entityClass, String id) {
T persistentObject = dbEntityCache.get(entityClass, id);
if (persistentObject!=null) {
return persistentObject;
}
persistentObject = persistenceSession.selectById(entityClass, id);
if (persistentObject==null) {
return null;
}
// don't have to put object into the cache now. See onEntityLoaded() callback
return persistentObject;
}
在上面的代码中,dbEntityCache一看就是从缓存查找,那persistenceSession就是从数据库查询了。
先看看dbEntityCache,这个地方其实就是从Map里面Get,仅从这里无法确定这数据是不是会被永久缓存。
其实,完全可以看看commandContext.getTaskManager(),由此可以看看commandContext是从哪里来的。
因为,我们都知道,Activiti、Flowable、Camunda都是基于命令链模式的,而且它们这块命令链的代码都差不多。
所以,直接看CommandContextInterceptor里面的:
Context.getCommandContext()
就会发现,CommandContext被保存在当前线程里:
protected static ThreadLocal<Deque<CommandContext>> commandContextThreadLocal = new ThreadLocal<Deque<CommandContext>>();
依照这个,再看其它相关的代码,就会发现Session、Cache都是保存在ThreadLocal的,这其实就可以保证数据不会扩散,不会影响到当前线程之外的其它处理结果。
在之前的Flowable相关文章里面也分析过,这些流程引擎数据写入数据库其实是在命令链结束时一次写入的,也就是在CommandContext的close方法内:
public void close(CommandInvocationContext commandInvocationContext) {
}
至此,其实第一个问题已经分析完了,结论就是:每一个流程引擎实例不会在运行中缓存数据,影响到下一次的触发,而且每一次新的调用都会重新从数据库中初始化数据。
再来分析第二点:
直接由启动流程的代码入手
@Override
public ProcessInstance startProcessInstanceByKey(String processDefinitionKey) {
return createProcessInstanceByKey(processDefinitionKey)
.execute();
}
依此定位到GetDeployedProcessDefinitionCmd的流程定义查询方法
ProcessDefinitionEntity processDefinition = find(commandContext);
直接跟到最后的查询方法
public T findDeployedLatestDefinitionByKey(String definitionKey) {
T definition = getManager()
.findLatestDefinitionByKey(definitionKey);
checkInvalidDefinitionByKey(definitionKey, definition);
definition = resolveDefinition(definition);
return definition;
}
findLatestDefinitionByKey其实就是从数据库查询数据。到此,第二点也分析完了,结论就是:每次启动都从数据库查询最新的流程定义。
所以,只要是共享数据库,Camunda就是支持多流程引擎实例部署的,它运行时的所需的数据都是从数据库中获取最新的,并且运行完成后,会立即更新到数据库中。
但是,官方的文档中也指出了,负载均衡是需要单独支持的。举个例子,taskComplete并发了,并且两个请求打到了两个流程引擎实例上,这时候其实是有问题的,所以在更上层还是需要分布式锁来控制。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
RocketMQ-入门 | 字痕随行
最近鼓捣了几个小玩意:
- RocketMQ
- CAS
- JWT
有空就记录一下,顺便再梳理一下思路,以后看自己写的东西也比看别人的易于理解。
如何下载?
RocketMQ的下载地址如下:
http://rocketmq.apache.org/dowloading/releases/
RocketMQ对于JDK版本的要求还是挺清晰的:
这里测试的话,我没有下载源码进行编译,以后想看源码的话再说。直接下载的是rocketmq-all-4.8.0-bin-release.zip。
伸手党的话,直接使用下面的地址下载:
https://mirrors.bfsu.edu.cn/apache/rocketmq/4.8.0/rocketmq-all-4.8.0-bin-release.zip
如何启动?
下载并解压完成后,并不能直接启动,需要进入bin文件夹修改一下启动文件,本文以windows系统为例。
先修改runserver.cmd,主要是修改一下初始内存大小,毕竟只是为了开发测试而已:
set "JAVA_OPT=%JAVA_OPT% -server -Xms256m -Xmx256m -Xmn128m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
set "JAVA_OPT=%JAVA_OPT% -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+CMSClassUnloadingEnabled -XX:SurvivorRatio=8 -XX:-UseParNewGC"
set "JAVA_OPT=%JAVA_OPT% -verbose:gc -Xloggc:"%USERPROFILE%\rmq_srv_gc.log" -XX:+PrintGCDetails"
set "JAVA_OPT=%JAVA_OPT% -XX:-OmitStackTraceInFastThrow"
set "JAVA_OPT=%JAVA_OPT% -XX:-UseLargePages"
set "JAVA_OPT=%JAVA_OPT% -Djava.ext.dirs=%BASE_DIR%lib"
set "JAVA_OPT=%JAVA_OPT% -cp "%CLASSPATH%""
然后再修改runbroker.cmd,这个文件要修改两个地方,一个是内存,一个是CLASSPATH:
set "JAVA_OPT=%JAVA_OPT% -server -Xms256m -Xmx256m -Xmn128m"
set "JAVA_OPT=%JAVA_OPT% -XX:+UseG1GC -XX:G1HeapRegionSize=16m -XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:SurvivorRatio=8"
set "JAVA_OPT=%JAVA_OPT% -verbose:gc -Xloggc:%USERPROFILE%\mq_gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintAdaptiveSizePolicy"
set "JAVA_OPT=%JAVA_OPT% -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=30m"
set "JAVA_OPT=%JAVA_OPT% -XX:-OmitStackTraceInFastThrow"
set "JAVA_OPT=%JAVA_OPT% -XX:+AlwaysPreTouch"
set "JAVA_OPT=%JAVA_OPT% -XX:-UseLargePages -XX:-UseBiasedLocking"
set "JAVA_OPT=%JAVA_OPT% -Djava.ext.dirs=%BASE_DIR%lib"
set "JAVA_OPT=%JAVA_OPT% -cp "%CLASSPATH%""
runbroker.cmd的%CLASSPATH%少了双引号,导致如果目录包含空格,就会报错,这里需要注意一下。
最后,设置一下环境变量,增加ROCKETMQ_HOME:
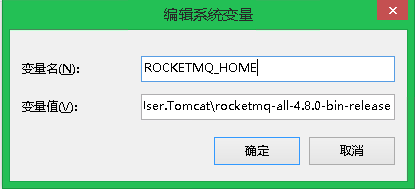
在命令行内启动NameServer:
再启动Broker:
不过,建议启动Broker的时候,使用命令:
##9876是MQ的默认端口
start mqbroker.cmd -n 127.0.0.1:9876 autoCreateTopicEnable=true
因为开发测试的时候,最好让它能够自动创建Topic,这样会轻松简单不少。
如何测试?
启动以后肯定希望验证一下是否正常,最简单的方法是使用RocketMQ自带的生产者和消费者。
打开Cmd命令行窗口,输入以下命令:
set NAMESRV_ADDR=127.0.0.1:9876
tools.cmd org.apache.rocketmq.example.quickstart.Consumer
启动消费者:
同样的,再打开一个新的命令行窗口,输入以下命令:
set NAMESRV_ADDR=127.0.0.1:9876
tools.cmd org.apache.rocketmq.example.quickstart.Producer
启动生产者,此时它会自动发送消息:
消费者会同时收到消息:
这样就能够测试MQ是否运行正常。
以上就是简单的入门配置,后面再说如何在Spring Cloud中使用。
以上,如果有错误,欢迎探讨和指正。

觉的不错?可以关注我的公众号↑↑↑
RocketMQ-事务消息 | 字痕随行
选择RocketMQ是因为它支持事务消息,它的事务消息实现过程如下:
- 先发送一条半消息。
- 处理业务逻辑。
- 业务逻辑成功,则确认消息,这时候半消息会正式推送至消费者。业务逻辑失败,则回滚消息,这时候半消息会取消。
- 因为异常情况,导致无法确认或者回滚时,利用回查接口轮询最终的业务处理结果,再确认或者回滚消息。
上面的过程都是我抄的,只不过边读边理解,然后用自己的话复述了一遍,哈哈。
接下来,进入主题,使用Spring Cloud Stream实现事务消息。
第一步,生产者创建一个Channel,用来发送消息。
public interface TestChannel {
@Output("output-transaction1")
MessageChannel outputTransaction();
}
就是创建一个普通的Channel,特殊的地方在于yml中的配置。
第二步,生产者新建的Channel配置。
spring:
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binding 配置项,也没有什么特殊的
bindings:
output-transaction1:
destination: test-topic
content-type: text/plain
# Spring Cloud Stream RocketMQ 配置项
rocketmq:
# RocketMQ Binder 配置项,对应 RocketMQBinderConfigurationProperties 类
binder:
name-server: 127.0.0.1:9876 # RocketMQ Namesrv 地址
# RocketMQ 自定义 Binding 配置项,对应 RocketMQBindingProperties Map
bindings:
# 特殊的在于这里
output-transaction1:
# RocketMQ Producer 配置项,对应 RocketMQProducerProperties 类
producer:
group: test-transaction # 生产者分组
sync: true # 是否同步发送消息,默认为 false 异步。
transactional: true # 是否发送事务消息,默认为 false。
特殊的地方在于将“transactional”置为true。
第三步,生产者业务逻辑处理。
前面两步的配置,只是可以发送消息,但是真正的业务逻辑处理需要放在一个特殊的类中。
@RocketMQTransactionListener(txProducerGroup = "test-transaction")
public class TransactionListenerImpl implements RocketMQLocalTransactionListener {
private final static LogCollector LOG_COLLECTOR = LogCollector.getLogCollector(LoggerFactory.getLogger(TransactionListenerImpl.class));
@Override
public RocketMQLocalTransactionState executeLocalTransaction(Message message, Object o) {
String flag = message.getHeaders().getOrDefault("flag", "-1").toString();
if ("-1".equals(flag)) {
//消息处理异常(本地业务事务提交失败)取消发送,直接回滚
LOG_COLLECTOR.error("消息处理异常(本地业务事务提交失败)取消发送,直接回滚");
return RocketMQLocalTransactionState.ROLLBACK;
} else if ("1".equals(flag)) {
//消息处理产生了其它情况(比如文件写失败,可能有其它的保障机制),需要回查
LOG_COLLECTOR.warn("消息处理产生了其它情况(比如文件写失败,可能有其它的保障机制),需要回查");
return RocketMQLocalTransactionState.UNKNOWN;
}
//消息处理成功(本地业务事务提交完成)
LOG_COLLECTOR.info("消息处理成功(本地业务事务提交完成)");
return RocketMQLocalTransactionState.COMMIT;
}
@Override
public RocketMQLocalTransactionState checkLocalTransaction(Message message) {
LOG_COLLECTOR.info(message.getPayload().toString() + "回查完成");
return RocketMQLocalTransactionState.COMMIT;
}
}
executeLocalTransaction:真正的业务逻辑放在这里,上面代码中模拟的也算比较清晰了。
checkLocalTransaction:回查的业务逻辑放在这里,一般会检查一张本地表中的日志状态,确认最终的结果。
第四步,消费者。
对于消费者来说,没有任何特别的地方,该怎么接收还怎么接收就可以了,参照之前的《RocketMQ - 与Spring Cloud Stream结合》。
第五步,生产消息。
@ResponseBody
@RequestMapping(value = "sendTransaction", method = RequestMethod.GET)
public String sendTransactionMessage(@RequestParam(value = "flag", required = false) String flag) {
String messageId = IdUtil.simpleUUID();
Message<String> message = MessageBuilder
.withPayload("this is a test:" + messageId)
.setHeader(MessageConst.PROPERTY_TAGS, "testTransaction")
.setHeader("flag", StrUtil.isNotBlank(flag) ? flag : "-1")
.build();
try {
testChannel.outputTransaction().send(message);
return messageId + "发送成功";
} catch (Exception e) {
LOG_COLLECTOR.error(e.getMessage(), e);
return messageId + "发送失败,原因:" + e.getMessage();
}
}
以上,RocketMQ和Spring Cloud Stream结合,实现事务消息的示例,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
RocketMQ-消费者异常处理和图形化监控 | 字痕随行
在消费消息时,因为异常导致消费不成功的时候,RocketMQ默认会连续进行三次重试。
可以通过下面的代码测试一下:
@StreamListener("input1")
public void receiveInput1(@Payload Message message) throws ValidationException {
if (0 == count) {
//此处模拟的是接收消息时处理出错的情况,抛出异常之后,消息会重试消费
count++;
LOG_COLLECTOR.error("接收消息强制抛出错,次数:{},内容:{}", count, message.getPayload());
throw new ValidationException("接收消息强制抛出错误");
} else if (1 == count) {
count++;
LOG_COLLECTOR.error("接收消息强制抛出错,次数:{},内容:{}", count, message.getPayload());
throw new ValidationException("接收消息强制抛出错误");
} else if (2 == count) {
count++;
LOG_COLLECTOR.error("接收消息强制抛出错,次数:{},内容:{}", count, message.getPayload());
throw new ValidationException("接收消息强制抛出错误");
} else {
count = 0;
}
System.out.println("input1 receive: " + message.getPayload() + ", foo header: " + message.getHeaders().get("foo"));
}
运行时,就会输出:
com.etek.srv.examples.mq.consumer.TestService - 接收消息强制抛出错,次数:1,内容:this is a test:76d0dddeef02479090040f91319f7da3
com.etek.srv.examples.mq.consumer.TestService - 接收消息强制抛出错,次数:2,内容:this is a test:76d0dddeef02479090040f91319f7da3
com.etek.srv.examples.mq.consumer.TestService - 接收消息强制抛出错,次数:3,内容:this is a test:76d0dddeef02479090040f91319f7da3
在三次重试后,会抛出异常,可以通过以下方式捕捉异常:
//channel的格式为{destination}.{group}.errors
@ServiceActivator(inputChannel = "test-topic.test.errors")
public void handleError(ErrorMessage errorMessage) {
LOG_COLLECTOR.error("捕捉到了正在发生的异常");
}
如果希望通过图形化的方式对RocketMQ进行监控,可以使用rocketmq-console。
可以通过以下地址下载:
//原始地址
https://github.com/apache/rocketmq-externals
//加速地址
https://codechina.csdn.net/mirrors/apache/rocketmq-externals/
只需要加载rocketmq-externals的子工程rocketmq-console即可。
修改application.properties:
#改成不冲突的端口
server.port=8088
#指向本地的name server
rocketmq.config.namesrvAddr=localhost:9876
然后直接启动,就可以访问图形化监控界面了:
以上,就是本次的内容,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
RocketMQ-与SpringCloudStream结合 | 字痕随行
最近在加班,五一看了一遍《钢之炼金术师》,空闲时间又对Netty产生了兴趣,还得陪闺女,然后TBC怀旧又要蹭一波热度去,所以时间不够用,更新十分缓慢。
我在学习RocketMQ怎么和Spring Cloud结合的时候,首先被下面这个问题困扰:
Spring Cloud Bus和Spring Cloud Stream有什么不同?应用的场景都是什么样的?
后来吧,我得出了一个非常简单的结论,无论什么场景都用Spring Cloud Stream就完事了,因为Spring Cloud Bus是更抽象的封装,但凡场景复杂点就得重构,所以无脑直接用Spring Cloud Stream就行了。
当然了,这是我个人现在的想法,如果后面在使用过程中有变化,我会及时纠正我的错误观点的。
言归正传,这篇简单介绍一下RocketMQ和Spring Cloud的整合,也就是使用Spring Cloud Stream。
整体工程如下图所示:
第一步,引入最关键的Jar包:
消费者和生产者全都引入上面的包,其它主要的包:
第二步,消费者和生产者的通道:
因为Spring Cloud Stream把队列写入和读取高度抽象化了,是通过注解配合接口实现的。
所以,生产者需要声明:
public interface TestChannel {
@Output("output1")
MessageChannel output1();
}
消费者需要声明:
public interface TestChannel {
@Input("input1")
SubscribableChannel input1();
}
这里需要特殊说明一下的是:
- 生产者的注解是Output,消费者的注解是Input,千万别搞错了。
- TestChannel这个类名不必一样,这里一样是因为偷懒。
- output1和input1,可以设置为你想要的任意字符串,只需要和yml文件中配置的对应就可以。
- MessageChannel和SubscribleChannel不要搞错了。
第三步,最重要的注解:
在启动类上方增加关键注解:
@SpringBootApplication
@EnableBinding({TestChannel.class})
public class MqProduceExampleApplication {
public static void main(String[] args) {
SpringApplication.run(MqProduceExampleApplication.class, args);
}
}
消费者入口类上也要增加一样的注解。
第四步,yml配置文件:
生产者:
spring:
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binding 配置项,对应 BindingProperties Map
bindings:
output1:
destination: test-topic # 目的地。这里使用 RocketMQ Topic
content-type: text/plain # 内容格式。这里使用 JSON
# Spring Cloud Stream RocketMQ 配置项
rocketmq:
# RocketMQ Binder 配置项,对应 RocketMQBinderConfigurationProperties 类
binder:
name-server: 127.0.0.1:9876 # RocketMQ Namesrv 地址
# RocketMQ 自定义 Binding 配置项,对应 RocketMQBindingProperties Map
bindings:
output1:
# RocketMQ Producer 配置项,对应 RocketMQProducerProperties 类
producer:
group: test # 生产者分组
sync: true # 是否同步发送消息,默认为 false 异步。
消费者:
spring:
cloud:
stream:
bindings:
input1:
destination: test-topic
content-type: text/plain
group: test
rocketmq:
binder:
name-server: 127.0.0.1:9876
bindings:
input1:
consumer:
tags: test
第五步,生产消息:
@Resource
private TestChannel testChannel;
@ResponseBody
@RequestMapping(value = "send", method = RequestMethod.GET)
public String sendMessage() {
String messageId = IdUtil.simpleUUID();
Message<String> message = MessageBuilder
.withPayload("this is a test:" + messageId)
.setHeader(MessageConst.PROPERTY_TAGS, "test")
.build();
try {
testChannel.output1().send(message);
return messageId + "发送成功";
} catch (Exception e) {
LOG_COLLECTOR.error(e.getMessage(), e);
return messageId + "发送失败,原因:" + e.getMessage();
}
}
第六步,消费消息:
@StreamListener("input1")
public void receiveInput1(@Payload Message message) throws ValidationException {
System.out.println("input1 receive: " + message.getPayload() + ", foo header: " + message.getHeaders().get("foo"));
}
只要配置文件和注解搞对了,使用上没有什么技术难点。
以上,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
Cursor-探寻CommitLog的创建时机 | 字痕随行
事情的起源来自于我看一篇介绍RocketMQ CommitLog的文章。
大多数文章介绍这部分都会提到,CommitLog由多个磁盘文件组成,每个文件的最大容量为1G,当一个文件写满后就会创建一个新的文件继续写。
我在这里比较好奇的是,当一个新的消息到达的时候,它的处理规则是哪种:
- 直接追加,当追加到满1G的时候,创建一个新的文件,然后在新的文件中写入剩余的消息。
- 先判断,如果当前的文件容量已经不足以写入整个消息时,创建一个新的文件,将完整的消息写入新的文件。
我倾向于第二种,因为所有的介绍都会说“最大”、“至多”,而没有说“相等”。
但是,我查了一下资料,却没有找到特定的答案,所以只能去看源码了。
看源码很累,我又不想耗费很多的时间在这上面,所以我想让Cursor帮助我,看看能不能节省一些时间。
首先,我已经知道了CommitLog的位置,并且知道写入消息的方法:
//CommitLog.java在store这个包内
public CompletableFuture<PutMessageResult> asyncPutMessage(final MessageExtBrokerInner msg) {}
然后,找到相关的代码:
result = mappedFile.appendMessage(msg, this.appendMessageCallback, putMessageContext);
选中这段代码,打开chat窗口,询问这段代码的作用,以下是对这段代码的解释:
所选代码块是rocketmq项目中CommitLog.java文件中的一行代码。具体来说,它在mappedFile对象上调用appendMessage方法,将msg、this.appendMessageCallback和putMessageContext作为参数传递。
根据前面提供的代码块中提供的上下文,似乎这段代码是处理将消息存储在提交日志中的更大方法的一部分。appendMessage方法可能负责实际将消息写入磁盘。
没有更多的上下文,很难说这行代码在做什么或其目的是什么。但是,它似乎是rocketmq项目中消息存储过程的重要部分。
然后,看看返回的result代表什么?
根据代码中的switch语句,result.getStatus()可能返回以下值:
- APPENDOK:消息追加成功
- ENDOFFILE:当前MappedFile已满,需要创建新的MappedFile
- MESSAGESIZEEXCEEDED:消息大小超过了最大限制
- PROPERTIESSIZEEXCEEDED:消息属性大小超过了最大限制
- UNKNOWNERROR:未知错误发生
上文中的appendMessage()最终会调用:
public AppendMessageResult appendMessagesInner(final MessageExt messageExt, final AppendMessageCallback cb,
PutMessageContext putMessageContext) {}
这个方法里面的关键点是:
int currentPos = WROTE_POSITION_UPDATER.get(this);
对这段代码的解释如下:
用户问题:
int currentPos 这个变量有什么作用?
回答:
在所选代码块中,currentPos 变量用于跟踪映射文件中的当前写入位置。它通过调用 WROTE_POSITION_UPDATER 对象的 get 方法获得,该对象是一个 AtomicIntegerFieldUpdater,用于更新 DefaultMappedFile 类中的 wrotePosition 字段。
当 currentPos 小于 fileSize 时,意味着映射文件中仍有空间可以写入更多数据。然后,appendMessage 方法创建一个 ByteBuffer 对象,该对象从 currentPos 开始,容量为 fileSize - currentPos。这个 ByteBuffer 与要写入的消息数据一起传递给 AppendMessageCallback 对象的 doAppend 方法。
在消息数据写入映射文件后,使用 WROTE_POSITION_UPDATER 对象的 addAndGet 方法更新 wrotePosition 字段,并使用 doAppend 方法返回的时间戳更新 storeTimestamp 字段。最后,返回 AppendMessageResult 对象。
再看cb.append()方法里面的maxBlank参数,这个参数的赋值如下:
this.fileSize - currentPos
相当于是当前CommitLog这个文件的剩余容量,之后在cb.append()内部执行的时候,就会看msg的大小是否在剩余容量之内:
// Determines whether there is sufficient free space
if ((msgLen + END_FILE_MIN_BLANK_LENGTH) > maxBlank) {
this.msgStoreItemMemory.clear();
// 1 TOTALSIZE
this.msgStoreItemMemory.putInt(maxBlank);
// 2 MAGICCODE
this.msgStoreItemMemory.putInt(CommitLog.BLANK_MAGIC_CODE);
// 3 The remaining space may be any value
// Here the length of the specially set maxBlank
final long beginTimeMills = CommitLog.this.defaultMessageStore.now();
byteBuffer.put(this.msgStoreItemMemory.array(), 0, 8);
return new AppendMessageResult(AppendMessageStatus.END_OF_FILE, wroteOffset,
maxBlank, /* only wrote 8 bytes, but declare wrote maxBlank for compute write position */
msgIdSupplier, msgInner.getStoreTimestamp(),
queueOffset, CommitLog.this.defaultMessageStore.now() - beginTimeMills);
}
所以,最后得出的结论就是:如果msg的大小超出了当前CommitLog的剩余容量,就会重新建立一个文件,将msg完整的追加到新的文件内。
说一下体会吧,大概就是连自身的提炼总结都省了,直接划拉上代码开问,给出的答案足够指引自身获得目标结果,能够节省大量,可能会喜欢上读代码。
以上,如果有错误,欢迎探讨和指正。
觉的不错?可以关注我的公众号↑↑↑
这篇文章源自我想试验一下:一个Flowable应用作为流程模型发布端,其它应用接收到发布请求后,在本地进行部署。
这中间消息队列就是必不可少的组件,正好Rocketmq的最新版本也已经到5了,索性一起试验一下。
部署
很早之前有一篇文章介绍过如何在本地部署Rocketmq,当时的版本还是4.8.0。部署5.1.x时大部分的坑和关键点还是一样的,照着配置一下就可以了。
最大的不同在于5.1.x增加了Proxy,所以除了要像之前启动Namesrv、Broker之外,还要启动Proxy。
如果没有启动Proxy,又按照下文的方式生成消息,就会报出gRpc异常。
这里给出常用的启动命令以供参考:
# 启动namesrv,默认情况下,会占用9876端口
.\mqnamesrv.cmd
# 启动broker
.\mqbroker.cmd -n 127.0.0.1:9876 autoCreateTopicEnable=true
# 启动proxy,proxy默认占用8081端口
.\mqproxy -n 127.0.0.1:9876 -pc ..\conf\rmq-proxy.json
Java客户端
此处以SpringBoot集成为例,starter的仓库地址如下:
https://github.com/apache/rocketmq-spring
这个仓库最后一次release版本是2.2.3,并不支持Rocketmq5。如果只是想为了测试一把比较方便的话,可以使用snapshot版本。
使用的方式是:
- 把master分支pull到本地。
- 使用Maven install命令,把v5部分安装到本地仓库。
- 可以使用Maven引入了。
最后引入的方式如下:
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-v5-client-spring-boot-starter</artifactId>
<version>2.2.4-SNAPSHOT</version>
</dependency>
示例代码
生产者
application.properties:
# rocketmq
rocketmq.producer.endpoints=localhost:8081
rocketmq.producer.topic=normalTopic
发送消息:
@RestController
@RequestMapping("test")
public class TestController {
@Resource
private RocketMQClientTemplate rocketMQClientTemplate;
@GetMapping("pushMessage")
public void pushMessage() {
SendReceipt sendReceipt = rocketMQClientTemplate.syncSendNormalMessage(
"normalTopic",
new HashMap<String, String>(){{
put("name", "test");
}});
System.out.printf("normalSend to topic %s sendReceipt=%s %n", "normalTopic", sendReceipt);
}
}
消费者
application.properties:
# rocketmq
rocketmq.simple-consumer.endpoints=localhost:8081
rocketmq.simple-consumer.consumer-group=normalGroup
rocketmq.simple-consumer.topic=normalTopic
rocketmq.simple-consumer.tag=*
rocketmq.simple-consumer.filter-expression-type=tag
消费消息:
@Service
@RocketMQMessageListener(
endpoints = "${rocketmq.simple-consumer.endpoints:}",
topic = "${rocketmq.simple-consumer.topic:}",
consumerGroup = "${rocketmq.simple-consumer.consumer-group:}",
tag = "${rocketmq.simple-consumer.tag:}")
public class DefaultMQListener implements RocketMQListener {
@Override
public ConsumeResult consume(MessageView messageView) {
System.out.println("handle my message:" + messageView);
String msgBody = Charset.defaultCharset().decode(messageView.getBody()).toString();
System.out.println("message body:" + msgBody);
return ConsumeResult.SUCCESS;
}
}
SpringCloudGateway简单入门 | 字痕随行
Spring Cloud Gateway早就被玩烂了,所以这篇也不是什么教程,顶多算是个人总结/记录而已。
由来是因为要用Swagger,但是面向服务的系统,如果只是单独的集成Swagger就显得很混乱,所以需要Knife4j的分布式文档支持。
从我的理解上来讲,Gateway的作用就如同Nginx,是一个独立的服务,用来将所有的请求进行过滤、转发。从目前我使用的情况来看,它与其它服务是解耦的,无侵入的。
新建一个SpringBoot工程,pom文件主体如下:
入口类的代码如下:
@SpringBootApplication
@EnableDiscoveryClient
public class ExampleGatewayApp {
public static void main(String[] args) {
SpringApplication.run(ExampleGatewayApp.class, args);
}
@Bean
LoadBalancerInterceptor loadBalancerInterceptor(LoadBalancerClient loadBalance) {
return new LoadBalancerInterceptor(loadBalance);
}
}
yml配置文件如下:
server:
port: 8082
compression:
enabled: true
mime-types: application/json,application/xml,text/html,text/xml,text/plain
spring:
http:
encoding:
charset: UTF-8
application:
name: examples-gateway
cloud:
nacos:
discovery:
server-addr: localhost:8848
gateway:
discovery:
locator:
enabled: true
routes:
- id: examples-service-http-provider-route
uri: lb://examples-service-http-provider
predicates:
- Path=/http-service/**
filters:
- StripPrefix=1
main:
allow-bean-definition-overriding: true
然后,运行,一个网关服务就运行起来了。作为一个示例项目,确实非常简单。
yml里面的spring.cloud.gateway就是网关的主要配置。
discovery.locator.enabled为true,代表自动发现服务,比如这个示例的Nacos注册了一个标识为examples-service-http-provider的服务,就可以使用http://localhost:8082/examples-service-http-provider/*来访问服务内的接口。
routes,代表路由配置信息。
- uri中的lb代表负载均衡,指的是LoadBalanced。
- predicates指的是需要转发的路径配置。
- StripPrefix代表转发时,需要忽略的前缀。
这里配置的就是将所有http://localhost:8082/http-service/**的请求,通过负载均衡转发到http://examples-service-http-provider/**。
如果没有配置StripPrefix,就会转发到http://examples-service-http-provider/http-service/**(最开始我就在这里掉坑里了)。
以上,如果有错误,欢迎探讨和指正。

觉的不错?可以关注我的公众号↑↑↑
SpringCloudAlibaba-莫名其妙的异常 | 字痕随行
每一次对莫名其妙发生的异常刨根问底的时候,都是非常痛苦的经历,脑仁要炸掉的感觉。
本文基于:
Spring Cloud Alibaba 2.2.0.Release
Dubbo
最近吧,应用越来越多,规范也越来越重要,就想把Nacos的配置中心用起来。
去年已经进行过初步调研,这次算是再拾掇一下,感觉应该没什么难度。
开始在示例工程里面写例子的时候,还是相当轻松愉快的,但是想要替换一个工程落地测试一下的时候,画风就突变了。
简单说一下变更的过程:无非就是改了个配置文件,把之间在Application里面的一部分配置挪到了Bootstrap里面,然后引入了:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
然后启动的时候就抛异常了:
Caused by: java.lang.IllegalStateException: No registry config found or it's not a valid config! The registry config is: <dubbo:registry valid="false" zookeeperProtocol="false" prefix="dubbo.registry" />
最开始,看提示,感觉是配置有问题,所以翻来覆去检查了一下配置文件,得出的结论是:配置文件没问题。
那就搜一搜吧,百度搜出来的东西五花八门,没什么用。
Google还得翻墙,图简单就用Bing搜了一下,出来一堆issues,大概看了一下,感觉要升版。
于是呢,升了一下Spring Cloud Alibaba的小版本,从2.2.0升到了2.2.2。
然后启动,异常不再发生(但是,这异常发生的原因其实跟版本没什么关系)。
可是,这一切到底是为什么呢?
示例工程和实际工程没什么太大区别,引入的Jar包基本一样,配置文件的内容也全都一样,在使用2.2.0版本的时候,为什么一个报错,一个异常?
开始刨根问底吧。
1. 版本到底升了什么?
Spring Cloud Alibaba 2.2.0.Release到2.2.2Release,关键的不同在于Dubbo的版本。
一个使用的是2.7.4.1,一个使用的是2.7.8。
我去看了一下版本发布的提交日志,然后发现RegistryConfig的相关Fix在这之间做了大量的修复。
但是我仍旧没法定位到具体的Commit,看了一遍提交的日志,感觉是在大海捞针,直接放弃了。
2. 跟踪代码
既然是RegistryConfig的问题,那直接在实例化的地方打断点一点一点跟踪吧。
一点一点走下去,会发现两个特别的地方。
一个就是触发RegistryConfig实例化的位置。
无异常的示例项目,在AbstractApplicationContext触发实例化是在:
this.finishBeanFactoryInitialization(beanFactory);
而发生异常的项目,触发实例化是在:
this.registerBeanPostProcessors(beanFactory);
执行的顺序如下图所示:
再一个就是BeanPostProcessor的数量。
未发生异常的项目中,BeanPostProcessor的数量要远大于发生异常的项目,多了很多Dubbo扩展的BeanPostProcessor。
但是,到这里还是没有什么头绪,一样的工程结构,差不多的代码,为什么会出现完全不一样的情况。
3. 执行的顺序。
既然上面的情况完全不一样,那就看看执行的过程到底是怎样的吧。
从断点的监视器,一点一点往下捋,最后终于找到了一个点:
RequestBodyServiceParameterResolver这个Bean实例化的时候,需要MessageConvert,继而需要MappingJackson2HttpMessageConverter。
巧合的是,项目中需要自定义Date类型的转换,所以自定义了MappingJackson2HttpMessageConverter。
更巧的是,当时把MappingJackson2HttpMessageConverter这个自定义类的实例化放到了WebMvcConfigurer。
平常没什么问题,但是使用Nacos当配置中心的时候,Spring MVC的一些配置都在Nacos里面,这时候需要远程去取。
就需要实例化RegistryConfig,但是RegistryConfig这时候的配置根本不对,所以直接就抛异常了。
4. 解决办法。
解决办法很简单,别触发RegistryConfig实例化就行。那就需要不触发配置读取,所以直接把MappingJackson2HttpMessageConverter自定义类放到一个单独的配置类即可。
再启动终于正常了,但是为什么升了版本就没事了呢?
5. 升个版本继续断点调试追踪。
升了版本之后,会发现在BeanPostProcessor中多了一个对象:
com.alibaba.spring.beans.factory.annotation.ConfigurationBeanBindingPostProcessor
这个类存在于:
<dependency>
<groupId>com.alibaba.spring</groupId>
<artifactId>spring-context-support</artifactId>
</dependency>
然后去查看Dubbo的Commit日志,就会发现,中间这个包升过一次版。
成了,痛苦就到这,再扒就得折腾一遍源码了,以下是这次的一些参考:
https://github.com/apache/dubbo-spring-boot-project/issues/643
https://github.com/apache/dubbo/pull/5710
https://github.com/apache/dubbo/issues/6039
https://blog.csdn.net/caihaijiang/article/details/35552859
以上,如果有错误,欢迎探讨和指正。
觉的不错?可以关注我的公众号↑↑↑
Dubbo–Http协议实现Restful接口 | 字痕随行
每天开车望红灯,时间都被浪费在路上,无奈。
本章记录一下如何使用Http协议实现Restful接口,如果想了解Rest协议的实现,可以看这里:Dubbo - Rest协议实现Restful接口。
本示例基于:
Spring Boot 2.2.5.RELEASE
Spring Cloud vHoxton.SR3
Spring Cloud Alibaba 2.2.0.RELEASE
provider的pom文件引入Jar包如下:
<dependencies>
<!-- Spring Boot -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency>
<!--服务注册与发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-dubbo</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-nacos-discovery</artifactId>
</dependency>
<!--对外接口-->
<dependency>
<groupId>com.xxxx</groupId>
<artifactId>xxxx-examples-service-api</artifactId>
</dependency>
</dependencies>
application.yml配置如下:
server:
port: 8081
compression:
enabled: true
mime-types: application/json,application/xml,text/html,text/xml,text/plain
dubbo:
scan:
base-packages: com.xxxx.examples.service.http.provider
protocols:
dubbo:
name: dubbo
port: -1
registry:
address: spring-cloud://localhost
spring:
http:
encoding:
charset: UTF-8
application:
name: xxxx-examples-service-http-provider
cloud:
nacos:
discovery:
server-addr: localhost:8848
main:
allow-bean-definition-overriding: true
测试用的对外接口实现类如下:
@RestController
@RequestMapping(("/example/service/test"))
@Service(protocol = {"dubbo"})
public class TestApiServiceImpl implements TestApiService {
@Override
@GetMapping("echo")
public String echoString() {
return "hello, welcome";
}
@Override
@GetMapping("echo/{id}")
public String echoString(@PathVariable String id) {
return "you input: " + id;
}
}
启动类如下:
@SpringBootApplication
@EnableDiscoveryClient
public class ExampleServiceHttpProviderApp
{
public static void main( String[] args )
{
SpringApplication.run(ExampleServiceHttpProviderApp.class, args);
}
}
consumer的pom文件如下:
<dependencies>
<!-- spring boot web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency>
<!--服务注册与发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-dubbo</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-nacos-discovery</artifactId>
</dependency>
<!--对外接口-->
<dependency>
<groupId>com.xxxx</groupId>
<artifactId>xxxx-examples-service-api</artifactId>
</dependency>
</dependencies>
接口的调用方式和上一篇一样:
//注意LoadBalanced
@Configuration
public class RestConfig {
@Bean
@LoadBalanced
@DubboTransported
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
@RestController
@RequestMapping("test")
public class TestController {
@Reference
private TestApiService testApiService;
@Resource
private RestTemplate restTemplate;
@GetMapping("/rpc/echo")
public String echoRpc() {
String echoString = testApiService.echoString();
return echoString;
}
@GetMapping("/rest/echo")
public String echoRest() {
try {
//注意使用服务名称调用
String echoString = restTemplate.getForObject("http://xxx-examples-service-http-provider/example/service/test/echo", String.class, "1");
return echoString;
} catch (Exception e) {
return null;
}
}
}
启动类也是一样的:
@SpringBootApplication
@EnableDiscoveryClient
public class ExampleServiceConsumerApp
{
public static void main( String[] args )
{
SpringApplication.run(ExampleServiceConsumerApp.class, args);
}
}
以上,如果有错误,欢迎探讨和指正。

觉的不错?可以关注我的公众号↑↑↑
Dubbo–Rest协议实现Restful接口 | 字痕随行
最近做了一些Dubbo的示例,在此记录一下。
本章记录一下使用Rest协议实现Http Restful接口。
本示例基于:
Spring Boot 2.2.5.RELEASE
Spring Cloud vHoxton.SR3
Spring Cloud Alibaba 2.2.0.RELEASE
Netty 4.1.42.final
Resteasy 3.11.0.Final
provider的pom文件引入Jar包如下:
<dependencies>
<!--单元测试-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--服务注册与发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-dubbo</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-nacos-discovery</artifactId>
<exclusions>
<!-- 过滤掉jsr311,防止与rs-api冲突,导致缺少method -->
<exclusion>
<groupId>javax.ws.rs</groupId>
<artifactId>jsr311-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Dubbo REST support dependencies -->
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
</dependency>
<dependency>
<groupId>org.jboss.resteasy</groupId>
<artifactId>resteasy-client</artifactId>
</dependency>
<dependency>
<groupId>org.jboss.resteasy</groupId>
<artifactId>resteasy-netty4</artifactId>
</dependency>
<dependency>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
</dependency>
<dependency>
<groupId>org.hibernate.validator</groupId>
<artifactId>hibernate-validator</artifactId>
</dependency>
<!--对外接口-->
<dependency>
<groupId>com.xxx</groupId>
<artifactId>xxx-examples-service-api</artifactId>
</dependency>
</dependencies>
application.yml配置如下:
dubbo:
scan:
base-packages: com.xxx.examples.service.rest.provider
protocols:
dubbo:
name: dubbo
port: -1
rest:
name: rest
port: 8888
server: netty
registry:
address: spring-cloud://localhost
spring:
application:
name: xxx-examples-service-rest-provider
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
main:
allow-bean-definition-overriding: true
测试用的对外接口实现类如下:
/**
* 服务示例对外测试接口实现
*/
@Path("/example/service/test")
@Service(protocol = {"dubbo", "rest"})
public class TestApiServiceImpl implements TestApiService {
@GET
@Path("echo")
@Override
public String echoString() {
return "hello, welcome";
}
@GET
@Path("echo/{id}")
@Override
public String echoString(@PathParam("id") String id) {
return "you input: " + id;
}
}
启动类如下:
/**
* 服务示例对外测试接口实现
*/
@SpringBootApplication
@EnableDiscoveryClient
public class ExampleServiceRestProviderApp
{
public static void main( String[] args )
{
new SpringApplicationBuilder(ExampleServiceRestProviderApp.class)
.web(WebApplicationType.NONE)
.run(args);
}
}
consumer的pom文件如下:
<dependencies>
<!--单元测试-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- spring boot web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency>
<!--服务注册与发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-dubbo</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-nacos-discovery</artifactId>
<exclusions>
<!-- 过滤掉jsr311,防止与rs-api冲突,导致缺少method -->
<exclusion>
<groupId>javax.ws.rs</groupId>
<artifactId>jsr311-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Dubbo REST support dependencies -->
<dependency>
<groupId>org.jboss.resteasy</groupId>
<artifactId>resteasy-client</artifactId>
</dependency>
<dependency>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
</dependency>
<dependency>
<groupId>org.hibernate.validator</groupId>
<artifactId>hibernate-validator</artifactId>
</dependency>
<!--对外接口-->
<dependency>
<groupId>com.xxx</groupId>
<artifactId>xxx-examples-service-api</artifactId>
</dependency>
</dependencies>
application.yml配置如下:
server:
port: 8082
compression:
enabled: true
mime-types: application/json,application/xml,text/html,text/xml,text/plain
dubbo:
registry:
address: spring-cloud://localhost
cloud:
# The subscribed services in consumer side
subscribed-services: xxx-examples-service-rest-provider
spring:
http:
encoding:
charset: UTF-8
application:
name: xxx-examples-service-consumer
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
main:
allow-bean-definition-overriding: true
接口调用如下:
//注意LoadBalanced
@Configuration
public class RestConfig {
@Bean
@LoadBalanced
@DubboTransported
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
@RestController
@RequestMapping("test")
public class TestController {
@Reference
private TestApiService testApiService;
@Resource
private RestTemplate restTemplate;
@GetMapping("/rpc/echo")
public String echoRpc() {
String echoString = testApiService.echoString();
return echoString;
}
@GetMapping("/rest/echo")
public String echoRest() {
try {
//注意使用服务名称调用
String echoString = restTemplate.getForObject("http://xxx-examples-service-rest-provider/example/service/test/echo", String.class, "1");
return echoString;
} catch (Exception e) {
return null;
}
}
}
启动类如下:
@SpringBootApplication
@EnableDiscoveryClient
public class ExampleServiceConsumerApp
{
public static void main( String[] args )
{
SpringApplication.run(ExampleServiceConsumerApp.class, args);
}
}
以上,如果有错误,欢迎探讨和指正。
觉的不错?可以关注我的公众号↑↑↑
Dubbo–NoSuchMethodErrorGetHeaderString异常 | 字痕随行
最近搭建项目结构做示例的时候,遇到了一个非常奇怪的问题,解决的时间有点长,所以记录一下整个过程。
这个问题的出现,是在使用rest协议提供对外服务的时候 (Spring Cloud Alibaba 2.1和2.2版本都有此问题) 。如果懒的看整体解决过程的,只想尝试解决办法的,可以试试在pom文件中增加:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-nacos-discovery</artifactId>
<exclusions>
<!-- 过滤掉jsr311,防止与rs-api冲突,导致缺少method -->
<exclusion>
<groupId>javax.ws.rs</groupId>
<artifactId>jsr311-api</artifactId>
</exclusion>
</exclusions>
</dependency>
下面就开始正文了。
项目是很简单的一个示例,基于Spring Cloud Alibaba的,使用Nacos作为服务管理的平台,使用Dubbo作为RPC组件,同时使用dubbo和rest协议对外提供服务接口,pom文件的整体是这样的:
<dependencies>
<!--单元测试-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- spring boot web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency>
<!--服务注册与发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-dubbo</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- Dubbo REST support dependencies -->
<dependency>
<groupId>org.jboss.resteasy</groupId>
<artifactId>resteasy-client</artifactId>
</dependency>
<dependency>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
</dependency>
<dependency>
<groupId>org.hibernate.validator</groupId>
<artifactId>hibernate-validator</artifactId>
</dependency>
<!--对外接口-->
<dependency>
<groupId>com.xxx</groupId>
<artifactId>xxx-examples-service-api</artifactId>
</dependency>
</dependencies>
代码也很简单:
@Path("/example/service/test")
@Service(protocol = {"dubbo", "rest"})
public class TestApiServiceImpl implements TestApiService {
@GET
@Path("echo")
@Override
public String echoString() {
return "hello, welcome";
}
@GET
@Path("echo/{id}")
@Override
public String echoString(@PathParam("id") String id) {
return "you input: " + id;
}
@Override
public TestDTO getDto() {
TestDTO testDTO = new TestDTO();
testDTO.setCode("0");
testDTO.setMsg("success");
return testDTO;
}
}
启动的时候没有任何异常,但是在调用接口的时候,异常就产生了:
HTTP ERROR 500 java.lang.NoSuchMethodError: javax.ws.rs.core.HttpHeaders.getHeaderString(Ljava/lang/String;)Ljava/lang/String;
URI: /example/service/test/echo
Caused by:
java.lang.NoSuchMethodError: javax.ws.rs.core.HttpHeaders.getHeaderString(Ljava/lang/String;)Ljava/lang/String;
这种异常很常见,无非就是缺包和包冲突,如果去百度一下,能发现一万种相同的解决办法。
从整个项目的情况上来看,该引入的包都引入了,而且第一步也尝试了增加:
<dependency>
<groupId>javax.ws.rs</groupId>
<artifactId>javax.ws.rs-api</artifactId>
</dependency>
但是没有任何效果(后来发现,加在最顶部可以解决问题)。然后就去找了官方示例和百度了N多示例去做比对,发现和项目的配置并没有什么出入。
没办法,只能按照错误日志去追源码了,发现是在下面这个类中报出的错误:
org.jboss.resteasy.core.interception.PreMatchContainerRequestContext
相关的方法是:
public String getHeaderString(String name) {
return this.httpRequest.getHttpHeaders().getHeaderString(name);
}
在这个方法中,getHttpHeaders()返回的类型是:
javax.ws.rs.core.HttpHeaders
那就是这个类有问题,最有可能的就是包冲突,然后在寻找可疑冲突包的过程中,发现了:
这个包从哪来的呢?使用Idea自带的dependencies查看器,发现是由ribbon-httpclient引入的,最终导致引入的包是spring-cloud-alibaba-nacos-discovery。
解决办法就像本文开头描述的,将这个jsr311从discovery中替掉即可,替换此包的所导致的问题暂时还未发现。
以上,如果有错误,欢迎探讨和指正。
觉的不错?可以关注我的公众号↑↑↑
OAuth 2.0协议简析 | 字痕随行
OAuth2.0是一个授权协议,CAS对其有单独的模块支持,可以简单了解一下。
网络上的资料很多了,我这里就拣一些重要的说了。
本文基于文件RFC-6749介绍,这个文件的英文原版地址如下:
https://tools.ietf.org/html/rfc6749
当然了,肯定有爱心人士翻译成中文:
https://github.com/jeansfish/RFC6749.zh-cn
如果读者没接触过这个协议,想要了解的话,我建议英文和中文对照着看,中文便于理解,而英文更准确、更利于之后作为参照物。
好了,资料出处列举完毕,下面就是理解的关键点了。
授权许可(Authorization Grant)
为什么先说这个,因为整个协议其实都是围绕着这个来的,它定义了四种方式来获得授权,相当于框定了一个范围。
当然了,也可以扩展许可,相当于自定义,不过一般情况下,谁没事闲的非得自己实现一下。
这四种方式分别是:
- 授权码(Authorization Code)
- 隐式授权(Implicit)
- 资源所有者密码凭据(Resource Owner Password Credentials)
- 客户端凭据(Client Credentials)
一般来说,我们所见到的都是基于第一种方式,既然是捡重点的说,那本文就只分析第一种,其它的有时间各位可以自行了解。
授权码许可(Authorization Code Grant)
这是一个基于重定向的流程,客户端必须能够与资源所有者的用户代理(通常是Web浏览器)进行交互并能够接收来自授权服务器的传入请求(通过重定向)。
举个例子,微信公众号或者企业微信自建应用,通过菜单访问自建应用的时候,要获取当前用户信息,就要按照固定格式拼装一个特别长的携带参数的链接,那个链接触发后会在微信服务器、浏览器、我方服务器之间来回跳转,就是基于这种方式的。
基本的过程如下:
+----------+
| Resource |
| Owner |
| |
+----------+
^
|
(B)
+----|-----+ Client Identifier +---------------+
| -+----(A)-- & Redirection URI ---->| |
| User- | | Authorization |
| Agent -+----(B)-- User authenticates --->| Server |
| | | |
| -+----(C)-- Authorization Code ---<| |
+-|----|---+ +---------------+
| | ^ v
(A) (C) | |
| | | |
^ v | |
+---------+ | |
| |>---(D)-- Authorization Code ---------' |
| Client | & Redirection URI |
| | |
| |<---(E)----- Access Token -------------------'
+---------+ (w/ Optional Refresh Token)
授权码许可 - 第一步 - 授权请求(Authorization Request)
这里给了一个例子:
GET /authorize?response_type=code&client_id=s6BhdRkqt3&state=xyz&redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1
Host: server.example.com
这里用GET请求了authorize这个地址,其实在协议文档里面,只定死了请求这个地址时传入的参数,没有定死这个地址,所以我认为地址可以随意指定,但是一般为了方便,默认就用例子里面的了。
固定的传入参数:
- response_type
必需的。值必须被设置为“code”。
- client_id
必需的。如2.2节所述的客户端标识。
- redirect_uri
可选的。如3.1.2节所述。
- scope
可选的。如3.3节所述的访问请求的范围。
- state
推荐的。客户度用于维护请求和回调之间的状态的不透明的值。当重定向用户代理回到客户端时,授权服务器包含此值。该参数应该用于防止如10.12所述的跨站点请求伪造。
以上,带章节的注释说明需要自行查看,在这不会详细说了。
这一步就是发起认证请求,发起的请求要按照指定的方式来传参,这就相当于浏览器里面输入了一个链接,会跳到目标服务器(验证服务器)的指定地址。
授权码许可 - 第二步 - 授权响应(Authorization Response)
这里的例子:
HTTP/1.1 302 Found
Location: https://client.example.com/cb?code=SplxlOBeZQQYbYS6WxSbIA&state=xyz
如果注意到了第一步里面的redirect_uri这个参数,就知道这是验证服务器发起了重定向,将浏览器页面重定向到redirect_uri。
同时,按照协议要求,携带了两个参数:
- code
必需的。授权服务器生成的授权码。授权码必须在颁发后很快过期以减小泄露风险。推荐的最长的授权码生命周期是10分钟。客户端不能使用授权码超过一次。如果一个授权码被使用一次以上,授权服务器必须拒绝该请求并应该撤销(如可能)先前发出的基于该授权码的所有令牌。授权码与客户端标识和重定向URI绑定。
- state
必需的,若“state”参数在客户端授权请求中提交。从客户端接收的精确值。
授权码许可 - 第三步 - 访问令牌请求(Access Token Request)
这一步,就要用第二步中的code换取access token了:
POST /token HTTP/1.1
Host: server.example.com
Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
Content-Type: application/x-www-form-urlencoded
grant_type=authorization_code&code=SplxlOBeZQQYbYS6WxSbIA&redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb
这一步,就不是在浏览器里面跳转做了,而是由客户端获取code之后,由客户端直接请求服务器进行验证。
像我们写的应用,就是由浏览器前端把code发送回应用后端,然后后端用java http client请求验证服务器,来获取返回的token。
这一步携带的参数如下:
- grant_type
必需的。值必须被设置为“authorization_code”。
- code
从授权服务器收到的授权码。
- redirect_uri
必需的,若“redirect_uri”参数如4.1.1节所述包含在授权请求中,且他们的值必须相同。
- client_id
必需的,如果客户端没有如3.2.1节所述与授权服务器进行身份认证。
这一步还要获得token,所以会到最后一步。
授权码许可 - 第四步 - 访问令牌响应(Access Token Response)
验证成功后,验证服务器会返回一段json:
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Cache-Control: no-store
Pragma: no-cache
{
"access_token":"2YotnFZFEjr1zCsicMWpAA",
"token_type":"example",
"expires_in":3600,
"refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA",
"example_parameter":"example_value"
}
至此,可以拿着token去访问其它的资源或者数据了。
最后
其它的授权许可方式可以自行去看看协议文档,当然协议文档中还包含了一些其它的定义,比如名词解释、错误处理等等。本文只是帮助没接触过该协议或者一头雾水的人员入个门而已。
按照这个文档,实现四种授权许可方式,就代表支持OAuth2.0认证了。
接下来,会介绍一下,在CAS5.3中该如何支持OAuth2.0认证。
如果有问题,欢迎指正讨论。

觉的不错?可以关注我的公众号↑↑↑
CAS5.3-自定义准备 | 字痕随行
接下来会用几个篇幅的时间,记录一下如何定制自己的CAS Server。
使用CAS做单点登录也有年头了,貌似也没怎么详细记录过,这次也只能算个备忘,因为用的版本也很旧了。
为什么使用CAS 5.3.16这个版本?
高版本开始使用JDK11,另外使用Gradle编译。5.3.16这个版本支持JDK8,并且使用Maven编译,比较容易和目前的现实情况搭边。
从哪里获得源码?
Github因为某些不可描述的问题,时灵时不灵,所以可以从Gitee上获得源码:
https://gitee.com/mirrors/CAS/tree/v5.3.16
不过这是CAS的源码,我们自定义的基础不是源码,而是另外一个工程:
https://github.com/apereo/cas-overlay-template
同上原因,如果github不能访问,可以使用Gitee的导入功能,制作一份仓库镜像。
这是个Maven Template工程,简单来说就是我们在相同路径下创建的同名文件会覆盖原项目中的文件,从而达到定制的目的。
如何创建项目?
从远程仓库拉取一份源码至本地,如下图:
在Idea中打开此项目,经过漫长的处理之后,工程的结构如下:
在这个项目中,主要关注的是overlays,因为之后被替换的所有文件都来自于这里。
帮助文档在哪里?
在网上搜了半天,没有一丁点有用的东西,这时候就需要去查询官方文档资料,访问下面这个地址即可:
https://apereo.github.io/cas/5.3.x/
一般都从Properties的设置入手。
以上,就是简单的开篇,其实熟练查找官方文档,能够解决大部分问题。
如果有问题,欢迎指正讨论。

觉的不错?可以关注我的公众号↑↑↑
CAS5.3-启动运行 | 字痕随行
令我非常讨厌的冬天终于来了,不过好在这两天来了暖气,不至于冻得哆哆嗦嗦。
目前CAS定制化,在预计中的章节包括:
- 连接自定义数据库完成身份验证
- 增加图片验证码
- 使用Token认证
可能还包括一些杂七杂八的东西,另外还得介绍一下CAS和SpringBoot的集成。
本章继续介绍CAS5.3的定制化,上一篇和本篇都是非常基础的东西,如果不写就显得突兀,如果写又非常鸡肋。
上面都是凑字数的东西,下面才是简单不能再简单的正文。
按上一篇初始化项目之后,在IDEA中完成Tomcat配置:
然后直接运行,在浏览器中访问:
http://localhost:8080/
出现登录界面:
输入用户名:casuser,密码:Mellon,登录成功:
用户名和密码在配置文件application.properties中:
##
# CAS Authentication Credentials
#
cas.authn.accept.users=casuser::Mellon
接下来可以简单尝试一下overlay开发方式。新建src/main/resources,将上文中的application.properties拷贝至此文件夹,如下图所示:
更改上文中的配置值为:
##
# CAS Authentication Credentials
#
cas.authn.accept.users=casuser::123456
重新启动tomcat(使用Maven Clean和Package),使用新的账户和密码登录,即可登录成功。
以上,简单的介绍了一下启动和运行的过程,接下来就会介绍定制过程了。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
CAS5.3-自定义数据库完成身份验证 | 字痕随行
上周五打了第三针疫苗,要注意休息。
周六凑热闹看了LOL决赛,然后又看了尼公子,所以周日直接躺了。
只能今天更新了,直接上主题,如题所述,下方是正文。
像上一章中的配置,只是个测试的Demo而已,正常业务情况下,不可能只配置一个用户,用于身份验证。
本章就是要实现从数据库读取登录信息,并且进行身份验证,场景如下:
-
连接数据库的指定表。
-
指定用户名和密码字段。
-
密码通过MD5加密。
以上看着貌似挺麻烦,其实CAS Server本身已经将此场景实现,只需要通过更改配置文件实现即可。
首先,修改配置文件。
还是application.properties配置文件,先注释掉之前的用户配置:
##
# CAS Authentication Credentials
#
#cas.authn.accept.users=casuser::Mellon
然后增加以下配置:
# 开启JDBC认证
cas.authn.jdbc.query[0].sql=SELECT * FROM `你的账户表名` WHERE loginname =?
cas.authn.jdbc.query[0].fieldPassword=你的密码字段
cas.authn.jdbc.query[0].url=jdbc:mysql://127.0.0.1:3306/你的库?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false
cas.authn.jdbc.query[0].dialect=org.hibernate.dialect.MySQLDialect
cas.authn.jdbc.query[0].user=root
cas.authn.jdbc.query[0].password=root
cas.authn.jdbc.query[0].driverClass=com.mysql.jdbc.Driver
# 密码加密方式
cas.authn.jdbc.query[0].passwordEncoder.type=com.你的.MD5PwdEncoder
cas.authn.jdbc.query[0].passwordEncoder.characterEncoding=UTF-8
cas.authn.jdbc.query[0].passwordEncoder.encodingAlgorithm=MD5
然后,需要一个加密类。
如下自定义即可:
public class MD5PwdEncoder implements PasswordEncoder {
private final Logger logger = LoggerFactory.getLogger(MD5PwdEncoder.class);
private static final String[] HEX_DIGITS = {"0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"a", "b", "c", "d", "e", "f"};
@Override
public String encode(CharSequence charSequence) {
try {
MessageDigest md = MessageDigest.getInstance("MD5");
String pwd = byteArrayToHexString(md.digest(charSequence.toString().getBytes(StandardCharsets.UTF_8)));
logger.info("encode方法:加密前( {} ),加密后( {} )", charSequence, pwd);
return pwd.toUpperCase();
} catch (NoSuchAlgorithmException e) {
logger.error("对密码进行md5加密异常", e);
return null;
}
}
@Override
public boolean matches(CharSequence charSequence, String s) {
// 判断密码为空,直接返回false
if (StringUtils.isBlank(charSequence)) {
return false;
}
//调用上面的encode 对请求密码进行MD5处理
String pass = this.encode(charSequence.toString());
logger.info("matches方法:请求密码为:{} ,数据库密码为:{},加密后的请求密码为:{}", charSequence, s, pass);
//比较密码是否相等
return pass.equals(s);
}
private static String byteArrayToHexString(byte b[]) {
StringBuilder resultSb = new StringBuilder();
for (byte aB : b) {
resultSb.append(byteToHexString(aB));
}
return resultSb.toString();
}
private static String byteToHexString(byte b) {
int n = b;
if (n < 0) {
n += 256;
}
int d1 = n / 16;
int d2 = n % 16;
return HEX_DIGITS[d1] + HEX_DIGITS[d2];
}
}
要注意的是,一定要继承自PasswordEncoder,这个接口是CAS中的。
最后,增加pom引用。
因为使用数据库验证,还需要JDBC的支持,所以在pom文件中增加以下引用:
<profile>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<id>default</id>
<dependencies>
<dependency>
<groupId>org.apereo.cas</groupId>
<artifactId>cas-server-webapp${app.server}</artifactId>
<version>${cas.version}</version>
<type>war</type>
<scope>runtime</scope>
</dependency>
<!--
...Additional dependencies may be placed here...
-->
<dependency>
<groupId>org.apereo.cas</groupId>
<artifactId>cas-server-support-jdbc</artifactId>
<version>${cas.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.36</version>
</dependency>
</dependencies>
</profile>
修改后的工程结构如下:
重新使用Maven Clean和Package命令后,启动tomcat,使用数据库中的用户名和密码登录:
以上,就是本次内容,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
CAS5.3-自定义Handler实现验证码 | 字痕随行
上一篇所述的方式只是简单的解决了日常登录的需求,但是在为了安全的情况下,一般在登录的时候都会有图片验证码、二次身份认证等要求。
本章介绍一下,如何在登录时增加图片验证码。
CAS提供了一系列验证处理器,并且可以通过配置文件配置验证策略。
但是在看了一遍官方文档关于配置文件的说明并且进行了数次尝试之后,我只能选择了如下配置:
# cas.authn.policy.req.tryAll=false
# cas.authn.policy.req.handlerName=handlerName
# cas.authn.policy.req.enabled=true
官方文档的英文说明是:
Satisfied ifand only if a specified handler successfully authenticates its credential.
机翻一下就是:
仅当指定的处理程序成功验证其凭据时满足。
也就是说自定义一个Handler,然后登录时CAS就只会使用这一个Handler进行验证处理,验证成功了就通过验证,验证失败了就拒绝登录。
这里还有一个问题,网上搜索的大量文章在通过SQL认证的时候,把原始的SQL语句放到了这个Handler里面,而抛弃了配置文件中的配置,我个人觉的这种方式并不是最佳的方案,欠缺灵活,又打破了原有规则。
找了一下现有的Handler之后,最终发现QueryDatabaseAuthenticationHandler是最符合需求的,自定义一个类继承自QueryDatabaseAuthenticationHandler,然后复写验证逻辑即可。
自定义Handler:
public class UsernamePasswordCaptchaAuthenticationHandler extends QueryDatabaseAuthenticationHandler {
public UsernamePasswordCaptchaAuthenticationHandler(String name, ServicesManager servicesManager, PrincipalFactory principalFactory, Integer order, DataSource dataSource, String sql, String fieldPassword, String fieldExpired, String fieldDisabled, Map<String, Object> attributes) {
super(name, servicesManager, principalFactory, order, dataSource, sql, fieldPassword, fieldExpired, fieldDisabled, attributes);
}
@Override
public boolean supports(Credential credential) {
//判断传递过来的Credential 是否是自己能处理的类型
return credential instanceof UsernamePasswordCaptchaCredential;
}
@Override
protected AuthenticationHandlerExecutionResult doAuthentication(Credential credential) throws GeneralSecurityException, PreventedException {
UsernamePasswordCaptchaCredential thisCredential = (UsernamePasswordCaptchaCredential) credential;
//从Session中读取验证码
String vcode;
try {
HttpSession httpSession = ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()).getRequest().getSession();
Object object = httpSession.getAttribute(ContextConstant.VALIDAT_CODE_KEY);
httpSession.removeAttribute(ContextConstant.VALIDAT_CODE_KEY);
vcode = null == object ? null : object.toString();
} catch (Exception e) {
throw new FailedLoginException("无法获取验证码");
}
//比对验证码
if (StrUtil.isNotBlank(thisCredential.getCaptcha())
&& thisCredential.getCaptcha().equals(vcode)) {
super.doAuthentication(credential);
return createHandlerResult(
thisCredential,
principalFactory.createPrincipal(thisCredential.getUsername(), new HashMap<>()),
new ArrayList<>()
);
}
throw new FailedLoginException("验证码错误");
}
}
自定义Credential,可以接收验证码:
public class UsernamePasswordCaptchaCredential extends RememberMeUsernamePasswordCredential {
private static final long serialVersionUID = -2362388928807415990L;
/**
* 验证码
*/
private String captcha;
public String getCaptcha() {
return captcha;
}
public void setCaptcha(String captcha) {
this.captcha = captcha;
}
@Override
public int hashCode() {
return new HashCodeBuilder()
.appendSuper(super.hashCode())
.append(this.captcha)
.toHashCode();
}
}
页面需要增加验证码,并且能够回传,CAS是基于WebFlow实现的,直接在\templates\fragments\loginform.html中增加:
<section class="form-group">
<label for="captcha">验证码</label>
<div>
<input class="form-control required"
type="text"
id="captcha"
size="10"
tabindex="3"
th:field="*{captcha}"
autocomplete="off"/>
<img th:src="@{/captch/vcode}" id="captcha_img" onclick="javascript:refreshCaptcha()" />
<script type="text/javascript">
function refreshCaptcha(){
var requestPath = [[@{/}]];
$("#captcha_img").attr("src", requestPath + "/captch/vcode?id=" + Math.floor(Math.random()*24));
}
</script>
</div>
</section>
再在\webflow\login\login-webflow.xml中增加:
<view-state id="viewLoginForm" view="casLoginView" model="credential">
<binder>
<binding property="username" required="true"/>
<binding property="password" required="true"/>
<binding property="captcha" required="false"/>
</binder>
<transition on="submit" bind="true" validate="true" to="realSubmit" history="invalidate"/>
</view-state>
上面的html和xml文件需要串联起来并且生效,需要使用自定义配置替换原有配置:
public class UsernamePasswordCaptchaWebflowConfigurer extends DefaultLoginWebflowConfigurer {
public UsernamePasswordCaptchaWebflowConfigurer(FlowBuilderServices flowBuilderServices, FlowDefinitionRegistry flowDefinitionRegistry, ApplicationContext applicationContext, CasConfigurationProperties casProperties) {
super(flowBuilderServices, flowDefinitionRegistry, applicationContext, casProperties);
}
@Override
protected void createRememberMeAuthnWebflowConfig(final Flow flow) {
//使用自定义的身份凭证替换原有webflow中的配置
super.createFlowVariable(flow, CasWebflowConstants.VAR_ID_CREDENTIAL, UsernamePasswordCaptchaCredential.class);
}
}
然后还需要一个Controller,提供验证码图片,这个Controller就比较随意了,只要能提供图片就可以。
最后,还需要将上面新增的类全都串联起来,这里新增两个配置类,一个用来使自定义的Webflow配置生效:
@Configuration
public class CustomAuthenticationConfig {
@Resource
private FlowBuilderServices flowBuilderServices;
@Resource
private FlowDefinitionRegistry loginFlowRegistry;
@Resource
private ApplicationContext applicationContext;
@Resource
private CasConfigurationProperties casProperties;
@Bean
public CaptchaController getCaptchaController() {
return new CaptchaController();
}
@Bean
@Order(1)
public CasWebflowConfigurer defaultWebflowConfigurer() {
return new UsernamePasswordCaptchaWebflowConfigurer(
flowBuilderServices,
loginFlowRegistry,
applicationContext,
casProperties
);
}
}
一个用来使验证的Handler生效:
@Configuration
public class UsernamePasswordCaptchaConfig implements AuthenticationEventExecutionPlanConfigurer {
@Resource
private ServicesManager servicesManager;
@Resource
private CasConfigurationProperties casProperties;
@Resource
private PrincipalFactory jdbcPrincipalFactory;
@Autowired(required = false)
@Qualifier("queryPasswordPolicyConfiguration")
private PasswordPolicyConfiguration queryPasswordPolicyConfiguration;
/**
* 声明自定义的身份认证处理器
*/
@Bean("usernamePasswordCaptchaAuthenticationHandler")
public AuthenticationHandler usernamePasswordCaptchaAuthenticationHandler() {
CustomQueryJdbcAuthenticationProperties b = new CustomQueryJdbcAuthenticationProperties(casProperties);
final Multimap<String, Object> attributes = CoreAuthenticationUtils.transformPrincipalAttributesListIntoMultiMap(b.getPrincipalAttributeList());
final UsernamePasswordCaptchaAuthenticationHandler h = new UsernamePasswordCaptchaAuthenticationHandler(
b.getName(), servicesManager,
jdbcPrincipalFactory, b.getOrder(),
JpaBeans.newDataSource(b), b.getSql(), b.getFieldPassword(),
b.getFieldExpired(), b.getFieldDisabled(), CollectionUtils.wrap(attributes));
h.setPasswordEncoder(PasswordEncoderUtils.newPasswordEncoder(b.getPasswordEncoder()));
h.setPrincipalNameTransformer(PrincipalNameTransformerUtils.newPrincipalNameTransformer(b.getPrincipalTransformation()));
if (queryPasswordPolicyConfiguration != null) {
h.setPasswordPolicyConfiguration(queryPasswordPolicyConfiguration);
}
h.setPrincipalNameTransformer(PrincipalNameTransformerUtils.newPrincipalNameTransformer(b.getPrincipalTransformation()));
if (StringUtils.isNotBlank(b.getCredentialCriteria())) {
h.setCredentialSelectionPredicate(CoreAuthenticationUtils.newCredentialSelectionPredicate(b.getCredentialCriteria()));
}
return h;
}
@Override
public void configureAuthenticationExecutionPlan(AuthenticationEventExecutionPlan plan) {
plan.registerAuthenticationHandler(usernamePasswordCaptchaAuthenticationHandler());
}
/**
* 自定义JDBC查询配置
*/
static class CustomQueryJdbcAuthenticationProperties extends QueryJdbcAuthenticationProperties {
private static final long serialVersionUID = 4872638722398158210L;
private final CasConfigurationProperties casConfigurationProperties;
public CustomQueryJdbcAuthenticationProperties(CasConfigurationProperties casConfigurationProperties) {
this.casConfigurationProperties = casConfigurationProperties;
}
@Override
public String getSql() {
return casConfigurationProperties.getCustom().getProperties().getOrDefault(
"sql",
"SELECT * FROM account WHERE loginname =?"
);
}
@Override
public String getFieldPassword() {
return casConfigurationProperties.getCustom().getProperties().getOrDefault(
"fieldPassword",
"loginpwd"
);
}
@Override
public String getUrl() {
return casConfigurationProperties.getCustom().getProperties().getOrDefault(
"url",
"jdbc:mysql://localhost:3306/user?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false"
);
}
@Override
public String getDialect() {
return casConfigurationProperties.getCustom().getProperties().getOrDefault(
"dialect",
"org.hibernate.dialect.MySQLDialect"
);
}
@Override
public String getUser() {
return casConfigurationProperties.getCustom().getProperties().getOrDefault(
"user",
"root"
);
}
@Override
public String getPassword() {
return casConfigurationProperties.getCustom().getProperties().getOrDefault(
"password",
"root"
);
}
@Override
public String getDriverClass() {
return casConfigurationProperties.getCustom().getProperties().getOrDefault(
"driverClass",
"com.mysql.jdbc.Driver"
);
}
@Override
public PasswordEncoderProperties getPasswordEncoder() {
return new CustomPasswordEncoderProperties(casConfigurationProperties);
}
}
/**
* 自定义密码加密配置
*/
static class CustomPasswordEncoderProperties extends PasswordEncoderProperties {
private static final long serialVersionUID = -4675488743635765725L;
private final CasConfigurationProperties casConfigurationProperties;
public CustomPasswordEncoderProperties(CasConfigurationProperties casConfigurationProperties) {
this.casConfigurationProperties = casConfigurationProperties;
}
@Override
public String getEncodingAlgorithm() {
return casConfigurationProperties.getCustom().getProperties().getOrDefault(
"passwordEncoderEncodingAlgorithm",
"MD5"
);
}
@Override
public String getType() {
return casConfigurationProperties.getCustom().getProperties().getOrDefault(
"passwordEncoderType",
"com.blackzs.encoder.MD5PwdEncoder"
);
}
@Override
public String getCharacterEncoding() {
return casConfigurationProperties.getCustom().getProperties().getOrDefault(
"passwordEncoderCharacterEncoding",
"UTF-8"
);
}
}
}
在spring.factories中增加这两个配置类后,启动程序:
注意的是,pom文件需要添加以下引用:
<dependency>
<groupId>org.apereo.cas</groupId>
<artifactId>cas-server-core-webflow</artifactId>
<version>${cas.version}</version>
</dependency>
<dependency>
<groupId>org.apereo.cas</groupId>
<artifactId>cas-server-core-webflow-api</artifactId>
<version>${cas.version}</version>
</dependency>
<dependency>
<groupId>org.apereo.cas</groupId>
<artifactId>cas-server-core-util-api</artifactId>
<version>${cas.version}</version>
</dependency>
工程的结构如下图:
以上,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
CAS5.3-基于JWT认证 | 字痕随行
周末吃了个非常好吃的自助--温野菜,强烈推荐。
基于上一章,本章将介绍CAS Server如何基于JwtToken,进行身份验证。
首先需要了解一下CAS Server如何开启JWT Token认证支持,可以参考官方指南:
https://apereo.github.io/cas/5.3.x/installation/JWT-Authentication.html
其实,比较简单,大概的步骤如下:
-
引入Jar包,开启支持。
-
设置CAS Properties。
-
在服务注册表中配置服务。
-
在之前自定义的Handler中实现自定义认证逻辑。
基于之前的代码,在pom.xml文件中增加:
<dependency>
<groupId>org.apereo.cas</groupId>
<artifactId>cas-server-support-token-core</artifactId>
<version>${cas.version}</version>
</dependency>
<dependency>
<groupId>org.apereo.cas</groupId>
<artifactId>cas-server-support-token-webflow</artifactId>
<version>${cas.version}</version>
</dependency>
在application.properties文件中增加:
# JWT认证
cas.authn.token.name=token
cas.authn.token.crypto.encryptionEnabled=true
cas.authn.token.crypto.signingEnabled=true
新注册服务,在resources/service中新增文件Jwt-0000001.json:
{
"@class" : "org.apereo.cas.services.RegexRegisteredService",
"serviceId" : "^(https|http|imaps)://.*",
"name" : "JwtService",
"id" : 1,
"properties" : {
"@class" : "java.util.HashMap",
"jwtSigningSecret" : {
"@class" : "org.apereo.cas.services.DefaultRegisteredServiceProperty",
"values" : [ "java.util.HashSet", [ "12345678901234567890123456789012345678901" ] ]
},
"jwtSigningSecretAlg" : {
"@class" : "org.apereo.cas.services.DefaultRegisteredServiceProperty",
"values" : [ "java.util.HashSet", [ "HS256" ] ]
}
}
}
改造一下之前的UsernamePasswordCaptchaAuthenticationHandler,代码如下:
public class UsernamePasswordCaptchaAuthenticationHandler extends QueryDatabaseAuthenticationHandler {
private final String sql;
public UsernamePasswordCaptchaAuthenticationHandler(String name, ServicesManager servicesManager, PrincipalFactory principalFactory, Integer order, DataSource dataSource, String sql, String fieldPassword, String fieldExpired, String fieldDisabled, Map<String, Object> attributes) {
super(name, servicesManager, principalFactory, order, dataSource, sql, fieldPassword, fieldExpired, fieldDisabled, attributes);
this.sql = sql;
}
@Override
public boolean supports(Credential credential) {
//判断传递过来的Credential 是否是自己能处理的类型
return credential instanceof UsernamePasswordCredential || credential instanceof TokenCredential;
}
@Override
protected AuthenticationHandlerExecutionResult doAuthentication(Credential credential) throws GeneralSecurityException, PreventedException {
if (credential instanceof UsernamePasswordCaptchaCredential) {
return doLoginRequestAuthentication(credential);
} else if (credential instanceof TokenCredential) {
return doTokenAuthentication(credential);
}
throw new FailedLoginException("没有匹配的Handler");
}
private AuthenticationHandlerExecutionResult doLoginRequestAuthentication(Credential credential) throws GeneralSecurityException, PreventedException {
UsernamePasswordCaptchaCredential thisCredential = (UsernamePasswordCaptchaCredential) credential;
//从Session中读取验证码
String vcode;
try {
HttpSession httpSession = ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()).getRequest().getSession();
Object object = httpSession.getAttribute(ContextConstant.VALIDAT_CODE_KEY);
httpSession.removeAttribute(ContextConstant.VALIDAT_CODE_KEY);
vcode = null == object ? null : object.toString();
} catch (Exception e) {
throw new FailedLoginException("无法获取验证码");
}
//比对验证码
if (StrUtil.isNotBlank(thisCredential.getCaptcha())
&& thisCredential.getCaptcha().equals(vcode)) {
super.doAuthentication(credential);
return createHandlerResult(
thisCredential,
principalFactory.createPrincipal(thisCredential.getUsername(), new HashMap<>()),
new ArrayList<>()
);
}
throw new FailedLoginException("验证码错误");
}
private AuthenticationHandlerExecutionResult doTokenAuthentication(Credential credential) throws FailedLoginException {
TokenCredential tokenCredential = (TokenCredential) credential;
Map<String, Object> dbFields = this.getJdbcTemplate().queryForMap(this.sql, tokenCredential.getId());
if (MapUtil.isNotEmpty(dbFields)) {
return createHandlerResult(
tokenCredential,
principalFactory.createPrincipal(tokenCredential.getId(), new HashMap<>()),
new ArrayList<>()
);
}
throw new FailedLoginException("用户验证错误");
}
}
通过Postman请求如下地址:
POST /login?service=http://localhost:8081/&token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiIyMDE4MTQzMiIsImlzcyI6ImNlcyJ9.-43ymRRDLKHtm5TJehVXK4kMCMgtn6IVBUSiS7HNAsA
HTTP/1.1
Host: localhost:8080
会获得请求中service的ST凭据。
至于JWT的相关知识,还需要自行了解,或者后面单独开一章介绍一下。
以上,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
CAS5.3-Restful方式认证 | 字痕随行
这篇应该是CAS系列的最后一篇了,就这么晃荡晃荡,就快过年了。
CAS高版本都支持使用Restful方式进行认证,主要是通过其开放的3个接口实现的。
第一个,获取TGT。
TGT,可以理解为一个存活时间稍长的身份凭证,这个凭证有两个有效期配置:
# Set to a negative value to never expire tickets
# cas.ticket.tgt.maxTimeToLiveInSeconds=28800
# cas.ticket.tgt.timeToKillInSeconds=7200
很多文章都说,如果7200秒没有移动过鼠标,这个凭证就会过期。
但是,一个B/S系统,这Server端是怎么监控Client端的?
所以,我觉得,可能是如果7200秒内没有任何请求就会过期。
28800是最大存续时间,意思就是不管如何,这个时间之后,TGT就会失效。
获取TGT的代码如下:
public String getTgt(String loginName, String loginPwd) {
String tgtUrl = "https://ip:port/cas/v1/tickets";
//使用hutool实现
HttpResponse httpResponse = HttpRequest
.post(tgtUrl)
.contentType("application/x-www-form-urlencoded;charset=UTF-8")
.header(Header.ACCEPT, "application/json;charset=UTF-8")
.form(new HashMap<String, Object>() {
private static final long serialVersionUID = -138163390499485640L;
{
put("username", loginName);
put("password", loginPwd);
}
})
.execute();
return httpResponse.body();
}
第二个,获取GT。
GT,使用TGT换取的一次性票据,它和Service是绑定的。
所谓的Service其实就是需要验证的完整Url,比如上一篇的/sso/test。
默认配置下,GT获取以后,需要在10秒内进行认证,并且只能使用一次。
获取GT的代码如下:
public String getGt(String tgt, String service) {
String stUrl = "https://ip:port/cas/v1/tickets/" + tgt;
HttpResponse httpResponse = HttpRequest
.post(stUrl)
.contentType("application/x-www-form-urlencoded;charset=UTF-8")
.header(Header.ACCEPT, "application/json;charset=UTF-8")
.form(new HashMap<String, Object>() {
private static final long serialVersionUID = -6472219360813373597L;
{
put("service", service);
}
})
.execute();
return httpResponse.body();
}
第三个,验证GT。
获取GT之后,就可以在目标系统上进行验证了,通过验证之后,就可以获得用户的身份信息了。
代码如下:
public String getValidate(String ticket, String service) {
String validateUrl = "https://ip:port/cas/p3/serviceValidate";
HttpResponse httpResponse = HttpRequest
.get(validateUrl)
.form(new HashMap<String, Object>() {
private static final long serialVersionUID = -7333706958754801580L;
{
put("service", service);
put("ticket", ticket);
}
})
.header(Header.ACCEPT, "application/json;charset=UTF-8")
.execute();
return httpResponse.body();
}
该接口返回的cas:user中的内容,就是登录账号。
如果目标系统已经按照上一篇完成了CAS的配置,其实可以直接在拦截的Url后面加上ticket参数,比如:
http://localhost/sso/test?ticket=获得的gt
如果Url和GT匹配,会自动通过验证的,有兴趣的同学可以自行尝试。
好了,以上,如果有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
CAS5.3-Springboot集成客户端验证 | 字痕随行
距离今年结束还有半个月,距离春节还有一个半月,年底还有项目要上线,不知道还能更新几篇。
前面几篇说了说如何构建定制化的CAS Server,这篇开始说一说WEB项目如何使用CAS进行身份验证。
SpringMVC项目不打算单独开篇了,毕竟CAS就不是个新玩意,再搞个老古董,都2022年了,一点意义都没有。
SpringBoot集成的话,就几个关键步骤:
- 引入Jar包。
- yml中增加配置。
- 增加Filter过滤器。
- 增加Configuration配置。
首先,在pom文件中引入配置:
然后,在yml中增加配置项:
cas:
server-url-prefix: http://localhost:8443/cas
server-login-url: http://localhost:8443/cas/login
client-host-url: http://localhost:8080/
validation-type: CAS
再然后,增加Filter过滤器:
public class CasContextFilter implements Filter {
public void init(FilterConfig filterConfig) throws ServletException {
}
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) servletRequest;
HttpSession session = req.getSession(false);
Assertion assertion = session != null ? (Assertion) session.getAttribute("_const_cas_assertion_") : null;
if (null != session) {
session.setAttribute("USER_ID_", assertion.getPrincipal().getName());
}
filterChain.doFilter(servletRequest, servletResponse);
}
public void destroy() {
}
}
配置Filter,使其生效:
@Bean
public FilterRegistrationBean casContextFilter() {
FilterRegistrationBean<CasContextFilter> filterRegistrationBean = new FilterRegistrationBean<>();
filterRegistrationBean.setFilter(new CasContextFilter());
filterRegistrationBean.setEnabled(true);
//拦截的路径,一般通过这个路径来做跳转处理
filterRegistrationBean.addUrlPatterns("/sso/*");
filterRegistrationBean.setOrder(2);
return filterRegistrationBean;
}
这个过滤器其实是为了认证完毕后,将CAS提供的认证信息写入到Session中。
最关键的其实就是这句:
Assertion assertion = session != null ? (Assertion) session.getAttribute("_const_cas_assertion_") : null;
最后,使用CAS的认证过滤器拦截单点登录的地址:
@Value("${cas.server-url-prefix}")
private String serverUrlPrefix;
@Value("${cas.client-host-url}")
private String clientHostUrl;
@Override
public void configureAuthenticationFilter(FilterRegistrationBean authenticationFilter) {
authenticationFilter.setFilter(new AuthenticationFilter());
authenticationFilter.addUrlPatterns("/sso/*");
authenticationFilter.addInitParameter("casServerLoginUrl", serverUrlPrefix);
authenticationFilter.addInitParameter("serverName", clientHostUrl);
authenticationFilter.setOrder(1);
}
一定要注意两个Filter的顺序,它们的功用是完全不同的。
做一个/sso/test来测试一下:
@RestController
@RequestMapping("/sso")
public class SSOController {
@GetMapping("test")
public String getTest(HttpServletRequest request) {
return "this is a test," + request.getSession().getAttribute("USER_ID_");
}
}
当然需要启动之前自定义的CAS Server,输入:
http://localhost/sso/test
就会自动跳转到:
http://localhost:8443/cas/login
登录成功后,会自动跳回/sso/test,并且打印出:
this is a test,用户名
觉的不错?可以关注我的公众号↑↑↑
CAS5.3-自定义通过JWT获取TGT | 字痕随行
这天气突然就热了起来,终于要进入我最喜欢的季节了。
上一篇CAS5.3-Restful方式认证,必须使用用户名和密码才能获取TGT。
翻了翻它的Rest Support,发现使用cas-server-support-rest-tokens,也仅仅是用JWT替代TGT而已。
也就是说,还是必须使用用户名和密码,只不过获得的TGT变成了JWT,然后拿着JWT去获取ST。
本篇尝试通过自定义的方式,实现以下需求:
- 通过JWT获得TGT,不再需要用户名和密码。
- JWT的秘钥位于CAS5.3-基于JWT认证中的Serivce配置文件中。
- 获得的TGT在CAS Server中有效,可以通过其获取的ST实现其它系统的单点登录。
这里需要参考CAS Server的几段源码,需要下载Cas Server的源工程。
第一段代码
参考它如何通过用户名和密码获得TGT的,需要从
org.apereo.cas.support.rest.resources.TicketGrantingTicketResource
这个类入手。
一路跟踪下去,会发现这样的代码:
protected TicketGrantingTicket createTicketGrantingTicketForRequest(final MultiValueMap<String, String> requestBody,
final HttpServletRequest request,
final HttpServletResponse response) throws Exception {
//主要得看这地方,怎么得到的authenticationResult,如何仿造
val authenticationResult = authenticationService.authenticate(requestBody, request, response);
val result = authenticationResult.orElseThrow(FailedLoginException::new);
return centralAuthenticationService.createTicketGrantingTicket(result);
}
找一下AuthenticationResult的实现类,发现DefaultAuthenticationResult,进而发现依赖于Authentication。
最终组装的这段代码如下:
Principal principal = PrincipalFactoryUtils.newPrincipalFactory().createPrincipal(authenticate.getPrincipal().getId(), new HashMap<>(0));
CredentialMetaData meta = new BasicCredentialMetaData();
Authentication authentication = new DefaultAuthenticationBuilder(principal)
.addCredential(meta)
.addSuccess("tokenTgtHandler", new DefaultAuthenticationHandlerExecutionResult(usernamePasswordCaptchaAuthenticationHandler, meta))
.setAttributes(new HashMap<>(0))
.build();
AuthenticationResult authenticationResult = new DefaultAuthenticationResult(authentication, null);
TicketGrantingTicket ticketGrantingTicket = centralAuthenticationService.createTicketGrantingTicket(authenticationResult);
这里就引出**第二段参考代码,**怎么获得当前的人员标识。
当前的人员肯定在JWT里面,但是怎么解析JWT呢?
直接可以参考login是怎么通过JWT认证的,可以断点跟踪一下,最终的代码如下:
Credential credential = new TokenCredential(token, serviceInstance);
AuthenticationHandlerExecutionResult authenticate;
authenticate = authenticationHandler.authenticate(credential)
最后
新建一个Controller,然后创建一个方法,把上面的代码复制过去,调整一下,就可以尝试了。
http://localhost/getTgt?token=JWT&service=http://localhost
通过返回的ticketGrantingTicket.getId(),就可以获取ST了。
以上,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
CAS5.3-登录验证的过程 | 字痕随行
之前就已经介绍过,CAS Server是通过Spring Web Flow来处理请求的。
在本篇文章中,不会具体介绍Spring Web Flow的使用方式,基本概念的话需要各位自行了解,只会在必须说明的时候会带出来一些介绍。
我很好奇的是,如果我在地址栏输入:
http://localhost:8080/cas/login
如果没有登录过,浏览器内会显示登录页面,如果已经登录过,浏览器会显示登录成功页面。
为什么同一个地址会显示两个页面,而这背后的处理过程是什么呢?
首先,我建议把CAS的源代码下载下来,这样便于跟踪阅读,当然编辑器的加载过程十分漫长,而且有可能会失败,甚至会内存溢出,做好心理准备。
然后,在cas-server.core.cas-server-core-webflow-api中找到类
DefaultLoginWebflowConfigurer
至于为什么一上来就能找到这个类,那肯定是经过了无数次的反推分析的,这个过程我懒得记录了。
这个类就是Webflow的配置入口,从下面这段代码就可以看到Webflow的配置了:
@Override
protected void doInitialize() {
final Flow flow = getLoginFlow();
if (flow != null) {
createInitialFlowActions(flow);
createDefaultGlobalExceptionHandlers(flow);
//这里是结束的状态,包含了登录成功的页面
createDefaultEndStates(flow);
createDefaultDecisionStates(flow);
createDefaultActionStates(flow);
createDefaultViewStates(flow);
createRememberMeAuthnWebflowConfig(flow);
//这就是一切的开始,找到这个就找到了线头
setStartState(flow, CasWebflowConstants.STATE_ID_INITIAL_AUTHN_REQUEST_VALIDATION_CHECK);
}
}
这里面有一个知识点明白了可能就容易点。把Webflow想想成状态机,一个状态流转到另外一个状态,每个状态有一个处理的Action,Action返回的结果决定了目标状态。
了解了上面的知识点,就可以找到初始状态对应的Action:
public class InitialAuthenticationRequestValidationAction extends AbstractAction {}
追一追doExecute(),就可以找到下面这段代码:
@Override
public Set<Event> resolveInternal(final RequestContext context) {
final String tgt = WebUtils.getTicketGrantingTicketId(context);
final RegisteredService service = WebUtils.getRegisteredService(context);
//service在本文讨论的场景下永远为空
if (service == null) {
LOGGER.debug("No service is available to determine event for principal");
//这方法永远返回Success
return resumeFlow();
}
}
返回Success代表什么呢?代表刚才提到的知识点,看看结果是Success的时候,要到哪个状态去。
这直接看看代码,流转到:
CasWebflowConstants.STATE_ID_TICKET_GRANTING_TICKET_CHECK
然后去看TicketGrantingTicketCheckAction的doExecute()方法:
@Override
public Event doExecute(final RequestContext requestContext) {
//获取cookie里面的tgt
final String tgtId = WebUtils.getTicketGrantingTicketId(requestContext);
if (StringUtils.isBlank(tgtId)) {
//没有到这个状态去
return new Event(this, CasWebflowConstants.TRANSITION_ID_TGT_NOT_EXISTS);
}
try {
final Ticket ticket = this.centralAuthenticationService.getTicket(tgtId, Ticket.class);
if (ticket != null && !ticket.isExpired()) {
//有就到这个状态去
return new Event(this, CasWebflowConstants.TRANSITION_ID_TGT_VALID);
}
} catch (final AbstractTicketException e) {
LOGGER.trace("Could not retrieve ticket id [{}] from registry.", e.getMessage());
}
//最终到这个状态去
return new Event(this, CasWebflowConstants.TRANSITION_ID_TGT_INVALID);
}
好了,老一套循环了,其实这就分开了,不同的状态跳转到不同的处理,返回不同的页面。
如果继续向下追到底的话,就是开篇问题的答案了。
以上,如有错误,欢迎指正。
觉的不错?可以关注我的公众号↑↑↑
CAS5.3-支持OAuth2.0 | 字痕随行
CAS现在的版本已经是6.6.x了,它的在线文档也没有5.3.x版本的了,如果还想看官方文档的话,只能去它的开源仓库拉取下来,在项目中有个docs文件夹,这里面可以看到它在这个版本的文档。
现在,言归正传,简单说一下CAS5.3版本如何支持OAuth2.0验证。
第一步,打开官方文档。
官方文档说的很清楚,但是也说的不清楚。
在阅读官方文档之前,非常建议了解一下OAuth2.0协议,哪怕是百度找一篇速成一下,也会让你接下来的工作事半功倍。
官方文档的相对地址是:
\docs\cas-server-documentation\installation\OAuth-OpenId-Authentication.md
提炼总结一下,它大概分了四个部分:
- 引入Maven的坐标文件,支撑该功能实现。
- 说明OAuth2.0所要求的的请求路径,并且详述每种授权许可所需的参数要求。
- 如何注册客户端,即Service的Json配置文件。
- 返回的Profile Json结构,以及如何自定义返回。
第二步,引入Maven的坐标地址。
在pom.xml文件中增加以下配置即可:
<dependency>
<groupId>org.apereo.cas</groupId>
<artifactId>cas-server-support-oauth-webflow</artifactId>
<version>${cas.version}</version>
</dependency>
第三步,增加Service的Json配置文件。
官方文档中的Register Clients中已经给出了文件结构,并且说明了其中配置项的意义:
{
"@class" : "org.apereo.cas.support.oauth.services.OAuthRegisteredService",
"clientId": "clientid",
"clientSecret": "clientSecret",
"serviceId" : "^(https|imaps)://<redirect-uri>.*",
"name" : "OAuthService",
"id" : 100,
"supportedGrantTypes": [ "java.util.HashSet", [ "...", "..." ] ],
"supportedResponseTypes": [ "java.util.HashSet", [ "...", "..." ] ]
}
但是以上还不够,所以这里有一些细节额外注意一下:
- Service配置文件的名称必须是name+"-"+id。
- serviceId的值是个正则表达式,在验证传入的redirect_uri是否合法时会用到。所以上面的配置示例才会是“
.*”,这 其实是client的域名。 - 有一些配置没列在这里,比如:
- bypassApprovalPrompt:是否显示资源确认授权那个页面,如果配置成true,验证成功后就会直接跳转到redirect_uri。不配置或者配置成false,会有一个确认页面等着用户手动点一下。
- jsonFormat:不配置或者配置成false,返回的是个字符串。如果配置成true,会返回成Json格式。
第四步,增加配置。
在properties增加以下配置:
#OAuth2.0
cas.authn.oauth.refreshToken.timeToKillInSeconds=2592000
cas.authn.oauth.code.timeToKillInSeconds=30
cas.authn.oauth.code.numberOfUses=1
cas.authn.oauth.accessToken.releaseProtocolAttributes=true
cas.authn.oauth.accessToken.timeToKillInSeconds=7200
cas.authn.oauth.accessToken.maxTimeToLiveInSeconds=28800
#决定了profile返回内容的格式,NESTED、FLAT、CUSTOM
cas.authn.oauth.userProfileViewType=NESTED
#让CAS知道自己的地址是什么,以便跳转识别
cas.server.name=http://localhost:8080
cas.server.prefix=http://localhost:8080/cas
第五步,测试一下。
使用Authorization Code模式,先访问以下地址:
/oauth2.0/authorize?response_type=code&client_id=<ID>&redirect_uri=<CALLBACK>
GET
如果在CAS没登录过,会直接先跳到登录界面,验证成功后,会跳转回
<CALLBACK>?code=CODE
302重定向
获得CODE后,使用post请求token的地址,可以获取到access token:
/oauth2.0/accessToken?grant_type=authorization_code&client_id=ID&client_secret=SECRET&code=CODE&redirect_uri=CALLBACK
POST
该地址会返回token,携带token访问以下地址可以获取profile:
/oauth2.0/profile?access_token=<TOKEN>
该地址会返回人员的JSON格式信息:
Nested配置时:
{
"id": "casuser",
"attributes": {
"email": "casuser@example.org",
"name": "CAS"
},
"something": "else"
}
FLAT配置时:
{
"id": "casuser",
"email": "casuser@example.org",
"name": "CAS",
"something": "else"
}
最后,自定义。
这个比较简单,按照官方文档增加一个配置类即可:
package org.apereo.cas.support.oauth;
@Configuration("MyOAuthConfiguration")
@EnableConfigurationProperties(CasConfigurationProperties.class)
public class MyOAuthConfiguration {
@Bean
@RefreshScope
public OAuth20UserProfileViewRenderer oauthUserProfileViewRenderer() {
...
}
}
只是需要注意的是,这个配置类是全局的,如果client有多个,需要的profile格式有所不同,那就需要在其内部按照acessToken所属的service进行判断,然后返回各自所需的信息。
觉的不错?可以关注我的公众号↑↑↑
CAS5.3-Nginx转发OAuth2.0请求导致验证失败的问题分析 | 字痕随行
先说说环境吧:
- CAS在Nginx后面,所有的请求经由Nginx转发。
- CAS开启了OAuth2.0模块
其它的都是正常配置了,但是当OAuth2.0请求验证时,总会跳转到一个内网地址,就很纳闷为什么。
最后,只能通过分析源码来寻找原因了。
通过浏览器的开发助手,我们知道卡住的位置在callbackAuthorize这个地址,它的302重定向会到一个内网地址,响应头如下:
cache-control: no-cache, no-store, max-age=0, must-revalidate
content-language: zh-CN
content-length: 0
date: Thu, 09 Mar 2023 05:41:13 GMT
expires: 0
location: http://192.168.1.1:39999/oauth2.0/authorize?client_id=cliendId&redirect_uri=callback地址&response_type=code&state=uuid
pragma: no-cache
server: nginx/1.x.x
x-content-type-options: nosniff
x-frame-options: DENY
x-xss-protection: 1; mode=block
按道理都有redirect地址,怎么都不会跳转到一个内网的地址,尤其只是域名更换了,后面的地址链接还都是正确的。
直接看callbackAuthorize这个地址的处理逻辑就好了,为什么会response这么一个location出来?下面是该controller的代码:
@GetMapping(path = OAuth20Constants.BASE_OAUTH20_URL + '/' + OAuth20Constants.CALLBACK_AUTHORIZE_URL)
public ModelAndView handleRequest(final HttpServletRequest request, final HttpServletResponse response) {
final J2EContext context = new J2EContext(request, response, this.oauthConfig.getSessionStore());
final DefaultCallbackLogic callback = new DefaultCallbackLogic();
//直接看这个方法,这方法决定了response的header
callback.perform(context, oauthConfig, J2ENopHttpActionAdapter.INSTANCE,
null, Boolean.TRUE, Boolean.FALSE,
Boolean.FALSE, Authenticators.CAS_OAUTH_CLIENT);
final String url = StringUtils.remove(response.getHeader("Location"), "redirect:");
final ProfileManager manager = Pac4jUtils.getPac4jProfileManager(request, response);
return oAuth20CallbackAuthorizeViewResolver.resolve(context, manager, url);
}
然后就是Pac4j的内部代码了:
protected HttpAction redirectToOriginallyRequestedUrl(final C context, final String defaultUrl) {
final String requestedUrl = (String) context.getSessionStore().get(context, Pac4jConstants.REQUESTED_URL);
String redirectUrl = defaultUrl;
if (isNotBlank(requestedUrl)) {
context.getSessionStore().set(context, Pac4jConstants.REQUESTED_URL, null);
redirectUrl = requestedUrl;
}
logger.debug("redirectUrl: {}", redirectUrl);
return HttpAction.redirect(context, redirectUrl);
}
注意上面代码中的requestedUrl,是从sessionStore里面取出的。那下一步就很明确了,这url是怎么存进去的。
找这个url的思路如下:
- 身份验证肯定有个验证的方法,所以这段验证逻辑在哪,会导致它要转到login路径。
- Pac4j是个登录验证的封装工具。
所以,就是想一想,就是要找登录验证的地方,就找到了下面这段代码:
@ConditionalOnMissingBean(name = "requiresAuthenticationAuthorizeInterceptor")
@Bean
public SecurityInterceptor requiresAuthenticationAuthorizeInterceptor() {
return new SecurityInterceptor(oauthSecConfig.getIfAvailable(), Authenticators.CAS_OAUTH_CLIENT);
}
继续找到preHandle,就会找到RequestUrl是怎么保存进来的:
protected void saveRequestedUrl(final C context, final List<Client> currentClients) {
if (ajaxRequestResolver == null || !ajaxRequestResolver.isAjax(context)) {
//就这里了,怎么获取RequestURL的
final String requestedUrl = context.getFullRequestURL();
logger.debug("requestedUrl: {}", requestedUrl);
context.getSessionStore().set(context, Pac4jConstants.REQUESTED_URL, requestedUrl);
}
}
然后,就看到了request.getRequestURL()。
当时我就给跪了,要是Nginx转发的,那不就是个内网地址,真实的地址都放到header了。
原始代码是真的不想改了,只能想想别的变通方法了,不行就把Nginx去了吧。
以上,如果有错误,欢迎探讨和指正。
觉的不错?可以关注我的公众号↑↑↑
CAS5.3-Token登录的验证过程 | 字痕随行
之前也写过登录验证的过程,这章专门来分析使用Token时登录的验证过程。
其实用两张图就大概能够说明整个过程了,下面是第一张图,验证过程触发点:
整个过程的配置类是:
TrustedAuthenticationWebflowConfigurer
关键的配置代码:
@Override
protected void doInitialize() {
final Flow flow = getLoginFlow();
if (flow != null) {
final EvaluateAction action = createEvaluateAction("remoteUserAuthenticationAction");
//省略代码若干
setStartState(flow, actionState);
}
}
其中remoteUserAuthenticationAction的配置代码是:
@ConditionalOnMissingBean(name = "remoteUserAuthenticationAction")
@Bean
public Action remoteUserAuthenticationAction() {
final ChainingPrincipalFromRequestNonInteractiveCredentialsAction chain =
new ChainingPrincipalFromRequestNonInteractiveCredentialsAction(initialAuthenticationAttemptWebflowEventResolver,
serviceTicketRequestWebflowEventResolver,
adaptiveAuthenticationPolicy,
trustedPrincipalFactory(),
remoteRequestPrincipalAttributesExtractor());
chain.addAction(principalFromRemoteUserAction());
chain.addAction(principalFromRemoteUserPrincipalAction());
chain.addAction(principalFromRemoteHeaderPrincipalAction());
return chain;
}
然后看第二张图就可以了:

其中authenticateInternal()是最关键方法,会循环调用注册过的验证方法:
protected AuthenticationBuilder authenticateInternal(final AuthenticationTransaction transaction) throws AuthenticationException {
//此处省略代码若干
try {
//此处省略代码若干
final Iterator<AuthenticationHandler> itHandlers = handlerSet.iterator();
boolean proceedWithNextHandler = true;
//开始循环验证,这里可能包含用户密码和Token两个验证
while (proceedWithNextHandler && itHandlers.hasNext()) {
final AuthenticationHandler handler = itHandlers.next();
//这里就是handler里面要设置凭证类型的意义所在
if (handler.supports(credential)) {
//省略验证过程代码
} else {
LOGGER.debug("Authentication handler [{}] does not support the credential type [{}]. Trying next...", handler.getName(), credential);
}
}
}
//去指定的默认策略核验,一般会在配置文件里面设置
evaluateFinalAuthentication(builder, transaction);
return builder;
} finally {
AuthenticationCredentialsThreadLocalBinder.clearInProgressAuthentication();
}
}
这里只描述了验证失败的情况,在成功的情况下只是不会走后面的登录流程而已。
觉的不错?可以关注我的公众号↑↑↑
聊聊Lync二次开发 | 字痕随行
很长时间没有碰过Lync了,因为近一年多都是在使用Java开发,Lync也已经改名(或升级?)为Skype for business,最近翻了翻MSDN上的开发资料,发现Skype多了个Web SDK,我感觉挺有意思的,有时间我会尝试一下。想想这款产品这么多年,从Communicate到Lync,再到现在的Skype,不知道二次开发的方式是否会有所创新,说实话,我对于Lync的二次开发方式很失望,因为要想将其改造的符合国情,耗费的时间、成本和精力都是巨大的。
Communicate的时候,在Client的主界面下部提供嵌入接口,可以嵌入自定义的Web应用,从而实现组织结构树、企业门户的嵌入等功能。从Lync开始,主界面的嵌入接口被关闭,微软鼓吹的一系列二次开发要不就是在通讯界面左侧嵌入Silverlight,要不就是通过菜单挂接外部可执行程序,要不就是使用UI抑制模式做一款新的Client,友好度降低很多,以至于国内的大部分企业走了另外一条路,通过破解把客户端黑掉,重绘整个界面。
最开始接触Lync二次开发的时候,是通过自定义的应用程序使用Windows API将原始的Client主界面隐藏掉,但是这样带来的问题就是不稳定,登录时的过度非常不平滑,有时候Client的主界面会跳出来,有时候会死掉,后来通过Hook的方式来解决,但是还是达不到理想的效果,杀毒软件也频繁报警,结果就是勉强应用,客户十分不满。
痛定思痛之后,决定重新挑选一条路线来完成二次开发工作。在查阅了大量资料后,由于技术储备的限制,如果走重新绘制界面的道路,觉的风险太大,所以最后选择的是使用UI抑制模式将原始UI关闭,再使用WPF技术重新开发一款客户端,结合Lync的SDK来达到最终的目的。谁知道,这个坑挖的越来越大,直到我离开上家公司,这个坑也没有被完全填补。
最开始期望实现单人聊天、多人聊天、群组聊天、文件传输、富文本传输这些主要功能,后来发现除了单人聊天能够通过Lync提供的SDK相对方便的完成,其它的功能全都是焦油坑。
由于国人用惯了QQ,所以临时讨论组和群组是不可或缺的功能,但是Lync的多人会话简直是扯淡,由一人发起然后将人员拽入,如果中途退出就无法再接收到信息,想解决这个问题就要监控上下线状态,使用SDK将人员载入,这就是很大的一个坑。
文件传输就更别说了,选择UI抑制模式就等于选择关闭文件传输功能,必须自行开发这个功能。为此,我还专门研究了一把Socket,最后服务器选择的是开源的SuperSocket,客户端参考它附带的源码改变了一下,为此还了解了封包、粘包等相关知识,费了九牛二虎之力,终于完成,但是缺陷就是非点对点,而是通过服务器中转,经常性的产生不稳定异常。面对客户方的复杂网络环境,简直就是焦头烂额。
富文本也是一大块难点,要实现图片异步加载、表情显示,最开始的时候还想仿Lync显示文件传输进度条,结果还是作罢。因为图片异步加载就已经贯穿了开发过程,不停的调整,不停的遇到BUG再解决BUG,没有开源的组件可以参考,完全就是凭借支离破碎的信息在拼凑。
整整做了1年后,才勉强出了一个可用版本,结果在整个公司试用后,不是SDK在有的机器上有问题,就是各种莫名其妙的崩溃和掉线,整个项目组只能见招拆招,疲于招架。说实话,使用UI抑制模式去开发,还不如自己重新做个企业沟通工具,都比基于Lync SDK去开发简单,我用血和泪的亲身体验总结出,这条路根本走不通,更不要说还有视频和语音会话,再加上电话会议,想想就感到后怕。
在离职之后,我又了解了一下破解,泡了一段日子看雪论坛,唯一想到的是通过DLL劫持技术,将自己的DLL打入到Lync的进程中去,这样的话杀毒软件不会报警,而且可以通过Windows API控制Lync主界面,也可以集成自己的EXE程序,可是没有机会去尝试,最后也懒的尝试。
因为我觉的Lync二次开发简直就是个性价比极差的差事,如果不是为了其它目的,只是单纯的满足客户的需要,这种项目完全可以不做,投入巨大,产出很小,除非你有一堆好手,能破解、懂网络,从C到C++到C#全部精通的好手。不过既然都有这样的人才了,干点其它的什么不行呢,非得跟这上吊死,岂不是吃饱了撑的。
如果Skype的Web SDK有所改善,可以做一些轻量级的集成,我觉的倒是一条可选的道路,毕竟HTML和Javascript相结合起来,做界面要比Client容易的多,而且在普通的OA或者门户中集成一些轻量级的应用,比如在线的情况、简易聊天、呼出客户端等等的定制,也要容易的多。从性价比上来讲,有一定的可能性。
在互联网大潮席卷的当下,在开源大势所趋的时候,在Java大行其道的情况下,微软这些年的日子确实不太好过,基因决定了它转身很难,虽然总是在尝试,但是总是在失败。不过还是希望.NET不要太式微,毕竟多一份选择,这个市场就多一份活力,封闭的市场还是很难长久的,所以也希望Skype for business比起它的前辈,能够有所突破。
如果有问题,欢迎指正讨论。

觉的不错?可以关注我的公众号↑↑↑
LyncServer2013标准版安装部署 | 字痕随行
软硬件准备
Lync Server 2013的最小安装环境只需要两台独立的服务器(一台域控,一台Lync Server),准备好硬件后,需要准备以下必备软件:
- Windows Server 2012 R2 Datacenter。其实Lync Server 2013可以使用Windows Server 2008 R2 SP1 或最新的 Service Pack、Windows Server 2012、Windows Server 2012 R2中的任何一项。但是需要注意的是Lync Server 2013 只提供 64 位版本,要求使用 64 位硬件和 64 位版本的 Windows Server 操作系统。此发行版不提供 Lync Server 2013 的 32 位版本。
- Silverlight的64位安装程序。
- Lync Server 2013安装程序。
- Microsoft .NET Framework 4.5安装程序。
因为是安装开发环境,只需要部署Lync Standard Edition Server,所以不用准备Microsoft SQL Server的安装程序,届时会自动使用SQL Server Express。
安装前准备
- 为两台服务器安装操作系统。
- 为服务器重命名(比如作为域控的一台叫做DC1,作为Lync Server前端服务器的叫做LyncFront)。
- 为两台服务器安装Microsoft .NET Framework 4.5。
- 为作为Lync Server的服务器安装Silverlight。
- 安装和配置域服务器。可以参考《Windows Server 2012体验之部署第一台域控制器》来搭建域服务器。如果不幸添加了不需要的角色或功能,可以参考《Windows Server 2012之活动目录域服务的卸载》来删除。
- 为域服务器添加证书服务。
- 将安装Lync Server的服务器加入已配置完毕的域。
- 在域控服务器上准备DNS。准备完毕后,如下图:
- 在将要安装Lync Server的服务器上添加必须的Windows角色和功能,完毕后如下图:
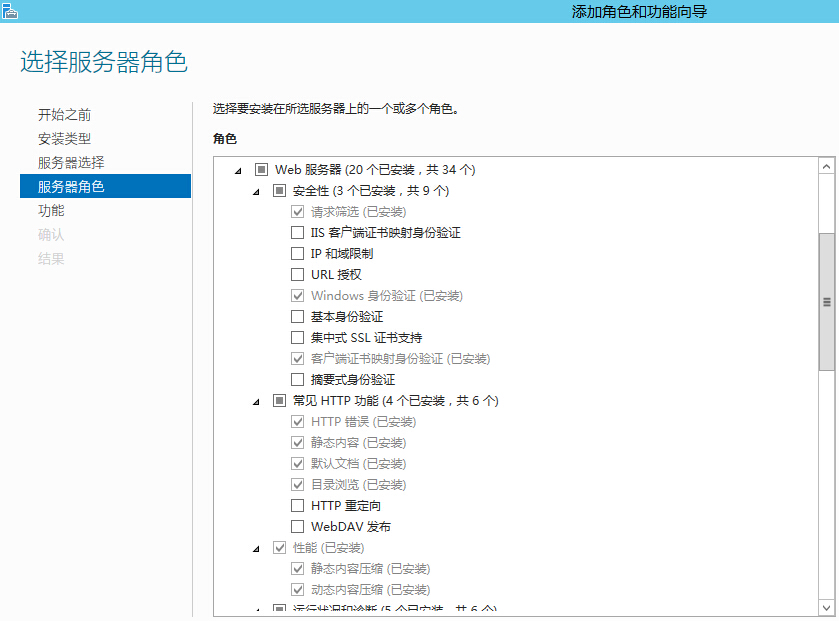
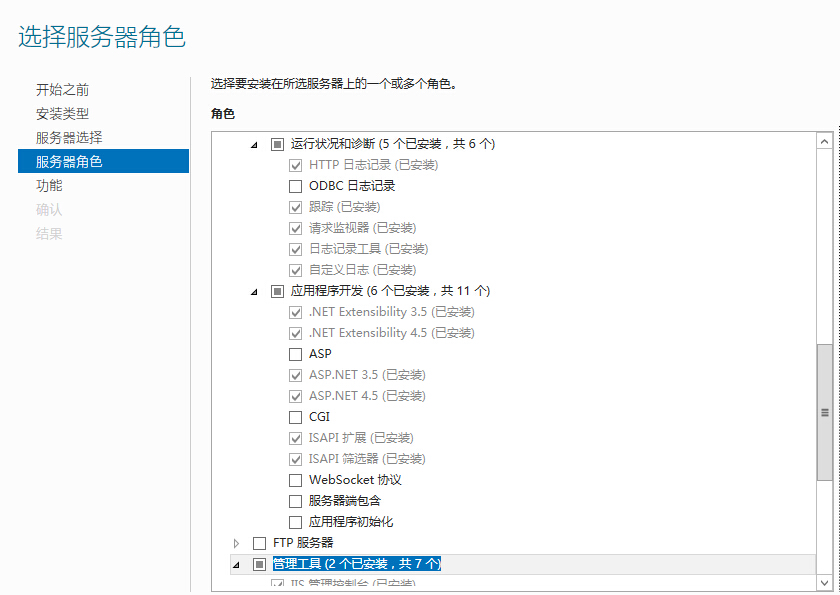
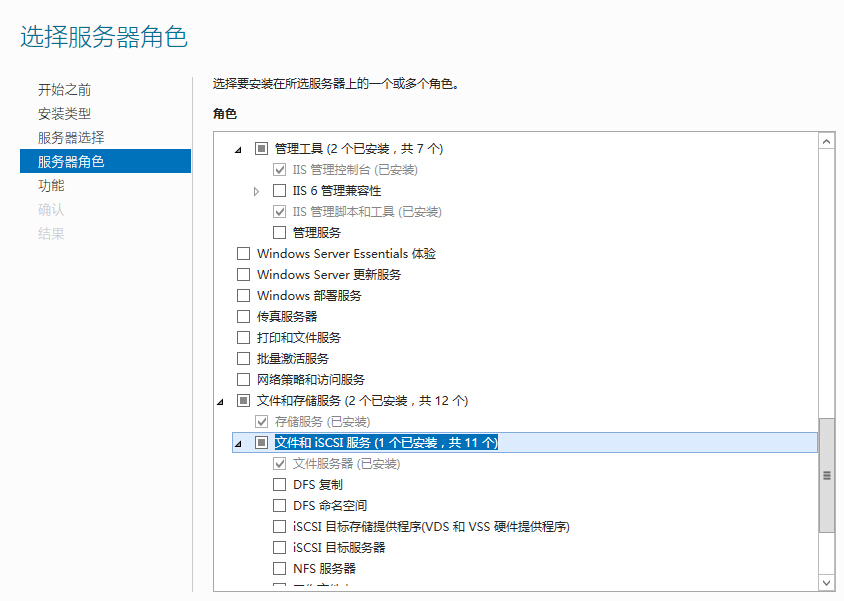
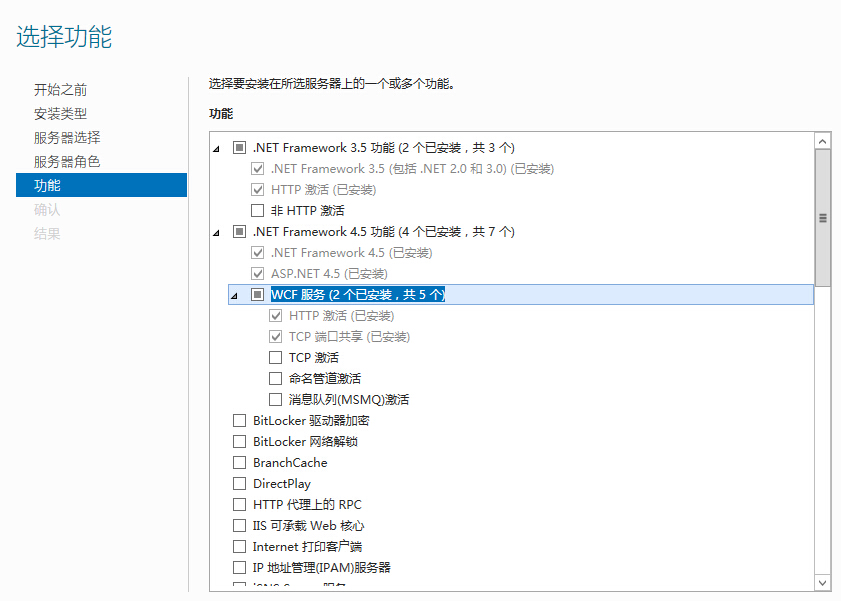
安装Lync Server 2013
可以参考《Lync Server 2013安装部署图文教程》、《Lync Server 2013部署》。
可能遇到的问题
- 在配置域时,提示:"新建域时,本地administrator帐户将成为域administrator账户。无法新建域,因为本地administrator账户密码不符合要求。目前,本地administrator账户不需要密码。我们建议您使用网络用户命令行工具的/passwordreq:yes选项获得该账户密码,然后再新建设域:否则,域administator帐户将不需要密码。 在命令行下键入命令“net user administrator /passwordreq:yes”,回车后即可解决。
- 安装Lync Server 2013中需要请求证书,如果出现异常提示根证书不可信任,一般是由于安装Lync Server的服务器加入域后才在域中安装了证书服务器所导致的,可以将CA的根证书导出,并将其导入到前端服务器的“计算机账户”的“受信任的根证书颁发机构”中,然后再次尝试证书方面的操作。如何导出CA的根证书可以参考http://support.microsoft.com/kb/555252。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Lync开发-基础
什么是Lync SDK?
此处以Microsoft Lync 2010 SDK为例说明,其SDK包括:
- 在项目中使用的Microsoft.Office.Ocom.dll和Microsoft.Office.uc.dll应用程序集。
- Lync 2010控件(Controls)。
- Lync 2010的API。
- Lync 2010的框架程序员指南。
- 示例应用程序。
Microsoft Lync 2010 SDK是一个客户端API,它结合了微软的Lync自动化API的自动化功能与微软的统一通信客户端API的功能。访问一个使用Lync 2010 SDK开发的应用程序中的Lync API功能,必须在本地主机上启动一个Microsoft Lync 2010 Client。
Lync SDK的获取与安装
你可以在以下地址下载适合自己所需要的安装包:
下载完毕后,在开发机上运行即可。
什么是Microsoft Lync Controls?
Lync SDK中提供了一些控件,每个Lync Control提供了一个特定的功能,如搜索、在线状态等,每个控件的外观复制了Lync Client的UI。
需要注意的是:如果Lync UI Suppression(Lync UI 抑制模式)被打开,则不能使用Lync Controls。
什么是Lync UI Suppression?
Lync UI Suppression即Lync UI抑制模式。当开启Lync UI Suppression时,可以完全隐藏Microsoft Lync 2010客户端界面(双击安装路径下的communicator.exe时毫无反应)。UI抑制是非常有用的,它可以让我们开发定制另类的UI。但是需要注意的是,Lync UI Suppression开启时,Automation和Lync Controls是不可用的。
如何开启Lync UI Suppression?
如果电脑是64位操作系统,可以修改注册表中的键“HKLM\SOFTWARE\Wow6432Node\Microsoft\Communicator\UISuppressionMode”的值为“1”,即可开启。
如果电脑是32位操作系统,可以修改注册表中的键“HKLM\SOFTWARE\Microsoft\Communicator\UISuppressionMode”的值为“1”,即可开启。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
LYNC开发-GetClient() | 字痕随行
获取客户端模型
使用Lync SDK开发时,最重要的是要先获取客户端模型,即Microsoft.Lync.Model. LyncClient,我们可以使用以下方法获取客户端模型:
_lyncClient = LyncClient.GetClient();
如果没有处于UI抑制模式下,使用上面的方法已经可以获取到客户端模型了,并且可以使用客户端模型做一些操作,比如登录。但是在此之前,必须将Microsoft Lync Client启动起来,否则就会出现错误;如果处于UI抑制模式下,使用以上的方式可以获得客户端模型,但是不能使用,因为此时进程communicator.exe并没有运行。
初始化客户端模型
如果Micorosoft Lync Client处于UI抑制模式下,我们运行程序时是没有反应的,使用GetClient()方法,我们只会获得客户端模型,而不会启动communicator.exe。所以在我们获取到客户端模型后,还需要调用相应的方法初始化客户端模型,以便启动communicator.exe。
我们可以使用以下方法初始化客户端模型:
if (_lyncClient.InSuppressedMode)
{
if (_lyncClient.State == ClientState.Uninitialized)
{
_lyncClient.BeginInitialize(LyncClientInitializeCallback, _lyncClient);;
}
}
private void LyncClientInitializeCallback(IAsyncResult ar)
{
if (ar.IsCompleted)
{
((LyncClient)ar.AsyncState).EndInitialize(ar);
}
}
上述代码中的LyncClient.BeginInitializ方法是用来在UI抑制模式下初始化LyncClient的,在非UI抑制模式下,并不需要调用此方法。
MSDN参考链接:Understanding UI Suppression in Lync SDK
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
LYNC开发-登录 | 字痕随行
本文将描述如何使用Microsoft Lync SDK控制Microsoft Lync Client完成登录。
图示
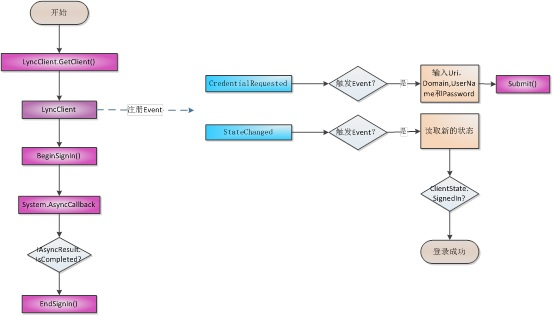
说明
- 初始化客户端模型,使用《Lync开发-GetClient()》中所介绍的方法获取LyncClient。
- 注册客户端模型事件“StateChanged”和“CredentialRequested”。
lyncClient.StateChanged += LyncClient_StateChanged;
lyncClient.CredentialRequested += LyncClient_CredentialRequested;
- 调用BeginSignIn方法,开始登录。
lyncClient.BeginSignIn(_strSIP, null, null, LyncSignInCallback, _lyncClient);
- 触发CredentialRequested事件。
void LyncClient_CredentialRequested(object sender, CredentialRequestedEventArgs e)
{
if (e.Type == CredentialRequestedType.SignIn)
{
e.Submit(strUserName, strPassWord, blIsRememberPWD);
}
}
- 调用EndSignIn方法,结束登录。
void LyncSignInCallback(IAsyncResult ar)
{
if (ar.IsCompleted)
{
try
{
((LyncClient)ar.AsyncState).EndSignIn(ar);
}
catch
{
throw;
}
}
}
- 触发StateChanged事件。
void LyncClient_StateChanged(object sender, ClientStateChangedEventArgs e)
{
if (e.NewState == ClientState.SignedIn)
{
//登录成功
}
}
注意事项
调用BeginSignIn方法时,如果第二个和第三个参数输入为null,则会触发CredentialRequested事件。如果输入域账户名称和密码,在正确的情况下会成功登录,并不会触发CredentialRequested事件。
触发CredentialRequested事件,调用Submit方法提交用户信息时,如果用户凭证正确,则登录成功;如果用户凭证不正确,则会再次触发CredentialRequested事件。如果_blIsRememberPWD 等于true,会生成相应的用户证书,下一次调用BeginSignIn方法时,只需要SIP地址(第一个参数),就可以成功登录。
MSDN参考:How to: Sign In to Lync with UI Suppressed
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
LYNC开发-Contact | 字痕随行
本文将描述如何使用Microsoft Lync SDK获取联系人信息。
获取联系人信息
可以通过Contact对象所提供的方法获取联系人信息,Contact对象隶属于命名空间Microsoft.Lync.Model,在获取联系人信息时,会使用到以下属性和方法:
| 名称 | 说明 | |
|---|---|---|
| 方法 | GetContactInformation(ContactInformationType) | 从Contact对象中获取单一的联系人信息 |
| 属性 | ContactManager | 获取此联系人的父联系人和组管理 |
| 属性 | CustomGroups | 获取此联系人的联系人组列表 |
| 属性 | Uri | 获取联系人的Uri |
其中枚举ContactInformationType主要内容如下:
| 名称 | 说明 | |
|---|---|---|
| Availability | 联系人可用性(在线状态),联系人信息项的值类型是AvailabilityType枚举。 | |
| Activity | 联系人的当前活动(例如,在手机上,在会议上,或可用)。联系人信息项的值类型为String。 | |
| DisplayName | 联系人的显示名称。联系人信息项的值类型为String。 | |
| PersonalNote | 个人注释。联系人信息项的值类型为String。 | |
| Photo | 联系人的照片。联系人信息项的值类型是Stream对象。 |
- 获得联系人信息的示例代码如下:
//获取contact
contact = LyncClient.GetClient().ContactManager.GetContactByUri(strSIP);
//获取联系人的显示名称
contact.GetContactInformation(ContactInformationType.DisplayName).ToString()
//获取联系人的在线状态
(ContactAvailability)contact.GetContactInformation(
ContactInformationType.Availability);
//获取联系人的Uri
contact.Uri;
- 获得联系人的联系人组列表示例代码如下:
foreach (Group tempGroup in LyncClient.GetClient().ContactManager.Groups)
{
}
MSDN参考资料:Get started with Lync contact lists
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
Lync开发-Conversation | 字痕随行
本文将介绍Lync Client SDK中的Conversation类。类Conversation属于命名空间Microsoft.Lync.Model.Conversation。它描述了会话,包括了一些详细信息,如会话参与者、收发模式(即时信息,音频/视频)、状态等。并且实现了合并、终止等其它会话动作。它的重要成员如下:
| 名称 | 说明 | |
|---|---|---|
| 方法 | AddParticipant(Contact) | 将Contact添加到该会话中。 |
| 方法 | BeginSetProperty | 设置此Conversation的属性。 |
| 方法 | RemoveParticipant | 移除某一个参与者。 |
| 方法 | End | 终止在本地端点上的会话。如果会话是一个会议,对其他参与者该会议将继续有效。 |
| 属性 | ConversationManager | 获取此会话的父级会话管理器。 |
| 属性 | Modalities | 获取会话模式的集合。例如,即时消息模式或音频/视频模式。 |
| 属性 | Participants | 获取参与者集合。 |
| 属性 | SelfParticipant | 获取作为参与者的当前登录用户。 |
| 属性 | State | 获取作为参与者的当前登录用户。 |
| 事件 | ParticipantAdded | 获取作为参与者的当前登录用户。 |
| 事件 | ParticipantRemoved | 当参与者从会话中被移除时发生。 |
如何创建会话
可以通过Microsoft Lync SDK提供的API接口创建会话,主要的步骤如下:
- 登录Lync客户端,并且获取LyncClient实例。
- 为LyncClient实例注册事件ConversationAdded。
- 通过读取LyncClient对象的属性ConversationManager获取ConversationManager实例。
- 调用方法AddConversation。
简单的示例代码如下:
lyncClient = LyncClient.GetClient();
lyncClient. ConversationAdded += ConversationManager_ConversationAdded
conversation = lyncClient. ConversationManager.AddConversation();
void ConversationManager_ConversationAdded(object sender, ConversationManagerEventArgs e)
{
//新增会话后触发事件,可在此添加会话参与者
}
当会话创建之后,会话中只有创建者本人,一个完整的会话至少还需要一名参与者,添加其他参与者的示例代码如下:
contact = lyncClient. ContactManager.GetContactByUri(strSIP);
conversation.ParticipantAdded += Conversation_ParticipantAdded;
conversation.AddParticipant(contact);
void Conversation_ParticipantAdded(object sender, ParticipantCollectionChangedEventArgs e)
{
}
会话创建完毕后,其他参与者还暂时无法知道此会话的存在,需要发送一条消息通知其他参与者,其他参与者在收到这条消息时,就会触发自身的ConversationAdded事件。
MSDN参考资料:Get started with Lync conversations
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
UCMA开发-基础 | 字痕随行
UCMA SDK
UCMA全称Microsoft Unified Communications Managed API,最新版本为4.0,主要用来构建工作在Microsoft Lync Server上的中间层应用程序。开发人员可以使用该平台构建应用程序,以提供对 Microsoft Lync Server增强状态信息、即时消息、电话、视频呼叫和音频/视频会议的访问和控制能力。
UCMA特性
可模拟实际用户进行语音和视频等通讯。
可控制大量的并发通讯。提供同类中最佳的语音传输质量。
语音识别及语音合成。
UCMA开发准备
UCMA开发的应用程序不能脱离Microsoft Lync Server独立运行,承载其开发环境的终端必须安装有Microsoft Lync Server。
Microsoft Lync Server 2010安装可以参考其它资料。
UCMA3.0下载:
http://www.microsoft.com/en-us/download/details.aspx?id=10566
UCMA4.0下载:
http://www.microsoft.com/en-us/download/details.aspx?id=35463
注意:UCMA3.0适合Microsoft Lync Server 2010,UCMA4.0适合Microsoft Lync Server 2013。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
UCMA开发-总览介绍 | 字痕随行
基本上所有的介绍都基于命名空间Microsoft.Rtc.Signaling,如果有其它的相关介绍,会追加更新。
Microsoft.Rtc.Signaling
此命名空间内的类提供了连接到主机、调度会话、控制通道以便使一个EndPoint可以邀请另外一个EndPoint,它封装了低层次的会话发起协议(SIP)功能。下图显示了该命名空间的主要组成:
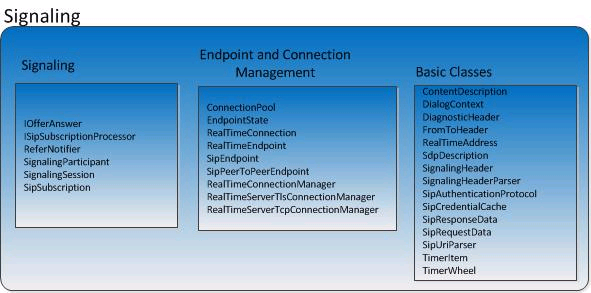
Connection Manager
连接管理器的主要功能是管理传入和传出连接。一个类继承自抽象RealTimeConnectionManager类的实例,可以用来管理出站连接。一个RealTimeServerConnectionManager实现(RealTimeServerTcpConnectionManager或RealTimeServerTlsConnectionManager)用于管理传入的连接。
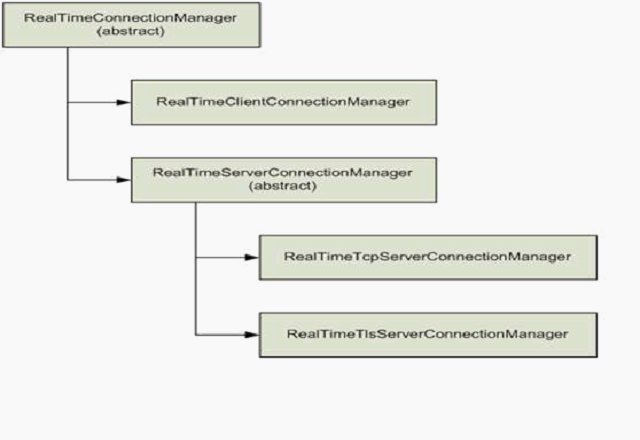
其中,RealTimeTcpServerConnectionManager是TCP连接,RealTimeTlsServerConnectionManager是TLS安全连接。
EndPoint
EndPoint是在SIP网络中的路由实体。一个实时通信的应用程序创建一个实时的端点,使用户能够利用多种类型的多个设备实时地与其他用户进行通信,每个设备对应于该用户的唯一的EndPoint。例如,一个用户透过一个EndPoint从一个桌面客户端发送即时消息,同一用户在移动电话上应答呼叫是透过另一个EndPoint,这种情况被称为多点状态(MPOP)。
SipEndPoint类派生自RealTimeEndPoint,SipEndPoint必须在SIP服务器上注册,才能使用这种类型的其他端点进行通信。应用程序可以使用一个SipEndpoint实例来使用户能够发布或订阅数据的订阅会话,或使用SignalingSession来发送或接收邀请。
SipPeerToPeerEndPoint类派生自RealTimeEndPoint,可以不需要在服务器存在的情况下创建,但是存在一定的局限性,由于不和真实的Server创建连接,那么就无法监听来自服务器的接入和接出的连接,只能限于本身和其他机器之间的通信。
SignalingSession
SignalingSession提供一个EndpPoint可以邀请另一个EndPoint参加一些活动或建立媒体沟通交流的控制通道。两个EndPoint可以使用已建立的SignalingSession彼此之间交换控制短消息以及文本信息,支持的消息类型为列举的消息类型枚举。
可参考的资料:
http://www.cnblogs.com/vipyoumay/archive/2012/01/12/2320801.html
http://msdn.microsoft.com/en-us/library/office/dn465974(v=office.15).aspx
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
UCMA开发-SipEndPoint | 字痕随行
本文的目的在于讲解如何创建、使用SipEndPoint,为之后构建自动应答机器人做准备。
Constructors
| 名称 | 说明 | |
|---|---|---|
| SipEndpoint(String, SipAuthenticationProtocols, SipTransportType, String) | 创建SipEndpoint的新实例。这个端点是基于服务器的。默认情况下,该平台将为TCP使用端口5060 ,为TLS使用端口5061。要使用一个在这些之外的端口,调用方应尝试注册之前设置端口属性。 | |
| SipEndpoint(String, SipAuthenticationProtocols, SipTransportType, String, Int32, Boolean, RealTimeConnectionManager, String) | 创建SipEndpoint的新实例。这个端点是基于服务器的。 |
Methods
| 名称 | 说明 | |
|---|---|---|
| BeginRegister(AsyncCallback, Object) | 为当前EndPoint启动异步注册操作。 | |
| BeginRegister( IEnumerable, AsyncCallback, Object) | 为当前EndPoint启动异步注册操作 | |
| Register() | 同步注册当前的EndPoint,此方法将等待,直到注册完成,不推荐在UI线程内使用 | |
| Register(IEnumerable) | 同步注册当前的EndPoint,此方法将等待,直到注册完成,不推荐在UI线程内使用 | |
| BeginUnregister | 开始异步注销当前EndPoint,这个方法总是成功 | |
| Unregister | 同步注销当前的EndPoint,不推荐在UI线程使用 | |
| BeginTerminate | 开始终止EndPoint,并且清理活动的会话和资源。端点不再可用(继承自RealTimeEndpoint) | |
| Terminate | 终止EndPoint和清理活动的会话和资源,端点不再可用(继承自RealTimeEndpoint) |
Properties
| 名称 | 说明 | |
|---|---|---|
| CredentialCache | 获取凭证缓存 | |
| RegistrationState | 获取当前EndPoint的注册状态 |
Events
| 名称 | 说明 | |
|---|---|---|
| MessageReceived | 收到消息时触发(继承自RealTimeEndpoint) | |
| SessionReceived | 收到新的邀请时触发(继承自RealTimeEndpoint) |
Example
SipEndpoint sipEndPoint;
try
{
//strUri为EndPoint地址,必须以“sip:”开始
sipEndPoint = new SipEndpoint(strUri,
SipAuthenticationProtocols.None,
SipTransportType.Tls,
_strServerName,
5061,
true,
_connectionManager,
null);
sipEndPoint.CredentialCache.Add(
SipEndpoint.DefaultRtcRealm,
CredentialCache.DefaultNetworkCredentials);
}
catch (Exception ex)
{
throw ex;
}
//创建信号头
List headers = new List();
headers.Add(SignalingHeader.MicrosoftSupportedForking);
//如果是未注册状态则注册
if (sipEndpoint.RegistrationState == RegistrationState.Unregistered)
{
sipEndpoint.Register(headers);
}
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
UCMA开发-SignalingSession | 字痕随行
本文的目的在于讲解如何创建、使用SignalingSession,为之后构建自动应答机器人做准备。
Constructors
| 名称 | 说明 | |
|---|---|---|
| SignalingSession(RealTimeEndpoint, RealTimeAddress) | 使用端点(EndPoint)和目标初始化一个信令会话(SignalingSession) |
Methods
| 名称 | 说明 | |
|---|---|---|
| BeginAccept(AsyncCallback, Object) | 接受会话 | |
| BeginEstablish(AsyncCallback, Object) | 建立会话 | |
| BeginParticipate(AsyncCallback, Object) | 加入一个会话,这个方法需要调用(用户传入和传出消息)已建立的会话 | |
| BeginSendMessage(MessageType, ContentType, Byte [],AsyncCallback, Object) | 发送一条消息,会话应该在连接状态 | |
| BeginSendMessage(MessageType, ContentType, Byte [],IEnumerable, AsyncCallback, Object) | ||
| BeginTerminate(AsyncCallback, Object) | 异步终止会话,本次会话将不再可用 |
Properties
| 名称 | 说明 | |
|---|---|---|
| OfferAnswerNegotiation | 获取或设置由调用者实现并提供的应答协商接口 | |
| State | 获取或设置会话的状态 |
Events
| 名称 | 说明 | |
|---|---|---|
| MessageReceived | 收到消息时触发 |
Example
//直接建立SignalingSession,并发送消息
RealTimeAddress target = new RealTimeAddress(strRemoteUri);
SignalingSession session = new SignalingSession(sipEndPoint, target);
session.OfferAnswerNegotiation = this;
try
{
session.EndEstablish(session.BeginEstablish(null, null));
break;
}
catch
{
Thread.Sleep(10);
}
ContentType contentType = new ContentType("text/plain; charset=UTF-8");
byte[] msgBody = Encoding.UTF8.GetBytes(strMessage);
try
{
session.SendMessage(
MessageType.Message,
contentType,
msgBody);
}
catch (Exception ex)
{
throw ex;
}
session.EndTerminate(session.BeginTerminate(null, null));
//通过SipEndPoint的SessionReceived事件来建立
void SipEndpoint_SessionReceived(object sender, SessionReceivedEventArgs e)
{
e.Session.OfferAnswerNegotiation = this;
//开始参与该会话Session
try
{
e.Session.BeginParticipate(
new AsyncCallback(ParticipateCallback), e.Session);
}
catch
{
}
}
//参与处理回发事件
void ParticipateCallback(IAsyncResult ar)
{
SignalingSession session = ar.AsyncState as SignalingSession;
SipMessageData response = null;
try
{
response = session.EndParticipate(ar);
session.SendMessage(
MessageType.Message,
contentType,
msgBody);
}
catch
{
}
}
关于“Session.OfferAnswerNegotiation = this;”的解释:
this其实代表了继承IOfferAnswer接口的类,在示例中,因为代码段所属的类继承并实现了IOfferAnswer接口的,所以可以直接将自己赋值给OfferAnswerNegotiation属性,IOfferAnswer的实现见下面的示例代码:
#region IOfferAnswer 接口实现
//Occurs when we receive and INVITE with no offer
public ContentDescription GetAnswer(object sender, ContentDescription offer)
{
return GetContentDescription((SignalingSession)sender);
}
//Occurs when we receive an invite with an offer
public ContentDescription GetOffer(object sender)
{
return GetContentDescription((SignalingSession)sender);
}
//Occurs in Reinvite cases
public void HandleOfferInInviteResponse(object sender, OfferInInviteResponseEventArgs e)
{
return;
}
//Occurs in Reinvite cases
public void HandleOfferInReInvite(object sender, OfferInReInviteEventArgs e)
{
return;
}
//Occurs when we initiate the invite
public void SetAnswer(object sender, ContentDescription answer)
{
SignalingSession session = sender as SignalingSession;
byte[] Answer = answer.GetBody();
if (Answer != null)
{
Sdp<SdpGlobalDescription, SdpMediaDescription> sessionDescription =
new Sdp<SdpGlobalDescription, SdpMediaDescription>();
if (!sessionDescription.TryParse(Answer))
{
session.BeginTerminate(null, session);
return;
}
else
{
IList ActiveMediaTypes =
sessionDescription.MediaDescriptions;
if ((ActiveMediaTypes.Count == 1) &&
(ActiveMediaTypes[0].MediaName.Equals("message",
StringComparison.Ordinal)) &&
(ActiveMediaTypes[0].Port > 0) &&
(ActiveMediaTypes[0].TransportProtocol.Equals("sip",
StringComparison.OrdinalIgnoreCase)))
{
}
else
{
session.BeginTerminate(null, session);
}
}
}
}
//Retrieves the content description for offers and answers
private ContentDescription GetContentDescription(SignalingSession session)
{
IPAddress ipAddress;
// This method is called back every time an outbound INVITE is sent.
if (session.Connection != null)
{
ipAddress = session.Connection.LocalEndpoint.Address;
}
else
{
ipAddress = IPAddress.Any;
}
Sdp<SdpGlobalDescription, SdpMediaDescription> sessionDescription =
new Sdp<SdpGlobalDescription, SdpMediaDescription>();
//Set the origin line of the SDP
//s, t, and v lines are automatically constructed
sessionDescription.GlobalDescription.Origin.Version = 0;
sessionDescription.GlobalDescription.Origin.SessionId = "0";
sessionDescription.GlobalDescription.Origin.UserName = "-";
sessionDescription.GlobalDescription.
Origin.Connection.Set(ipAddress.ToString());
//Set the connection line
sessionDescription.GlobalDescription.Connection.TrySet(ipAddress.ToString());
SdpMediaDescription mditem = new SdpMediaDescription("message");
mditem.Port = 5061;
mditem.TransportProtocol = "sip";
mditem.Formats = "null";
SdpAttribute aitem = new SdpAttribute("accept-types", "text/plain");
mditem.Attributes.Add(aitem);
//Append the Media description to the Global description
sessionDescription.MediaDescriptions.Add(mditem);
ContentType ct = new ContentType("application/sdp");
return new ContentDescription(ct, sessionDescription.GetBytes());
}
#endregion
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
UCMA开发-ConnectionManager
本文的目的在于讲解如何创建RealTimeServerTlsConnectionManager,为之后构建自动应答机器人做准备。
Constructors
| 名称 | 说明 | |
|---|---|---|
| RealTimeServerTlsConnectionManager(String,Byte[]) | 使用默认的本地主机名称和给定的证书信息实例化 | |
| RealTimeServerTlsConnectionManager(String, String, Byte[]) | 使用给定的本地主机名称和给定的证书信息实例化 |
Methods
| 名称 | 说明 | |
|---|---|---|
| StartListening | 开始监听指定的地址和端口(继承自RealTimeServerConnectionManager) | |
| StopListening | 停止监听新的连接(继承自RealTimeServerConnectionManager) |
Properties
| 名称 | 说明 | |
|---|---|---|
| IsListening | 获取监听是否启用(继承自RealTimeServerConnectionManager。) | |
| ListeningPort | 获取监听端口(继承自RealTimeServerConnectionManager。) | |
| NeedMutualTls | 获取或设置一个MutualTls连接对于传出的Tls连接是否是必须的 |
Example
RealTimeConnectionManager _connectionManager;
RealTimeServerTlsConnectionManager _serverTlsConnectionManager;
try
{
_serverTlsConnectionManager = new RealTimeServerTlsConnectionManager(
_strCertificateIssuerName, _strCertificateSerialNumber);
}
catch (TlsFailureException ex)
{
throw ex;
}
_serverTlsConnectionManager.NeedMutualTls = true;
_connectionManager = (RealTimeConnectionManager)_serverTlsConnectionManager;
IPAddress localIpAddress = Dns.GetHostAddresses(Dns.GetHostName())[1];
if (!_serverTlsConnectionManager.IsListening)
{
_serverTlsConnectionManager.StartListening(new IPEndPoint(localIpAddress, 0));
}
如何获取证书,可以参考如下代码:
//using System.Security.Cryptography.X509Certificates;
X509Store store = new X509Store(StoreName.My, StoreLocation.LocalMachine);
try
{
store.Open(OpenFlags.ReadOnly | OpenFlags.OpenExistingOnly);
}
catch (System.Security.SecurityException)
{
MessageBox.Show("你没有权限枚举本地计算机存储的证书");
return;
}
if (store.Certificates.Count < 1)
{
MessageBox.Show("请确保证书存在");
return;
}
//遍历寻找适合的证书
foreach (X509Certificate2 certificate in store.Certificates)
{
StringBuilder sb = new StringBuilder();
XmlWriter writer = XmlWriter.Create(sb);
writer.WriteStartElement("root");
writer.WriteBinHex(
certificate.GetSerialNumber(), 0, certificate.GetSerialNumber().Length);
writer.WriteEndElement();
writer.Close();
this.txtReport.AppendText(
"IssuerName:" + certificate.Issuer
+ "\\r\\nSerialNumber:" + sb.ToString() + "\\r\\n\\r\\n");
}
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
UCMA开发-互动消息机器人的实现 | 字痕随行
引用原文自:http://bbs.winos.cn/thread-73856-1-1.html
这次将的是开发OCS 互动消息机器人,通过TCP连接方式。互动机器人的重点是接受会话,所以终端需要去OCS服务器上注册过。使用的终端类为SipEndpoint。
准备参数:
- robot的sip地址 必须是在AD中存在的OC用户。
- OCS的FQDN
实现步骤
一些相同和上面相同的就不介绍了。
- 创建项目,添加引用。
- 创建RealTimeServerTcpConnectionManager。
- 创建SipEndpoint。
SipEndpoint sipEndpoint = new SipEndpoint(_ownerUri
, SipAuthenticationProtocols.Ntlm
, SipTransportType.Tcp
, _ocsFQDN
, 5060
, true
, rtsTcpConnectionMgr
, null
);
- 注册SipEndpoint。
sipEndpoint.Register();
- SipEndpoint 添加Session接收事件。
sipEndpoint.SessionReceived += sipEndpoint\_SessionReceived;
- SessionReceived 事件的处理。
private void sipEndpoint\_SessionReceived(object sender, SessionReceivedEventArgs e)
{
Console.WriteLine("a session received...");
SignalingSession session = e.Session;
session .OfferAnswerNegotiation = \_sipOfferAnswer;
Console.WriteLine("Participate session");
session .BeginParticipate(CompleteParticipate, session);
}
在这一步中,主要是接收其他终端发送过来的Invite请求,然后我们在接收到Invite后需要回复一条加入Session的请求,我使用异步方式加入。
- Session participate的callback处理。
private void CompleteParticipate(IAsyncResult ar)
{
SignalingSession session = ar.AsyncState as SignalingSession;
try
{
session.EndParticipate(ar);
session.MessageReceived += session\_MessageReceived;
}
catch (System.Exception e)
{
Console.WriteLine(e.ToString());
}
}
在callback过程中,我们为session添加了MessageReceived事件。
8、MessageReceived 事件的处理。
private void session\_MessageReceived(object sender, MessageReceivedEventArgs e)
{
SignalingSession session = sender as SignalingSession;
if (e.MessageType== MessageType.Message)
{
Console.WriteLine(e.TextBody);
session.SendMessage(MessageType.Message
, new System.Net.Mime.ContentType("text/plain")
, Encoding.UTF8.GetBytes("message received.")
);
}
}
在这里我们把收到的消息显示出来了,并回复了一条"message received"。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
UCMA开发-自动回复机器人 | 字痕随行
本文将基于之前介绍的开发基础,来讲述如何使用UCMA创建一个可以自动回复的机器人程序。
第一步
创建ConnectionManager,这是通讯的基础。参考《UCMA开发之ConnectionManager》一文中所介绍的方法完成创建。
第二步
生成SipEndPoint。此SipEndPoint就代表所要创建的机器人,SipEndPoint创建时依赖唯一的SIP地址,所以创建此机器人后,凡是发送给此SIP地址的信息,都会获得自动回复。可以参考《UCMA开发-SipEndPoint》一文中所介绍的方法完成创建,但是实际的创建要稍显复杂一些。
SipEndpoint sipEndPoint;
try
{
//《UCMA开发之SipEndPoint》中的new SipEndPoint()代码段
……
//注册Session接收事件
//如果发起了新的会话就会被触发,此时需要参与至新会话中
sipEndPoint.SessionReceived += SipEndpoint\_SessionReceived;
}
catch (Exception ex)
{
throw ex;
}
//如果是注册状态则注销,为下一次注册准备
if (sipEndPoint.RegistrationState == RegistrationState.Registered)
{
sipEndPoint.Unregister();
}
//创建信号头
List headers = new List();
headers.Add(SignalingHeader.MicrosoftSupportedForking);
//如果是未注册状态则注册
if (sipEndPoint.RegistrationState == RegistrationState.Unregistered)
{
sipEndPoint.Register(headers);
}
//如果是注册状态则注销,为下一次注册准备
if (sipEndPoint.RegistrationState == RegistrationState.Registered)
{
sipEndPoint.Unregister();
}
//如果未注册则注册
//两次注册以保证服务器正确发布注册终端及其端口号
if (sipEndPoint.RegistrationState == RegistrationState.Unregistered)
{
sipEndPoint.Register(headers);
}
第三步
处理SessionReceived事件。当其他联系人向第二步生成的SipEndPoint发送消息时,会首先创建新的SignalingSession,并且触发SessionReceived事件将其抛出,当事件被触发时,需要控制当前的SipEndPoint参与至此会话。
void SipEndpoint\_SessionReceived(object sender, SessionReceivedEventArgs e)
{
//参见《UCMA开发之SignalingSession》
e.Session.OfferAnswerNegotiation = this;
//开始参与该会话Session
e.Session.BeginParticipate(new AsyncCallback(ParticipateCallback), e.Session);
}
void ParticipateCallback(IAsyncResult ar)
{
SignalingSession session = ar.AsyncState as SignalingSession;
SipMessageData response = null;
try
{
response = session.EndParticipate(ar);
//参与至新会话后,就可以注册消息接收事件
//当新消息到达时,会触发此事件
session.MessageReceived += SipEndpoint\_MessageReceived;
}
catch(Exception ex)
{
throw ex;
}
}
第四步
处理SignalSession的MessageReceived事件。在这一步中,其实就是机器人的最终实现,可以根据联系人发送的消息内容进行回复。
void SipEndpoint\_MessageReceived(object sender, MessageReceivedEventArgs e)
{
SignalingSession session = sender as SignalingSession;
//如果信息类型是消息,则触发接收事件并自动进行回复
if (e.MessageType == MessageType.Message)
{
//自动回复
session.SendMessage(MessageType.Message
, new System.Net.Mime.ContentType("text/plain")
, Encoding.UTF8.GetBytes("信息已被机器人自动接收!"));
}
}
在第四步中,其实可以按照业务逻辑完成不同的操作或者回复不同的消息,比如:当天天气信息,联系人电话等等。这个示例就是介绍如何使用UCMA制作一个无人值守的机器人,在创建时主要要注意以下几点:
- 使用最新的凭证来创建RealTimeConnectionManager,否则很容易在接下来的的步骤中发生“UnKnown Error”。
- 将SipEndPoint注册两次,以保证其能够正确发布。
- 必须调用BeginParticipate方法参与至新的会话中,否则对方有可能会收不到自动回复的消息。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
DotNET与AD-基础 | 字痕随行
.NET Framework封装了用于操作AD的程序集,可以藉由此程序集查询、增加、修改、删除AD中的OU、User、Group等节点及其属性信息。
在VS2013中,新建一个项目,在项目中引用程序集“System.DirectoryServices”,即可在该项目中操作AD。如下图所示:
添加成功后,即可在该项目中通过代码操作指定的AD中的信息。
如果有问题,欢迎指正讨论。

觉的不错?可以关注我的公众号↑↑↑
DotNET与AD-名词解释 | 字痕随行
- NET是微软的新一代技术平台,为敏捷商务构建互联互通的应用系统,这些系统是基于标准的,联通的,适应变化的,稳定的和高性能的。从技术的角度,一个.NET应用是一个运行于.NET Framework之上的应用程序。
- ActiveDirectory:活动目录(Active Directory,简称AD)是面向Windows Standard Server、Windows Enterprise Server以及 Windows Datacenter Server的目录服务。Active Directory存储了有关网络对象的信息,并且让管理员和用户能够轻松地查找和使用这些信息。Active Directory使用了一种结构化的数据存储方式,并以此作为基础对目录信息进行合乎逻辑的分层组织。
- OU:OU(Organizational Unit,组织单位)是可以将用户、组、计算机和其它组织单位放入其中的AD(Active Directory,活动目录)容器,是可以指派组策略设置或委派管理权限的最小作用域或单元。通俗一点说,如果把AD比作一个公司的话,那么每个OU就是一个相对独立的部门。
- LDAP:LDAP是轻量目录访问协议,英文全称是Lightweight Directory Access Protocol,一般都简称为LDAP。
- .NET Framework:Microsoft .NET Framework是用于Windows的新托管代码编程模型。它强大功能与新技术结合起来,用于构建具有视觉上引人注目的用户体验的应用程序,实现跨技术边界的无缝通信,并且能支持各种业务流程。
- CLR:CLR是公共语言运行库,Common Language Runtime)和Java虚拟机一样也是一个运行时环境,它负责资源管理(内存分配和垃圾收集),并保证应用和底层操作系统之间必要的分离。CLR是.NET Framework的主要执行引擎。
- 程序集:经由编译器编译得到的,供CLR进一步编译执行的那个中间产物,在WINDOWS系统中,它一般表现为•dll或者是•exe的格式,但是要注意,它们跟普通意义上的WIN32可执行程序是完全不同的东西,程序集必须依靠CLR才能顺利执行。
- VS:即 Visual Studio 的英文缩写,是 Microsoft公司推出的一种软件开发平台。在计算机领域享誉盛名。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
DotNET与AD-常用属性 | 字痕随行
AD中节点为“User”类型的常用属性如下:
| 名称 | 说明 | 备注 |
|---|---|---|
| sAMAccountName | 用户登录名 | Windows2000前 |
| userPrincipalName | 用户登录名 | |
| userAccountControl | 帐户行为控制标志 | |
| cn | 公共名称 | 通常以此属性标识该用户,name的值相同 |
| name | 名称 | 通常以此属性标识该用户,同公共名称CN |
| sn | 姓 | |
| givenName | 名 | |
| displayName | 显示名称 | |
| 电子邮件 |
重要的公共属性如下:
| 名称 | 说明 | 备注 |
|---|---|---|
| objectGUID | ID | 主键标识 |
| objectClass | 类型 | person,user,organizationalUnit |
"userAccountControl"的对应值如下:
| 属性标志 | 十六进制值 | 十进制值 | 说明 |
|---|---|---|---|
| SCRIPT | 0x0001 | 1 | 将运行登录脚本 |
| ACCOUNTDISABLE | 0x0002 | 2 | 禁用用户帐户 |
| HOMEDIR_REQUIRED | 0x0008 | 8 | 需要主文件夹 |
| LOCKOUT | 0x0010 | 16 | |
| PASSWD_NOTREQD | 0x0020 | 32 | 不需要密码 |
| PASSWD_CANT_CHANGE | 0x0040 | 64 | 用户不能更改密码。可以读取此标志,但不能直接设置它 |
| ENCRYPTED_TEXT_PWD_ALLOWED | 0x0080 | 128 | 用户可以发送加密的密码 |
| TEMP_DUPLICATE_ACCOUNT | 0x0100 | 256 | 此帐户属于其主帐户位于另一个域中的用户。此帐户为用户提供访问该域的权限,但不提供访问信任该域的任何域的权限。有时将这种帐户称为“本地用户帐户”。 |
| NORMAL_ACCOUNT | 0x0200 | 512 | 这是表示典型用户的默认帐户类型 |
| INTERDOMAIN_TRUST_ACCOUNT | 0x0800 | 2048 | 对于信任其他域的系统域,此属性允许信任该系统域的帐户 |
| WORKSTATION_TRUST_ACCOUNT | 0x1000 | 4096 | 这是运行 Microsoft Windows NT 4.0 Workstation、Microsoft Windows NT 4.0 Server、Microsoft Windows 2000 Professional 或 Windows 2000 Server 并且属于该域的计算机的计算机帐户。 |
| SERVER_TRUST_ACCOUNT | 0x2000 | 8192 | 这是属于该域的域控制器的计算机帐户 |
| DONT_EXPIRE_PASSWORD | 0x10000 | 65536 | 表示在该帐户上永远不会过期的密码 |
| MNS_LOGON_ACCOUNT | 0x20000 | 131072 | 这是 MNS 登录帐户 |
| SMARTCARD_REQUIRED | 0x40000 | 262144 | 设置此标志后,将强制用户使用智能卡登录 |
| TRUSTED_FOR_DELEGATION | 0x80000 | 524288 | 设置此标志后,将信任运行服务的服务帐户(用户或计算机帐户)进行 Kerberos 委派。任何此类服务都可模拟请求该服务的客户端。若要允许服务进行 Kerberos 委派,必须在服务帐户的userAccountControl 属性上设置此标志 |
| NOT_DELEGATED | 0x100000 | 1048576 | 设置此标志后,即使将服务帐户设置为信任其进行 Kerberos 委派,也不会将用户的安全上下文委派给该服务 |
| USE_DES_KEY_ONLY | 0x200000 | 2097152 | (Windows 2000/Windows Server 2003) 将此用户限制为仅使用数据加密标准 (DES) 加密类型的密钥 |
| DONT_REQ_PREAUTH | 0x400000 | 4194304 | (Windows 2000/Windows Server 2003) 此帐户在登录时不需要进行 Kerberos 预先验证 |
| PASSWORD_EXPIRED | 0x800000 | 8388608 | (Windows 2000/Windows Server 2003) 用户的密码已过期 |
| TRUSTED_TO_AUTH_FOR_DELEGATION | 0x1000000 | 16777216 | (Windows 2000/Windows Server 2003) 允许该帐户进行委派。这是一个与安全相关的设置。应严格控制启用此选项的帐户。此设置允许该帐户运行的服务冒充客户端的身份,并作为该用户接受网络上其他远程服务器的身份验证 |
"userAccountControl"的属性标志是累计的,针对66050可以如下面一样解析: 66050=65536+512+2,分别表示“65536” - 密码永不过期,“512” - 用户状态正常,“2” - 用户被禁用。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
DotNET与AD-构建开发环境 | 字痕随行
本章将介绍如何快速构建.NET与AD相结合的开发环境,需要的必备条件有:
- 两台物理机:如果使用虚拟机,可以在一台物理机上同时安装,我使用的是VMware。
- Windows Server 2003安装镜像:综合来看,Win Server 2003的安装包最小,运行时耗费资源最低,同时提供的AD功能已经够用,足够应对各种与AD域相结合的开发需求。
- Winows操作系统安装镜像:我使用的是Windows 8.1。
- Microsoft Visual Studio安装镜像:我使用的是VS2013。
一切准备完毕后,就可以开始了。虚拟机的安装和使用不在本文范围内,只会在必要的时候提及,如何使用可以参考其它教程。构建开发环境分为以下几步:
- 安装Windows Server 2003。
- 安装AD目录服务。
- 安装Windows 8.1。
- 安装VS2013。
- 配置Windows 8.1网络连接。
- 验证
安装Windows Server 2003
启动虚拟机,选择“文件”->“新建虚拟机”,开启“新建虚拟机向导”,按照提示进行配置,如下图:
使用向导配置完成后,虚拟机会自动运行,并且启动Windows Server 2003安装程序,接下来只需要按提示输入初始信息即可完成安装。
安装AD目录服务
Windows Server 2003安装完成后,由开始菜单中打开“管理您的服务器”界面,如下图:

点击“添加或删除角色”,打开“配置您的服务器向导”界面,开始配置服务器,如下图:
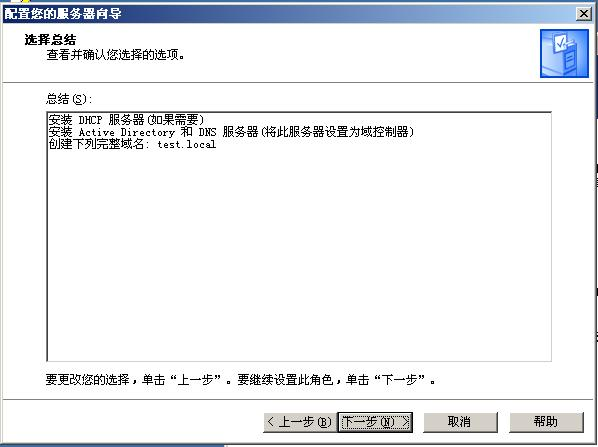
安装完成后自动重启,重启后进入服务器,会再继续执行安装过程,如下图:

点击下一步完成后,如果报无法配置转发器的错误,可以不用理会,至此AD目录服务安装完成,“管理您的服务器”界面会如下图所示:
安装Windows 8.1及VS2013
参照“安装Windows Server 2003”一节新建一台虚拟机,并安装Windows 8.1,安装完成后,更换“光盘镜像”,然后再安装VS2013。
配置Windows 8.1网络连接
首先要保证Windows Server 2003和Windows 8.1的网络处于同一个局域网内,查看Windows Server 2003的网络连接设置,之前在安装AD目录服务时,应该已经自动配置好,如下图:
在Windows 8.1中,参照以上信息进行配置,打开“网络和共享中心”,设置本地连接。打开“Internet协议版本4”属性设置,选择“使用下面的IP地址”,IP地址输入“10.10.1.2”,子网掩码输入“255.0.0.0”,默认网关置空;选择“使用下面的DNS服务器地址”,首选DNS服务器输入“10.10.1.1”。至此设置完毕。
验证
参见《连接与查询》章节。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
DotNET与AD-连接与查询 | 字痕随行
连接
如果要连接AD服务器,首先要知道LDAP地址,LDAP地址一般形如:LADP://xxx.com。可以使用下面的代码进行连接:
DirectoryEntry entry = new DirectoryEntry(
strLDAP,
strAdminUserName,
strAdminPwd,
AuthenticationTypes.Secure
);
其中,DirectoryEntry是封装Active Directory域服务层次结构中的节点或对象的类。
查询
成功连接服务器后,可以对AD中的节点进行查询,比如下面的代码就是搜索指定节点下所有的人员节点:
DirectoryEntry entry = new DirectoryEntry(strLDAP, strAdminUserName, strAdminPwd, AuthenticationTypes.Secure);
DirectorySearcher searcher = new DirectorySearcher(entry);
searcher.Filter = "(objectClass=user)";
searcher.SearchScope = SearchScope.Subtree;
earchResultCollection resultes = searcher.FindAll();
foreach (SearchResult result in resultes)
{
Response.Write(result.GetDirectoryEntry().Name + "");
}
在这里,最关键的是searcher的Filter属性,此属性相当于查询条件,限制了最终结果的范围,关于此属性的说明如下:
属性值
- 以 LDAP 格式表示的搜索筛选器,如“(objectClass=user)”。默认值为“(objectClass=*)”,它检索所有对象。
备注
- 筛选器遵循下列原则:
- 字符串必须括在括号内。
- 表达式可以使用关系运算符:<、<=、=、>= 和 >。例如:“(objectClass=user)”。再例如:“(lastName>=Davis)”。
- 复合表达式带有前缀运算符 & 和 |。例如:“(&(objectClass=user)(lastName= Davis))”。再例如:“(&(objectClass=printer)(|(building=42)(building=43)))”。
辅助工具“ADExplorer”
ADExplorer是一个先进的Active Directory(AD)查看器和编辑器。您可以使用ADExplorer轻松浏览的AD数据库。
可以在这个位置下载:http://technet.microsoft.com/en-us/sysinternals/bb963907.aspx
主要界面如下:
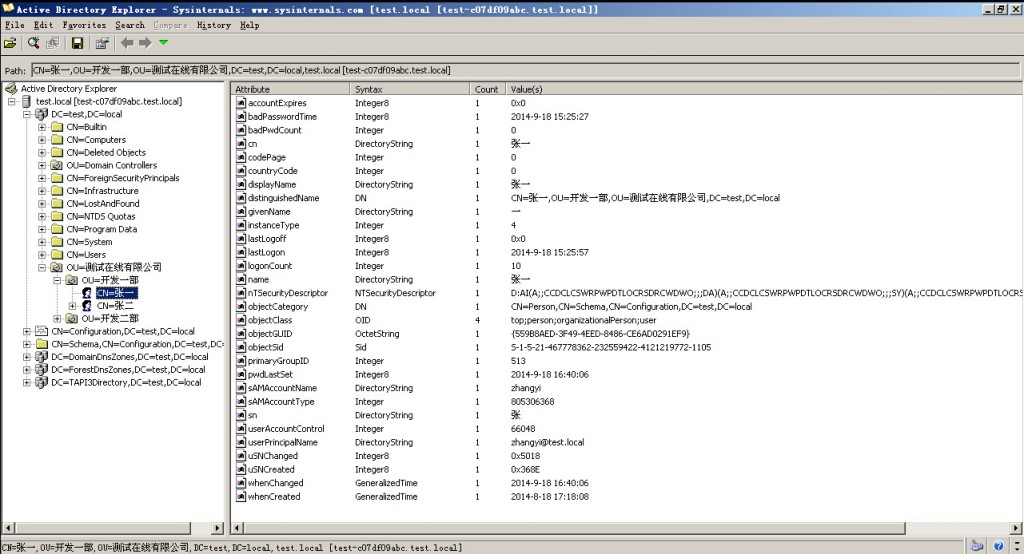
此软件最大的用途在于你可以查看任一节点所拥有的属性、可以方便的拼凑搜索筛选器的值,如下图所示:
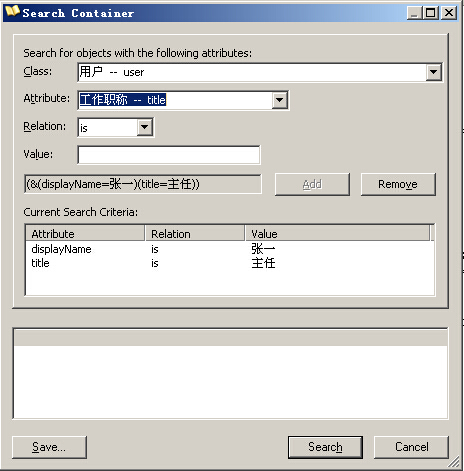
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
DotNET与AD-验证用户名和密码1 | 字痕随行
.NET与AD相结合,比较常用的有一种情况——用户登录验证。本章节就是用来说明一下验证输入凭证正确与否的方法。网络上流传较广的是如下方法:
DirectoryEntry entry = null;
try
{
entry = new DirectoryEntry(strLDAP, strUserName, strOldPwd, AuthenticationTypes.Secure);
object objID = entry.NativeGuid;
}
catch
{
this.lbError.Text = "输入的用户名或密码不正确";
return;
}
在一般情况下,这种登录验证方法是没有问题的,但是在用户密码过期的情况下,这种验证就会无法通过,会返回信息:“未知错误”或“无法操作服务器”。而有时候,我们会希望即使在密码过期的情况下,输入用户名和过期密码,验证也要通过,这时候就需要使用另外一种方法:
PrincipalContext context = new PrincipalContext(ContextType.Domain, strLDAP, strAdminUserName, strAdminPwd);
bool blIsValid = context.ValidateCredentials(strUserName, strOldPwd);
if (!blIsValid)
{
this.lbError.Text = "输入的用户名或密码不正确,修改失败";
return;
}
else
{
//凭证正确时的操作
}
PrincipalContext类属于命名空间System.DirectoryServices.AccountManagement,在使用此类之前,需要在项目中添加引用,如下图:
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
DotNET与AD-验证用户名和密码2 | 字痕随行
假设现在有一个需求:将AD中的人员名称定时同步至某个站点的数据库内,该站点非匿名访问,登录时需要进行域验证。
针对这个需求,需要至少一张数据库表(在此命名为TB_UserInfo),表结构设计如下:
| 字段名称 | 类型 | 备注 |
|---|---|---|
| UserID | varchar | 主键,用户ID,与AD中user的ID属性相同 |
| UserName | varchar | 用户名称,与AD中user的sAMAccountName属性相同 |
| DisplayName | Varchar | 用户显示名称,与AD中user的DisplayName属性相同 |
同步程序设计如下:
- 使用Windows Service或者桌面应用程序开发,安装至服务器后设置为开机自启动。
- 假设数据量在千条之内,则将AD中指定节点下的人员数据和数据库中表TB_UserInfo中的数据读取至内存集合(ADUserCollection和DBUserCollection)中,在数据库中更新属于ADUserCollectio且属于DBUserCollection的数据;在数据库中删除属于DBUserCollection但不属于ADUserCollection的数据;在数据库中新增属于ADUserCollection但不属于DBUserCollection的数据。
示例代码如下:
///
/// 人员信息
///
public class UserInfo
{
///
/// 人员ID
///
public string UserID { get ; set; }
///
/// 用户名
///
public string UserName { get; set; }
///
/// 显示名称
///
public string DisplayName { get; set; }
}
///
/// 为UserInfo自定义的比较类
///
public class UserInfoComparer : IEqualityComparer
{
public bool Equals(UserInfo x, UserInfo y)
{
return x.UserID == y.UserID;
}
public int GetHashCode(UserInfo userInfo)
{
return userInfo.UserID.GetHashCode();
}
}
///
/// 将活动目录中的人员信息同步至数据库
///
public void SynchronizationADUserToDB()
{
List lstADUser = GetUserFromAD();
List lstDBUser = GetUserFromDB();
//取得存在于DB中但不存在于AD中的人员集合
List lstImportUser =
lstDBUser.Except(lstADUser, new UserInfoComparer()).ToList();
foreach (UserInfo userInfo in lstImportUser)
{
DeleteUserToDB (userInfo);
}
//取得存在于AD中且存在于DB中的人员集合
lstImportUser
= lstADUser.Intersect(lstDBUser, new UserInfoComparer()).ToList();
foreach (UserInfo userInfo in lstImportUser)
{
UpdateUserToDB (userInfo);
lstADUser.Remove(userInfo);
}
//取得存在于AD中但不存在于DB中的人员集合
lstImportUser = lstADUser;
foreach (UserInfo userInfo in lstImportUser)
{
InsertUserToDB(userInfo);
}
}
站点的程序设计比较简单,只需要在登录时先验证人员是否存在于数据库中,然后再验证是否可以使用输入的凭证信息登录AD,示例代码如下:
//通过输入的账户信息验证是否存在于数据库中
//验证是否可以使用输入的账户信息登录AD
DirectoryEntry entry = null;
try
{
entry = new DirectoryEntry(
strLDAP, strUserName, strPWD, AuthenticationTypes.Secure);
object objID = entry.NativeGuid;
return true;
}
catch
{
return false;
}
//如果既存在于数据库同时也可以登录AD,则该用户为合法用户
至此,所假设的需求已经实现。如果AD内user数量巨大,最好不要使用此示例中所提供的导入方法,嵌套遍历会使效率极其低下。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
开启Exchange账户 | 字痕随行
原来做过一个项目,用网页来添加AD账号并开启Exchange2007邮箱账户。添加AD账户还比较轻松容易,但是开启Exchange账户的时候遇到了一些麻烦,最主要的是权限还有PowerShell的参数问题。
如何添加AD账户,网上一搜一大堆,基本就是那样,也不需要特殊的权限,只是每次声明DirectoryEntry时,需要带上具有与管理权限的用户。DirectoryEntry entry = new DirectoryEntry(LDAP,域管理员账号,域管理员密码,AuthenticationTypes.Secure);这里的域管理员账号最好是admin@xxx.com.cn这种格式的,如果不是这种格式的话,会报一个错误,不过这错误拿到网上一搜一大堆解决方案。
接下来就是开通Exchange2007账户了。因为Exchange2007开始微软开始使用PowerShell命令行来进行Exchange邮箱管理,我们必须运行脚本来进行账户开通和删除。
开始需要进行一些准备工作。需要准备一个账户,这个账户A要有两个权限,一个是Account Operators,另外一个是Exchange Recipient Administrators。第一个权限是为了管理域用户,第二个权限是为了管理Exchange2007。
然后还需要一个DLL文件,这个文件是用来运行PowerShell的,这个文件可以在C:\Program Files\Reference Assemblies\Microsoft\WindowsPowerShell\v1.0\System.Management.Automation.dll找到。前提是你安装了PowerShell。反正我电脑上有,如果你没有搜索吧。这样准备工作就完成了。
新建立一个web服务,这是因为运行Shell脚本的程序必须部署在exchange2007服务器上,否则的话会报错误。当然了你把这整个系统全都扔到exchange服务器上也没问题。
我开通账户用的是Enable-Mailbox这个命令,因为我已经在AD里面建好账户了。如果你需要这些命令的具体说明可以去MSDN上查看。
下面用C#运行这个命令的函数主体,你需要在工程里面引用上面所提到的那个DLL文件,下面的类基本上都是在这个DLL文件里面的。
RunspaceConfiguration runspaceConf = RunspaceConfiguration.Create();
PSSnapInException PSException = null;
PSSnapInInfo info = runspaceConf.AddPSSnapIn("Microsoft.Exchange.Management.PowerShell.Admin", out PSException);
Runspace runspace = RunspaceFactory.CreateRunspace(runspaceConf);
5. runspace.Open();
Pipeline pipeline = runspace.CreatePipeline();
Command command = new Command("Enable-Mailbox");
command.Parameters.Add("Identity", identity);//人员组织机构位置
command.Parameters.Add("Database", ConfigurationManager.AppSettings["MailDataBase"].Trim()); //Exchange数据库位置
pipeline.Commands.Add(command);
Collection result = pipeline.Invoke();
这个函数里面有一个需要注意的地方,也是我调试了半天才得出的结论,identity必须符合这样的“pyc.local/XXX/XX/人员的sn”格式,否则运行的时候它也不报错,就是建立不成功。
下面是删除的函数:
RunspaceConfiguration runspaceConf = RunspaceConfiguration.Create();
PSSnapInException PSException = null;
PSSnapInInfo info = runspaceConf.AddPSSnapIn("Microsoft.Exchange.Management.PowerShell.Admin", out PSException);
Runspace runspace = RunspaceFactory.CreateRunspace(runspaceConf);
runspace.Open();
Pipeline pipeline = runspace.CreatePipeline();
Command command = new Command("Remove-Mailbox");
command.Parameters.Add("Identity", identity);
command.Parameters.Add("Confirm", false);//添加此参数以防止出现Cannot invoke this function because the current host does not implement it
pipeline.Commands.Add(command);
Collection result = pipeline.Invoke();
这个函数的identity可以是别名,可以是人员唯一的登录名,这个可以去MSDN上查看。一定要添加confirm这个参数,并且值是false,否则就是报上面注释的错误。
这样删除和开通的函数就有了,现在需要把它部署到exchang服务器上去,这时候我们就需要用到上面建立的账号A了。
在IIS里面新建一个网站,新建一个程序池,这个新建网站在新建立的程序池上运行。程序池的属性->标示选择配置,输入A账户名和密码。这样我们运行这个web服务使用的就是A账户,而A账户拥有操作AD和Exchange的权限,就能顺利的运行操作命令了。
基本上到此程序就能够跑通了,当时,我在这短短的几行代码上花费了3天,因为基本上这些问题都没有中文的资料,还是老外牛奔啊,不过讨论的也比较少,在我连蒙带猜带用我二把刀英文外带使劲google的情况下终于让我跑通了这个程序,真不容易,再次记录,希望以后少走弯路。
如果有问题,欢迎指正讨论。
觉的不错?可以关注我的公众号↑↑↑
哦| 字痕随行

哦,从头说起吧,老实说我并不能算上老玩家,我在开服的那天并没有登入游戏,事实上我那时候还在沉迷于一款叫做《华夏》的游戏。虽然我不曾进入游戏,不过身边的先行者已经向我充分展示了它的魅力。终于在两天后的刷夜生活中,我踏上了这片神奇的土地。
不可思议,那时的我竟然喜欢矮人这个种族,再加上片头动画的影响,于是我顺理成章的成为了一名猎人,而从这一刻我的猎人情节开始发挥起作用,这在后面的历程中可见一斑。
看着口中呼出的白气,我费力的晃动着屏幕,看向远处的雪山,看向苍白的天空,看着白茫茫的大地,就这样“霜伤”诞生了。
事实上我并没有想象中的那么激动,我只是走上前去接了个任务,就开始游荡于初始的怪堆之中。那时候真是人山人海,导致我想虐待一条小狼都要千辛万苦手疾眼快,这是一种什么精神。
当我看见大耳朵暗夜精灵时,我赞叹道苗条啊,实际上这个暗夜精灵已经18级了,而她还在快乐的做着1级的任务。那时候的人们都很天真,就如大眼睛侏儒法师总是用匕首砍怪。
在那一晚上我升了8级,在现在看来这可真慢,可是在那时我觉得非常快,而我在这一晚过后,就融入了这个世界,从此就是10年。

要包包吗?
那是个午夜,我自从有了宠物后,非常happy的在矮人挖掘场里面敲怪。四周静谧,天空中的圆月散发清冷的光辉,白雪皑皑,我很喜欢这样的感觉。我不得不多说一下,我很喜欢丹莫洛和冬泉谷,这两个地方的雪让我有一种安静的感觉。
在我暗暗高兴,砍怪砍的无比兴奋的时候,一个大眼睛侏儒术士跑过来,“要包包吗?只需要几组亚麻布!”,我注视着侏儒,看着他在那里一摇一晃,接着我交易了几组亚麻布过去,于是我空余的包位上首次被占满,侏儒向我打了声招呼就跑向远方。
我注视着他,一个术士,小小的身影,然后打量身上的亚麻包,虽然比起现在动辄就20格的包显得微不足道,但是当时我确实很高兴,终于不用往外面扔东西了,那种肉疼,简直不是一般的痛苦。
就这样,我度过了一个愉快的夜晚,我很高兴在那个夜晚遇到这个大眼睛可爱侏儒,当晚的这幕也深深藏入记忆。
破裂的天空
5月1日,放假了,我回到家,在我的PIII1G+512M内存+32M显卡上安装了魔兽世界,然后迫不及待的进入,草绿的,人模糊地,一切都很正常,可是当我望向天空的时候,我惊呆了,这破裂的天空,五彩斑斓,于是在这之后的一段时间里面我再也没有欣赏天空的月色,恁谁看到这样的天空都有一种崩溃的感觉。
我来到了洛克莫丹,看到了洛克湖,这里也是人山人海,矮人侏儒人类,也许唯一少见的就是精灵了,也是,他们在海那边。
我为了一把白色的猎枪而努力,我一银币一银币的攒着钱,每次当我回到旅馆我总是垂涎于这把猎枪,虽然它只是个白色的物品,可是要知道它比我手中的灰色物品好多了,那是一种什么心情。
反正我总是徘徊在商人那里,几银币对于我来说就像登天那么麻烦,直到多年以后,我再回到洛克莫丹我总想起这个时候的往事。
孤独的渔者
我在水中游着,还好我没有恐水症,也不会像一些人不会控制上浮,至少我淹不死自己,这点让我很高兴,发现我真有玩这游戏的天赋。
我从一个稍微平缓的浅滩上岸,这时我发现一个矮人在钓鱼,而陪伴他的是一头狼,他生死不离的宠物。
“能钓到鱼吗?”,我问。
“当然,小声点,别吓跑了鱼!”
于是我噤若寒蝉似的在旁边张望,这一切那么的寂静和谐。
当我现在回想起来,我还是有一种莫名的感动,在这静谧的夜晚,一位渔者在他的宠物陪伴下,快乐的享受钓鱼的乐趣。
我们离真正的快乐越来越远。就像我上高中时从来没有真正的快乐过,只有考到理想的成绩和名次才能稍微微笑。
我也不知道这是为什么,当我们追求一件事的时候,我们总是很容易偏离正常的轨道,然后在遥远的后来才想起当初那份单纯的感动和快乐。
也许我也应该拿起鱼竿带着我的小宠物找一片阴凉享受难得的快乐。

圣骑士与鳄鱼
回忆飘向远方,我突然记起我是如何得知可以学习专业技能的。
又是个夜晚,没办法,我比较喜欢艾泽拉斯的夜晚,静谧神秘。
我一个人在洛克湖中心的岛上击杀鳄鱼,看着经验条蹭蹭的向前涨,我异常快乐,人生啊,还有比这更快乐的事情吗?
这时候一个圣骑士游上岛来,不打怪,也不是路过,而是不停地在冲着鳄鱼尸体做手势,然后鳄鱼就消失了,我惊为天人,此人使得何种魔法。
“你在干什么?”
“剥皮”
“这皮还能剥?”
“当然,这是技能”
“我能学吗?”
“铁炉堡”
那时候的人还是都说全称的,于是我屁颠屁颠的赶往铁炉堡,第一次学会了人物的两个专业技能,剥皮和制皮。 然后,我发现击杀动物是如此的快乐,人生啊,还有比这更快乐的事情吗?
山寨部落
我悠哉悠哉的游荡于洛克莫丹,这地方真不错,有山有水有美女,让我这个矮子猎欣喜异常。
突然,从侧方冲出三个牛头,是牛头,我清晰的记得,也许可能,反正我没有刚住,就很愉快的到底了,当我死不瞑目的刹那,我看到了部落的图标。他喵的,这不是PVE服务器吗?我怎么会被PK,人生啊,还有比这更痛苦的事情吗?
于是,我很大声很不愤的在综合频道发送信息,“这地方为什么会有部落?为什么还能打我?”
“就是,我也被打”
……
看来不止我一个人。
“那是NPC,不是玩家。”
一句话道破事实真相,他喵的,哪来的这么高的NPC,而且还在这里乱窜。
只有我的矮子猎遭受过如此待遇,多年以后我才隐约知道,这是定时刷的,我曾专门寻找其报仇,当然,结果很明显,报仇未果。
那么,你碰到过吗?我的朋友。
巨石水坝
我记不起来我什么时候知道巨石水坝真面目的,不过我知道当我看到这座水坝的真面目的时候,我很庆幸我拯救了这座墙。
我跑到水坝之上,这里视野很开阔,不过鉴于当时我电脑的配置,我眼中也就只有那水还凑合,不过还是一片黑水。
我跑上跑下,千辛万苦的做了精英任务,然后又跑到远在湿地边缘的黑矮人营地,累的半死,完成了这个超长的任务线,毁坏了黑矮人的炸弹,最后的结果我很欣慰,他说我拯救了巨石水坝(他喵的,被死亡之翼给毁了,最壮观最雄伟的地方,我对这位环境破坏者很有意见,活该被推),我和我的队友们泪流满面,这任务真长真累人。
说实在的,我不认为这个记忆很清晰,但是我在此写出来主要是为了纪念那个时代,纪念那晚所遇到的所有队友。
那是我最长的一次组队,那也是对我洛克莫丹的收尾。


觉的不错?可以关注我的公众号↑↑↑
雾蒙蒙、湿漉漉 | 字痕随行
米奈希尔港
二十级的时候终于来到了米奈希尔港,当时的港口很美丽,我是夜晚到达的,站在港口的木质地板上欣赏着远方的月光,内心是如此平静,从此养成了习惯,喜欢在米奈希尔背靠月亮留下一张特写。
港口的酒馆给人的感觉就是充满了水手的汗臭味,充满了喧嚣,但是悠扬的小调吹散了身上的疲惫。这里有矮人的美酒,同时也有美味的奶酪,还掺杂了人类特有的烹饪手法,让人流连忘返。二层的隔间供人能够短暂休息,那床看起来还算柔软,冒险者就不要讲究卫生了,和衣而睡吧,至少不用担心野外的猛兽了。
当时,这是我经历的第一间最像旅店的旅店,矮人们那边的旅馆更像是喝酒的酒馆,而这里真的能够提供短暂的休息,我惊叹于设计师的功力,我从未在之前的任何游戏里见到过如此逼真,能够让人身临其境的场所。当时被WOW又一次震动了。
美丽的月光下,孤独的水手唱着歌,他在悼念死去而不能安息的队友吗?
旅馆后搁浅的沉船已经被鱼人占领,是否还有需要交代的往事?
堡垒在凝望着远方,它在守护着什么?
来来往往的渡船,将一队队陌生的冒险者带向何方?
匆匆过往的人们将会在未来谱写何样的篇章?

鱼人与迅猛龙
经历过那个人山人海年代的人,总是对两个物种记忆犹新,甚至于充满恐惧。一种就是子哇乱叫的鱼人,另外一种就是漫山遍野的迅猛龙。
先说说鱼人吧,我很好奇这种东西是怎么被造出来,滑腻的皮肤遮掩不了那一双滴溜乱转的双眼,两条强健有力的双腿促使他们能够追杀任何物种,同时扰人心智的怪音让你只顾闷头跑路,最关键的是这帮孙子是群居的,于是死亡不可避免。
米奈希尔港门口就有一片这种鱼人,米奈希尔港的重要任务线之一就是围着这帮鱼人展开。即使当时人再多,那也有被这帮家伙追的抱头乱窜的一幕,而且这一幕一幕发生在大多数冒险者身上。当时鱼人的头颅还滴答汤,看着包裹里面的一打头颅,心中一片恶寒。苦于任务十分稀少,在二十二级之前都是靠刷这种怪物而度过的,同时也伴随着恐慌,现在想起来仍旧恶寒不已。
米奈希尔港的另外一个重要任务线是围绕着迅猛龙展开的,你会觉得侏罗纪公园真是哪里都有,虚拟的NPC也会因为各种意外而被这帮动物围攻。至少,恐龙这个玩意并不陌生(克赛,前来拜访,哈哈),再一个,没有鱼人那种滑腻让人恶心的感觉。我这矮子猎人很想抓个迅猛龙当宠物,可惜当时还是不能如愿,只能一头扎进挖掘场,使用我那劣质火枪驱赶这群不速之客。于是,在这月圆之夜,在一个一个土堆之间,一个矮人上蹿下跳,旁边的宝贝宠物熊慢悠悠的顶上去退回来,似乎也是一副和谐的画面,不和谐的是,杀了还要剥皮,幸好剥完了不会留下一幅幅枯骨。
恐龙和鱼人在低级别地图也算大户,至今仍旧游荡在那里,只是少了那份喧嚣,多了一份宁静。其实任何东西总会经历繁荣,然后趋于平静,而平静也许才是不变的主题。
接不到的任务
湿地任务的尾声发生在萨尔多大桥,这里充斥了黑铁矮人,60级的时候这里的任务怪都是精英,我们需要小心翼翼的行进,对于一个孤独的猎人来说,这里更是相当难混。
今天讲述的重点并不是这群黑铁矮人,而是那该死的的任务叹号,你看着那个金黄色的叹号明明就在那里,可是就是接不到,甚至于还要冒着摔死的危险一遍一遍的尝试。
这个任务的具体位置是在一个桥墩子上面,我觉的萨尔多大桥应该是双向六车道的,可是由于黑铁矮人的入侵,炸毁了一半,所以那边只剩个桥墩孤零零的竖立在那里,关键就在这里,前不着村后不着店的桥墩子上面有个任务,从远处看是个矮人,脑袋上顶个充满诱惑力的金色叹号,不停的勾引着我:来吧,过来就给你任务!
于是,我就像条狗一样,先是跳起来摔下去,然后爬上来接着跳,如此反复。可是苍天啊,我就是跳不过去啊,臣妾真的做不到啊,我去年买了个表。
我为了这个任务磨洋工磨了整整一个下午啊,最后的结果显而易见,就是过不去,后来只能故作潇洒的挥挥手,爷去也。
多年以后,闲来无事,终于滚到了上面,我发现这个需要运气的,开个豹守边缘起跳,运气好还是能跳过去的,也算是了却了一桩心愿。现在回想起来,我就记得那光灿灿的金黄色大叹号,也算茶前饭后的一份谈资。
觉的不错?可以关注我的公众号↑↑↑